

It is a visitor submit by Kevin Chun, Workers Software program Engineer in Core Engineering at NerdWallet.
NerdWallet’s mission is to supply readability for all of life’s monetary selections. This covers a various set of subjects: from selecting the best bank card, to managing your spending, to discovering the most effective private mortgage, to refinancing your mortgage. Because of this, NerdWallet provides highly effective capabilities that span throughout quite a few domains, resembling credit score monitoring and alerting, dashboards for monitoring web value and money circulation, machine studying (ML)-driven suggestions, and lots of extra for hundreds of thousands of customers.
To construct a cohesive and performant expertise for our customers, we want to have the ability to use massive volumes of various consumer knowledge sourced by a number of unbiased groups. This requires a powerful knowledge tradition together with a set of knowledge infrastructure and self-serve tooling that allows creativity and collaboration.
On this submit, we define a use case that demonstrates how NerdWallet is scaling its knowledge ecosystem by constructing a serverless pipeline that allows streaming knowledge from throughout the corporate. We iterated on two totally different architectures. We clarify the challenges we bumped into with the preliminary design and the advantages we achieved through the use of Apache Hudi and extra AWS companies within the second design.
Downside assertion
NerdWallet captures a large quantity of spending knowledge. This knowledge is used to construct useful dashboards and actionable insights for customers. The info is saved in an Amazon Aurora cluster. Though the Aurora cluster works properly as an On-line Transaction Processing (OLTP) engine, it’s not appropriate for giant, advanced On-line Analytical Processing (OLAP) queries. Because of this, we are able to’t expose direct database entry to analysts and knowledge engineers. The info homeowners have to resolve requests with new knowledge derivations on learn replicas. As the information quantity and the range of knowledge customers and requests develop, this course of will get tougher to keep up. As well as, knowledge scientists principally require knowledge recordsdata entry from an object retailer like Amazon Easy Storage Service (Amazon S3).
We determined to discover alternate options the place all customers can independently fulfill their very own knowledge requests safely and scalably utilizing open-standard tooling and protocols. Drawing inspiration from the knowledge mesh paradigm, we designed a knowledge lake based mostly on Amazon S3 that decouples knowledge producers from customers whereas offering a self-serve, security-compliant, and scalable set of tooling that’s straightforward to provision.
Preliminary design
The next diagram illustrates the structure of the preliminary design.

The design included the next key parts:
- We selected AWS Knowledge Migration Service (AWS DMS) as a result of it’s a managed service that facilitates the motion of knowledge from varied knowledge shops resembling relational and NoSQL databases into Amazon S3. AWS DMS permits one-time migration and ongoing replication with change knowledge seize (CDC) to maintain the supply and goal knowledge shops in sync.
- We selected Amazon S3 as the inspiration for our knowledge lake due to its scalability, sturdiness, and adaptability. You possibly can seamlessly enhance storage from gigabytes to petabytes, paying just for what you utilize. It’s designed to supply 11 9s of sturdiness. It helps structured, semi-structured, and unstructured knowledge, and has native integration with a broad portfolio of AWS companies.
- AWS Glue is a totally managed knowledge integration service. AWS Glue makes it simpler to categorize, clear, rework, and reliably switch knowledge between totally different knowledge shops.
- Amazon Athena is a serverless interactive question engine that makes it straightforward to investigate knowledge straight in Amazon S3 utilizing commonplace SQL. Athena scales robotically—operating queries in parallel—so outcomes are quick, even with massive datasets, excessive concurrency, and sophisticated queries.
This structure works effective with small testing datasets. Nonetheless, the workforce shortly bumped into issues with the manufacturing datasets at scale.
Challenges
The workforce encountered the next challenges:
- Lengthy batch processing time and complexed transformation logic – A single run of the Spark batch job took 2–3 hours to finish, and we ended up getting a reasonably large AWS invoice when testing in opposition to billions of information. The core downside was that we needed to reconstruct the newest state and rewrite the complete set of information per partition for each job run, even when the incremental adjustments had been a single report of the partition. Once we scaled that to hundreds of distinctive transactions per second, we shortly noticed the degradation in transformation efficiency.
- Elevated complexity with a lot of purchasers – This workload contained hundreds of thousands of purchasers, and one frequent question sample was to filter by single consumer ID. There have been quite a few optimizations that we had been compelled to tack on, resembling predicate pushdowns, tuning the Parquet file dimension, utilizing a bucketed partition scheme, and extra. As extra knowledge homeowners adopted this structure, we must customise every of those optimizations for his or her knowledge fashions and client question patterns.
- Restricted extendibility for real-time use circumstances – This batch extract, rework, and cargo (ETL) structure wasn’t going to scale to deal with hourly updates of hundreds of information upserts per second. As well as, it might be difficult for the information platform workforce to maintain up with the varied real-time analytical wants. Incremental queries, time-travel queries, improved latency, and so forth would require heavy funding over an extended time frame. Enhancing on this difficulty would open up prospects like near-real-time ML inference and event-based alerting.
With all these limitations of the preliminary design, we determined to go all-in on an actual incremental processing framework.
Resolution
The next diagram illustrates our up to date design. To assist real-time use circumstances, we added Amazon Kinesis Knowledge Streams, AWS Lambda, Amazon Kinesis Knowledge Firehose and Amazon Easy Notification Service (Amazon SNS) into the structure.
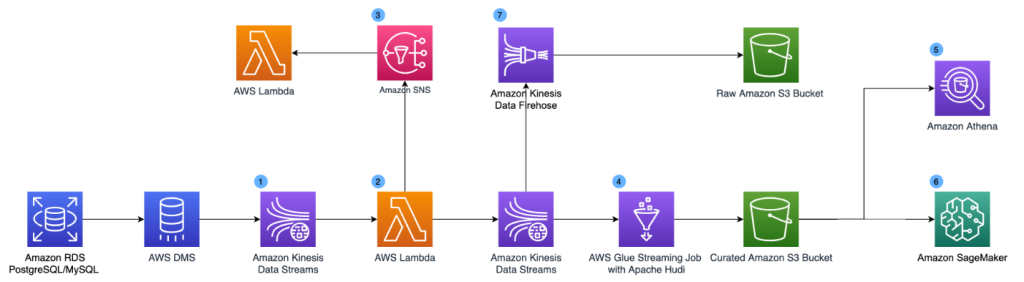
The up to date parts are as follows:
- Amazon Kinesis Knowledge Streams is a serverless streaming knowledge service that makes it straightforward to seize, course of, and retailer knowledge streams. We arrange a Kinesis knowledge stream as a goal for AWS DMS. The info stream collects the CDC logs.
- We use a Lambda operate to rework the CDC information. We apply schema validation and knowledge enrichment on the report degree within the Lambda operate. The reworked outcomes are printed to a second Kinesis knowledge stream for the information lake consumption and an Amazon SNS matter in order that adjustments will be fanned out to numerous downstream techniques.
- Downstream techniques can subscribe to the Amazon SNS matter and take real-time actions (inside seconds) based mostly on the CDC logs. This could assist use circumstances like anomaly detection and event-based alerting.
- To unravel the issue of lengthy batch processing time, we use Apache Hudi file format to retailer the information and carry out streaming ETL utilizing AWS Glue streaming jobs. Apache Hudi is an open-source transactional knowledge lake framework that tremendously simplifies incremental knowledge processing and knowledge pipeline growth. Hudi permits you to construct streaming knowledge lakes with incremental knowledge pipelines, with assist for transactions, record-level updates, and deletes on knowledge saved in knowledge lakes. Hudi integrates properly with varied AWS analytics companies resembling AWS Glue, Amazon EMR, and Athena, which makes it a simple extension of our earlier structure. Whereas Apache Hudi solves the record-level replace and delete challenges, AWS Glue streaming jobs convert the long-running batch transformations into low-latency micro-batch transformations. We use the AWS Glue Connector for Apache Hudi to import the Apache Hudi dependencies within the AWS Glue streaming job and write reworked knowledge to Amazon S3 constantly. Hudi does all of the heavy lifting of record-level upserts, whereas we merely configure the author and rework the information into Hudi Copy-on-Write desk sort. With Hudi on AWS Glue streaming jobs, we cut back the information freshness latency for our core datasets from hours to underneath quarter-hour.
- To unravel the partition challenges for prime cardinality UUIDs, we use the bucketing method. Bucketing teams knowledge based mostly on particular columns collectively inside a single partition. These columns are referred to as bucket keys. Once you group associated knowledge collectively right into a single bucket (a file inside a partition), you considerably cut back the quantity of knowledge scanned by Athena, thereby bettering question efficiency and lowering value. Our present queries are filtered on the consumer ID already, so we considerably enhance the efficiency of our Athena utilization with out having to rewrite queries through the use of bucketed consumer IDs because the partition scheme. For instance, the next code reveals whole spending per consumer in particular classes:
- Our knowledge scientist workforce can entry the dataset and carry out ML mannequin coaching utilizing Amazon SageMaker.
- We preserve a duplicate of the uncooked CDC logs in Amazon S3 by way of Amazon Kinesis Knowledge Firehose.
Conclusion
Ultimately, we landed on a serverless stream processing structure that may scale to hundreds of writes per second inside minutes of freshness on our knowledge lakes. We’ve rolled out to our first high-volume workforce! At our present scale, the Hudi job is processing roughly 1.75 MiB per second per AWS Glue employee, which might robotically scale up and down (due to AWS Glue auto scaling). We’ve additionally noticed an excellent enchancment of end-to-end freshness at lower than 5 minutes resulting from Hudi’s incremental upserts vs. our first try.
With Hudi on Amazon S3, we’ve constructed a high-leverage basis to personalize our customers’ experiences. Groups that personal knowledge can now share their knowledge throughout the group with reliability and efficiency traits constructed right into a cookie-cutter resolution. This permits our knowledge customers to construct extra subtle alerts to supply readability for all of life’s monetary selections.
We hope that this submit will encourage your group to construct a real-time analytics platform utilizing serverless applied sciences to speed up your online business objectives.
Concerning the authors
 Kevin Chun is a Workers Software program Engineer in Core Engineering at NerdWallet. He builds knowledge infrastructure and tooling to assist NerdWallet present readability for all of life’s monetary selections.
Kevin Chun is a Workers Software program Engineer in Core Engineering at NerdWallet. He builds knowledge infrastructure and tooling to assist NerdWallet present readability for all of life’s monetary selections.
 Dylan Qu is a Specialist Options Architect centered on massive knowledge and analytics with Amazon Net Providers. He helps prospects architect and construct extremely scalable, performant, and safe cloud-based options on AWS.
Dylan Qu is a Specialist Options Architect centered on massive knowledge and analytics with Amazon Net Providers. He helps prospects architect and construct extremely scalable, performant, and safe cloud-based options on AWS.

{kind=link}