

This submit was co-written by Ashish Prabhu, Stephen Johnston, and Colin Ingarfield at Morningstar and Don Drake, at AWS.
With “Empowering Investor Success” because the core motto, Morningstar goals at offering our buyers and advisors with the instruments and data they should make knowledgeable funding selections.
On this submit, Morningstar’s Information Lake Crew Leads talk about how they utilized tag-based entry management of their knowledge lake with AWS Lake Formation and enabled comparable controls in Amazon Redshift.
The enterprise problem
At Morningstar, we constructed an information lake resolution that permits our customers to simply ingest knowledge, make it accessible through the AWS Glue Information Catalog, and grant entry to customers to question the info through Amazon Athena. On this resolution, we have been required to make sure that the customers might solely question the info to which they’d express entry. To implement our entry permissions, we selected Lake Formation tag-based entry management (TBAC). TBAC helps us categorize the info right into a easy, broad degree or a fancy, extra granular degree utilizing tags after which grant customers entry to these tags based mostly on what group of information they want. Tag-based entitlements permit us to have a versatile and manageable entitlements system that solves our advanced entitlements eventualities.
Nonetheless, our customers pushed us for higher question efficiency and enhanced analytical capabilities. We realized we wanted an information warehouse to cater to all of those shopper necessities, so we evaluated Amazon Redshift. Amazon Redshift supplies us with options that we might use to work with our customers and allow their analytical necessities:
- Higher efficiency for customers’ analytical necessities
- Capacity to tune question efficiency with user-specified kind keys and distribution keys
- Capacity to have completely different representations of the identical knowledge through views and materialized views
- Constant question efficiency no matter concurrency
Many new Amazon Redshift options helped resolve and scale our analytical question necessities, particularly Amazon Redshift Serverless and Amazon Redshift knowledge sharing.
As a result of our Lake Formation-enforced knowledge lake is a central knowledge repository for all our knowledge, it is sensible for us to circulate the info permissions from the info lake into Amazon Redshift. We make the most of AWS Identification and Entry Administration (IAM) authentication and need to centralize the governance of permissions based mostly on IAM roles and teams. For every AWS Glue database and desk, we have now a corresponding Amazon Redshift schema and desk. Our objective was to make sure clients who’ve entry to AWS Glue tables through Lake Formation even have entry to the corresponding tables in Amazon Redshift.
Nonetheless, we confronted an issue with user-based entitlements as we moved to Amazon Redshift.
The entitlements downside
Despite the fact that we added Amazon Redshift as a part of our general resolution, the entitlement necessities and challenges that got here with it remained the identical for our customers consuming through Lake Formation. On the similar time, we needed to discover a approach to implement entitlements in our Amazon Redshift knowledge warehouse with the identical set of tags that we had already outlined in Lake Formation. Amazon Redshift helps resource-based entitlements however doesn’t assist tag-based entitlements. The problem we needed to overcome was map our present tag-based entitlements in Lake Formation to the resource-based entitlements in Amazon Redshift.
The information within the AWS Glue Information Catalog wanted to be additionally loaded within the Amazon Redshift knowledge warehouse native tables. This was essential in order that the customers get a well-recognized checklist of schema and tables that they’re accustomed to seeing within the Information Catalog when accessing through Athena. This fashion, our present knowledge lake customers might simply transition to Amazon Redshift.
The next diagram illustrates the construction of the AWS Glue Information Catalog mapped 1:1 with the construction of our Amazon Redshift knowledge warehouse.

We wished to make the most of the ontology of tags in Lake Formation to even be used on the datasets in Amazon Redshift so that buyers could possibly be granted entry to the identical datasets in each locations. This enabled us to have a single entitlement coverage supply API that may grant applicable entry to each our Amazon Redshift tables in addition to the corresponding Lake Formation tables based mostly on the Lake Formation tag-based insurance policies.
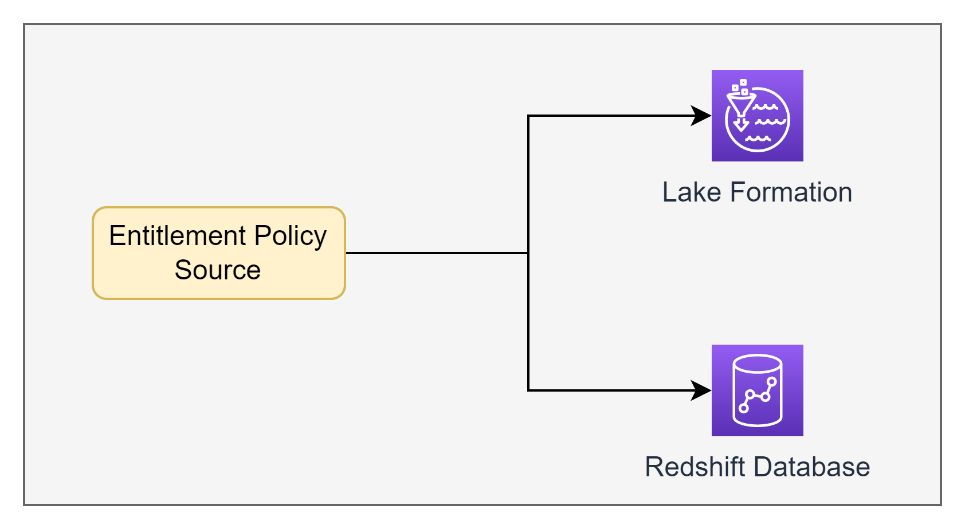
To unravel this downside, we wanted to construct our personal resolution to transform the tag-based insurance policies in Lake Formation into grants and revokes within the resource-based entitlements in Amazon Redshift.
Resolution overview
To unravel this mismatch, we wished to synchronize our Lake Formation tag ontology and classifications to the Amazon Redshift permission mannequin. To do that, we map Lake Formation tags and grants to Amazon Redshift grants with the next steps:
- Map all of the sources (databases, schemas, tables, and extra) in Lake Formation which can be tagged to their equal Amazon Redshift tables.
- Translate every coverage in Lake Formation on a tag expression to a set of Amazon Redshift desk grants and revokes.
The online result’s that when there’s a tag or coverage change in Lake Formation, a corresponding set of grants or revokes are made to the equal Amazon Redshift tables to maintain our entitlements in sync.
Map all tagged sources in Lake Formation to Amazon Redshift equivalents
The tag-based entry management of Lake Formation allowed us to use a number of tags on a single useful resource (database and desk) within the AWS Glue Information Catalog. If visualized in a mapping kind, the useful resource tagging will be displayed as how a number of tags on a single desk could be flattened into particular person entitlements on Amazon Redshift tables.
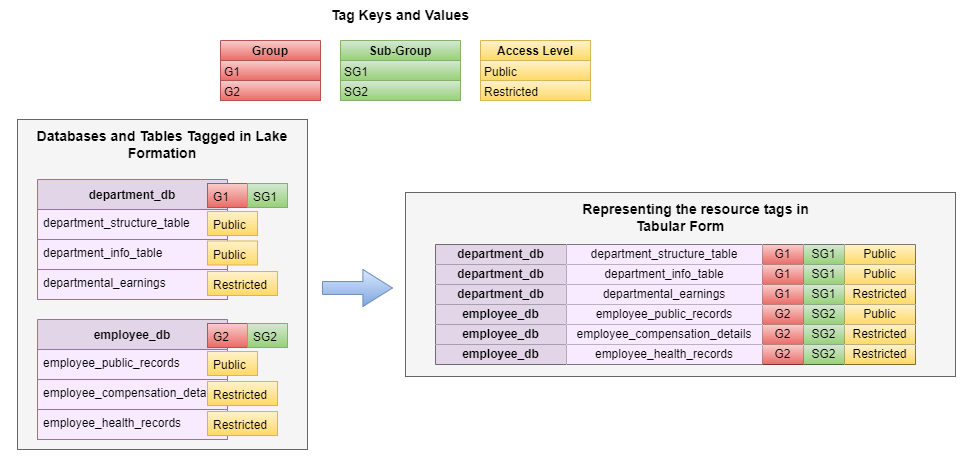
Translate tags to Amazon Redshift grants and revokes
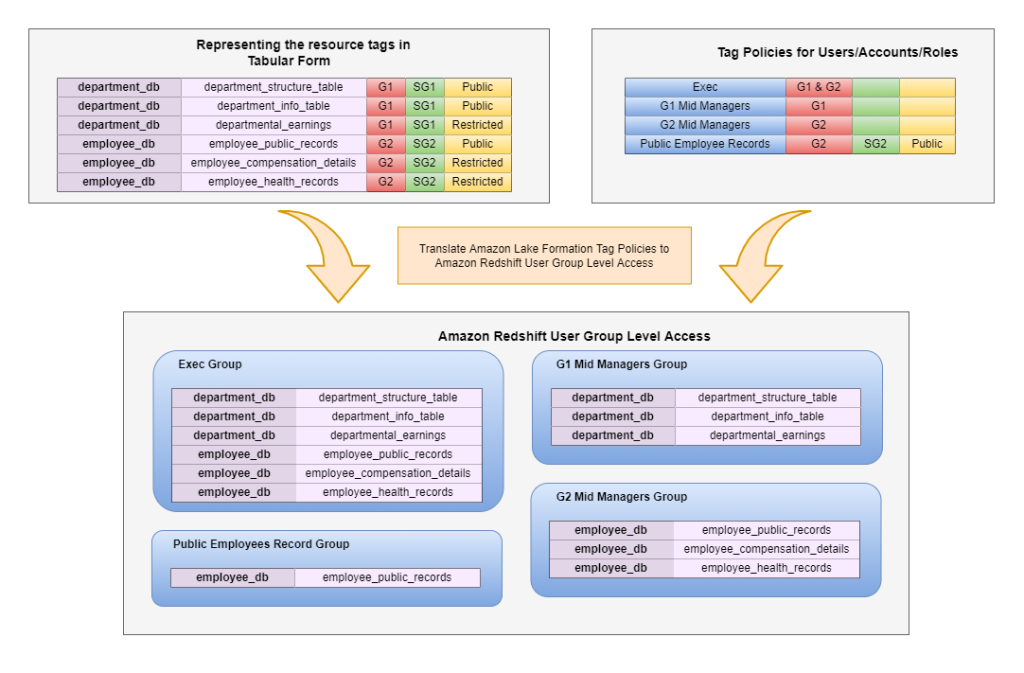
To allow the migration of the tag-based coverage enforced in Lake Formation, the permissions will be transformed into easy grants and revokes that may be completed on a per-group degree.
There are two basic elements to a tag coverage: the principal_id and the tag expression (for instance, “Acess Stage” = “Public”). Assuming that we have now an Amazon Redshift database group for every principal_id, then the sources that characterize the tag expression will be permissioned accordingly. We plan on migrating from database teams to database roles in a future implementation.
The answer implementation
The implementation of this resolution led us to develop two elements:
- The mapper service
- The Amazon Redshift knowledge configuration
The mapper service will be considered a translation service. Because the identify suggests, it has the core enterprise logic to map the tag and coverage info into resource-based grants and revokes in Amazon Redshift. It must mimic the conduct of Lake Formation when dealing with the tag coverage translation.
To do that translation, the mapper wants to know and retailer the metadata at two ranges:
- Understanding what useful resource in Amazon Redshift is to be tagged with what worth
- Monitoring the grants and revokes already carried out to allow them to be up to date with adjustments within the coverage
To do that, we created a config schema in our Amazon Redshift cluster, which at the moment shops all of the configurations.
As a part of our implementation, we retailer the mapped (translated) info in Amazon Redshift. This enables us to incrementally replace desk grants as Lake Formation tags or insurance policies modified. The next diagram illustrates this schema.

Enterprise influence and worth
The answer we put collectively has created key enterprise impacts and values out of the present implementation and permits us higher flexibility sooner or later.
It permits us to get the info to our customers quicker with the tag insurance policies utilized in Lake Formation and translated on to permissions in Amazon Redshift with speedy impact. It additionally permits us to have consistency in permissions utilized in each Lake Formation and Amazon Redshift, based mostly on the efficient permissions derived from tag insurance policies. And all this occurs through a single supply that grants and revokes permissions throughout the board, as a substitute of managing them individually.
If we translate this into the enterprise influence and enterprise worth that we generate, the answer improves the time to market of our knowledge, however on the similar time supplies constant entitlements throughout the business-driven classes that we outline as tags.
The answer additionally opens up options so as to add extra influence as our product scales each horizontally and vertically. There are potential options we might implement by way of automation, customers self-servicing their permissions, auditing, dashboards, and extra. As our enterprise scales, we anticipate to reap the benefits of these capabilities.
Conclusion
On this submit, we shared how Morningstar utilized tag-based entry management in our knowledge lake with Lake Formation and enabled comparable controls in Amazon Redshift. We developed two elements that deal with mapping of the tag-based entry controls to Amazon Redshift permissions. This resolution has improved the time to marketplace for our knowledge and supplies constant entitlements throughout completely different business-driven classes.
When you’ve got any questions or feedback, please depart them within the feedback part.
Concerning the Authors
 Ashish Prabhu is a Senior Supervisor of Software program Engineering in Morningstar, Inc. He focuses on the solutioning and delivering the completely different elements of Information Lake and Information Warehouse for Morningstar’s Enterprise Information and Platform Crew. In his spare time he enjoys taking part in basketball, portray and spending time together with his household.
Ashish Prabhu is a Senior Supervisor of Software program Engineering in Morningstar, Inc. He focuses on the solutioning and delivering the completely different elements of Information Lake and Information Warehouse for Morningstar’s Enterprise Information and Platform Crew. In his spare time he enjoys taking part in basketball, portray and spending time together with his household.
 Stephen Johnston is a Distinguished Software program Architect at Morningstar, Inc. His focus is on knowledge lake and knowledge warehousing applied sciences for Morningstar’s Enterprise Information Platform group.
Stephen Johnston is a Distinguished Software program Architect at Morningstar, Inc. His focus is on knowledge lake and knowledge warehousing applied sciences for Morningstar’s Enterprise Information Platform group.
 Colin Ingarfield is a Lead Software program Engineer at Morningstar, Inc. Based mostly in Austin, Colin focuses on entry management and knowledge entitlements on Morningstar’s rising Information Lake platform.
Colin Ingarfield is a Lead Software program Engineer at Morningstar, Inc. Based mostly in Austin, Colin focuses on entry management and knowledge entitlements on Morningstar’s rising Information Lake platform.
 Don Drake is a Senior Analytics Specialist Options Architect at AWS. Based mostly in Chicago, Don helps Monetary Companies clients migrate workloads to AWS.
Don Drake is a Senior Analytics Specialist Options Architect at AWS. Based mostly in Chicago, Don helps Monetary Companies clients migrate workloads to AWS.

{kind=link}