

It is a visitor submit from the M Science Information Science & Engineering Workforce.
Fashionable knowledge doesn’t cease rising
“Engineers are taught by life expertise that doing one thing fast and doing one thing proper are mutually unique! With Structured Streaming from Databricks, M Science will get each velocity and accuracy from our analytics platform, with out the necessity to rebuild our infrastructure from scratch each time.”
– Ben Tallman, CTO
Let’s say that you simply, a “humble knowledge plumber” of the Massive Information period and have been tasked to create an analytics resolution for an on-line retail dataset:
| Bill No |
Inventory Code |
Description | Amount | Bill Date |
Unit Value |
Buyer ID |
Nation |
|---|---|---|---|---|---|---|---|
| 536365 | 85123A | WHITE HANGING HEA | 6 | 2012-01-10 | 2.55 | 17850 | United Kingdom |
| 536365 | 71053 | WHITE METAL LANTERN | 6 | 2012-01-10 | 3.39 | 17850 | United Kingdom |
| 536365 | 84406B | CREAM CUPID HEART | 8 | 2012-01-10 | 2.75 | 17850 | United Kingdom |
| … | … | … | … | … | … | … | … |
The evaluation you’ve been requested for is easy – an aggregation of the variety of {dollars}, items offered, and distinctive customers for every day, and throughout every inventory code. With just some strains of PySpark, we are able to remodel our uncooked knowledge right into a usable mixture:
import pyspark.sql.capabilities as F
df = spark.desk("default.online_retail_data")
agg_df = (
df
# Group knowledge by month, merchandise code and nation
.groupBy(
"InvoiceDate",
"StockCode",
)
# Return mixture totals of {dollars}, items offered, and distinctive customers
.agg(
F.sum("UnitPrice")
.alias("{Dollars}"),
F.sum("Amount")
.alias("Models"),
F.countDistinct("CustomerID")
.alias("Customers"),
)
)
(
agg_df.write
.format('delta')
.mode('overwrite')
.saveAsTable("analytics.online_retail_aggregations")
)
Together with your new aggregated knowledge, you'll be able to throw collectively a pleasant visualization to do... enterprise issues.
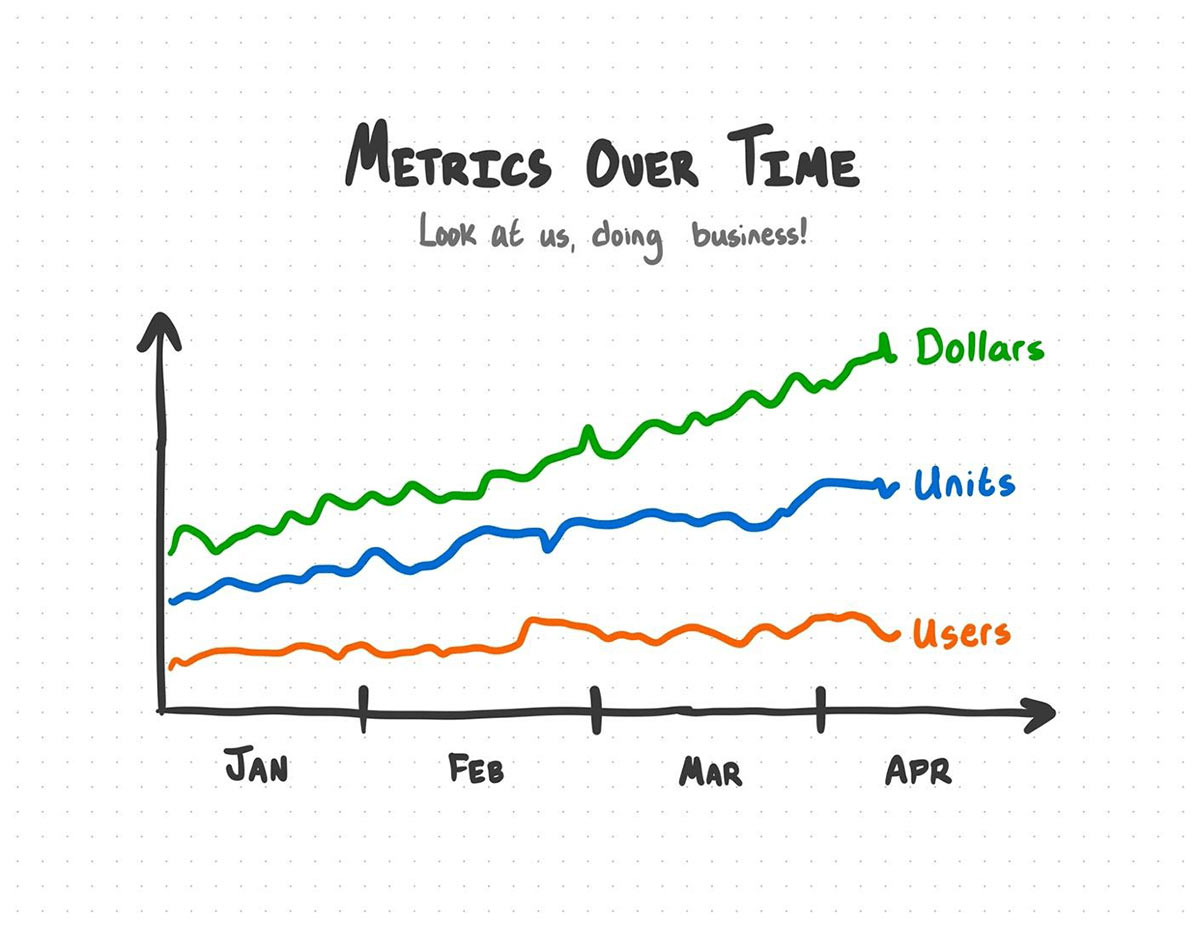
This works – proper?
An ETL course of will work nice for a static evaluation the place you don’t anticipate the information to ever be up to date – you assume the information you’ve got now would be the solely knowledge you ever have. The issue with a static evaluation?
What are you going to do once you get extra knowledge?
The naive reply can be to only run that very same code day-after-day, however you’d re-process all the information each time you run the code, and every new replace means re-processing knowledge you’ve already processed earlier than. When your knowledge will get large enough, you’ll be doubling down on what you spend in time and compute prices.
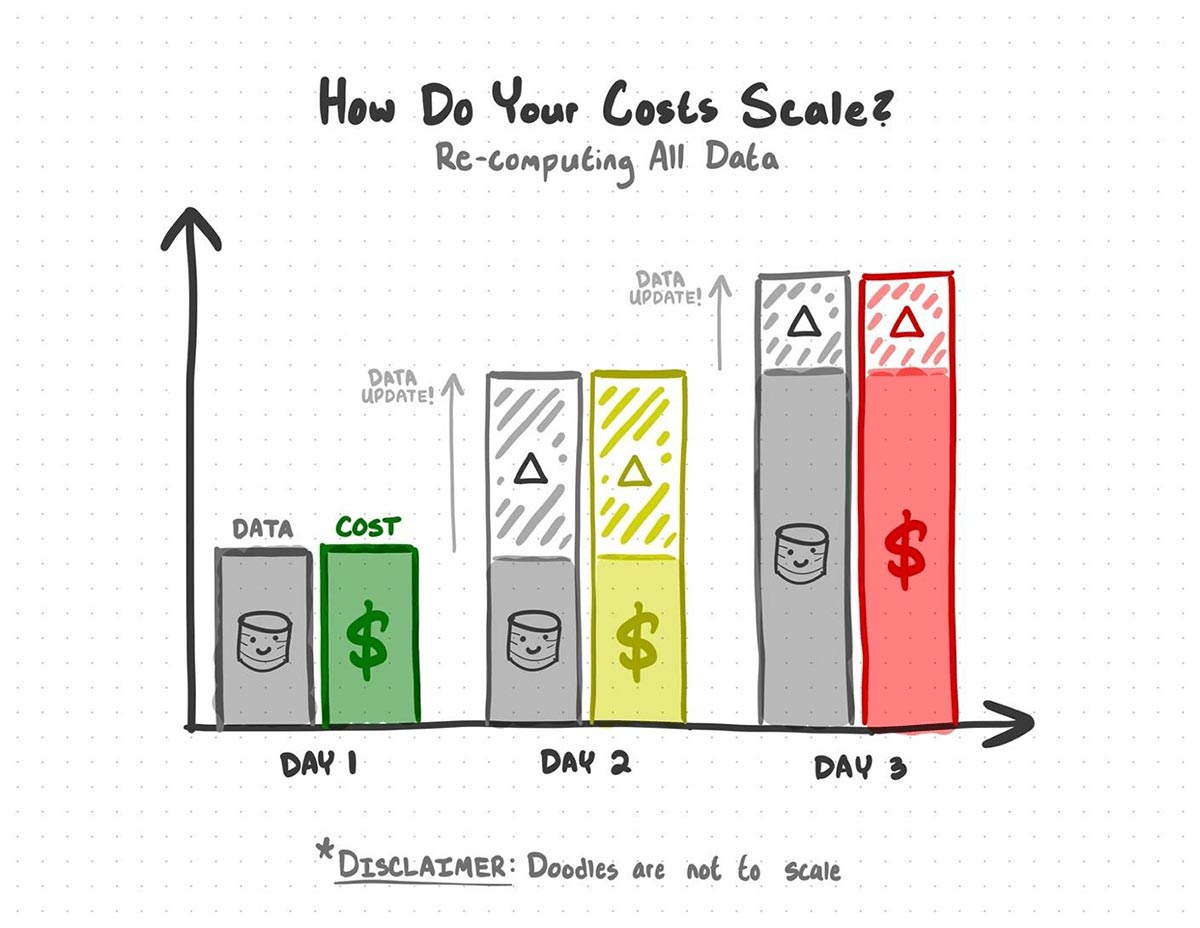
With static evaluation, you spend cash on re-processing knowledge you’ve already processed earlier than.
There are only a few fashionable knowledge sources that aren’t going to be up to date. If you wish to maintain your analytics rising along with your knowledge supply and save your self a fortune on compute value, you’ll want a greater resolution.
What will we do when our knowledge grows?
Prior to now few years, the time period “Massive Information” has grow to be… missing. Because the sheer quantity of knowledge has grown and extra of life has moved on-line, the period of Massive Information has grow to be the period of “Assist Us, It Simply Received’t Cease Getting Larger Information.” An excellent knowledge supply doesn’t cease rising whilst you work; this progress could make protecting knowledge merchandise up-to-date a monumental job.
At M Science, our mission is to make use of various knowledge – knowledge exterior of your typical quarterly report or inventory development knowledge sources – to investigate, refine, and predict change available in the market and economic system.
Every single day, our analysts and engineers face a problem: various knowledge grows actually quick. I’d even go as far to say that, if our knowledge ever stops rising, one thing within the economic system has gone very, very improper.
As our knowledge grows, our analytics options have to deal with that progress. Not solely do we have to account for progress, however we additionally have to account for knowledge that will are available in late or out-of-order. It is a very important a part of our mission – each new batch of knowledge may very well be the batch that indicators a dramatic change within the economic system.
To make scalable options to the analytics merchandise that M Science analysts and shoppers depend upon day-after-day, we use Databricks Structured Streaming, an Apache Spark™ API for scalable and fault-tolerant stream processing constructed on the Spark SQL engine with the Databricks Lakehouse Platform. Structured Streaming assures us that, as our knowledge grows, our options can even scale.
Utilizing Spark Structured Streaming
Structured Streaming comes into play when new batches of knowledge are being launched into your knowledge sources. Structured Streaming leverages Delta Lake’s skill to trace modifications in your knowledge to find out what knowledge is a part of an replace and re-computes solely the elements of your evaluation which might be affected by the brand new knowledge.
It’s vital to re-frame how you concentrate on streaming knowledge. For many individuals, “streaming” means real-time knowledge – streaming a film, checking Twitter, checking the climate, et cetera. Should you’re an analyst, engineer, or scientist, any knowledge that will get up to date is a stream. The frequency of the replace doesn’t matter. It may very well be seconds, hours, days, and even months – if the information will get up to date, the information is a stream. If the information is a stream, then Structured Streaming will prevent numerous complications.
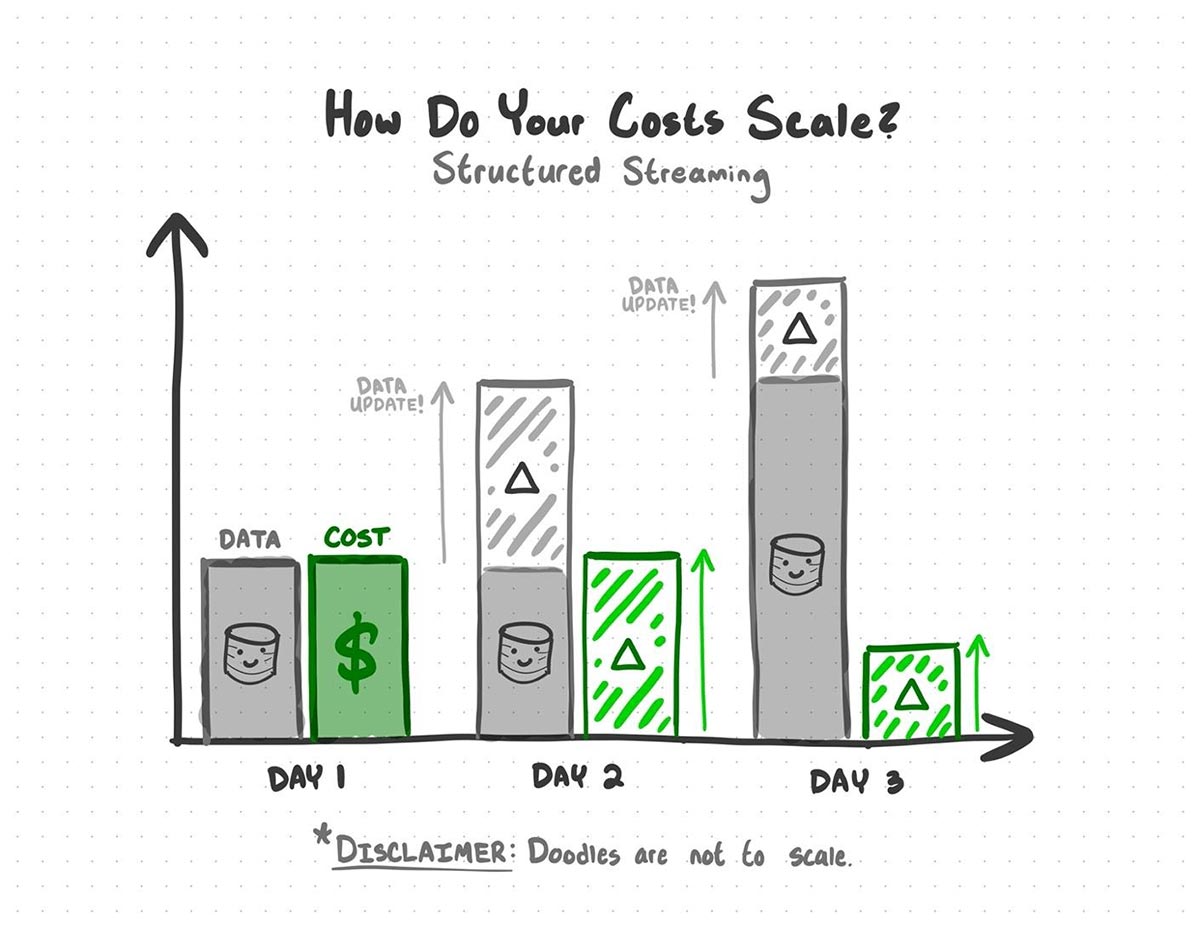
With Structured Streaming, you’ll be able to keep away from the price of re-processing earlier knowledge
Let’s step again into our hypothetical – you’ve got an mixture evaluation that it is advisable to ship at this time and maintain updating as new knowledge rolls in. This time, we’ve the DeliveryDate column to remind us of the futility of our earlier single-shot evaluation:
| Bill No |
Inventory Code |
Description | Amount | Bill Date |
Supply Date |
Unit Value |
Buyer ID |
Nation |
|---|---|---|---|---|---|---|---|---|
| 536365 | 85123A | WHITE HANGING HEA | 6 | 2012-01-10 | 2012-01-17 | 2.55 | 17850 | United Kingdom |
| 536365 | 71053 | WHITE METAL LANTERN | 6 | 2012-01-10 | 2012-01-15 | 3.39 | 17850 | United Kingdom |
| 536365 | 84406B | CREAM CUPID HEART | 8 | 2012-01-10 | 2012-01-16 | 2.75 | 17850 | United Kingdom |
| … | … | … | … | … | … | … | … | … |
Fortunately, the interface for Structured Streaming is extremely much like your unique PySpark snippet. Right here is your unique static batch evaluation code:
# =================================
# ===== OLD STATIC BATCH CODE =====
# =================================
import pyspark.sql.capabilities as F
df = spark.desk("default.online_retail_data")
agg_df = (
df
# Group knowledge by date & merchandise code
.groupBy(
"InvoiceDate",
"StockCode",
)
# Return mixture totals of {dollars}, items offered, and distinctive customers
.agg(
F.sum("UnitPrice")
.alias("{Dollars}"),
F.sum("Amount")
.alias("Models"),
F.countDistinct("CustomerID")
.alias("Customers"),
)
)
(
agg_df.write
.format('delta')
.mode('overwrite')
.saveAsTable("analytics.online_retail_aggregations")
)
With just some tweaks, we are able to modify this to leverage Structured Streaming. To transform your earlier code, you’ll:
- Learn our enter desk as a stream as a substitute of a static batch of knowledge
- Make a listing in your file system the place checkpoints can be saved
- Set a watermark to determine a boundary for the way late knowledge can arrive earlier than it’s ignored within the evaluation
- Modify a few of your transformations to maintain the saved checkpoint state from getting too giant
- Write your remaining evaluation desk as a stream that incrementally processes the enter knowledge
We’ll apply these tweaks, run via every change, and provide you with just a few choices for the best way to configure the habits of your stream.
Right here is the ‚"stream-ified"‚ model of your outdated code:
# =========================================
# ===== NEW STRUCTURED STREAMING CODE =====
# =========================================
+ CHECKPOINT_DIRECTORY = "/delta/checkpoints/online_retail_analysis"
+ dbutils.fs.mkdirs(CHECKPOINT_DIRECTORY)
+ df = spark.readStream.desk("default.online_retail_data")
agg_df = (
df
+ # Watermark knowledge with an InvoiceDate of -7 days
+ .withWatermark("InvoiceDate", f"7 days")
# Group knowledge by date & merchandise code
.groupBy(
"InvoiceDate",
"StockCode",
)
# Return mixture totals of {dollars}, items offered, and distinctive customers
.agg(
F.sum("UnitPrice")
.alias("{Dollars}"),
F.sum("Amount")
.alias("Models"),
+ F.approx_count_distinct("CustomerID", 0.05)
.alias("Customers"),
)
)
(
+ agg_df.writeStream
.format("delta")
+ .outputMode("replace")
+ .set off(as soon as = True)
+ .possibility("checkpointLocation", CHECKPOINT_DIR)
+ .toTable("analytics.online_retail_aggregations")
)
Let’s run via every of the tweaks we made to get Structured Streaming working:
+ df = spark.readStream.desk("default.online_retail_data")
Of all of Delta tables’ nifty options, this can be the niftiest: You’ll be able to deal with them like a stream. As a result of Delta retains monitor of updates, you should use .readStream.desk() to stream new updates every time you run the method.
It’s vital to notice that your enter desk should be a Delta desk for this to work. It’s attainable to stream different knowledge codecs with totally different strategies, however .readStream.desk() requires a Delta desk
2. Declare a checkpoint location
+ # Create checkpoint listing
+ CHECKPOINT_DIRECTORY = "/delta/checkpoints/online_retail_analysis"
+ dbutils.fs.mkdirs(CHECKPOINT_DIRECTORY)
In Structured Streaming-jargon, the aggregation on this evaluation is a stateful transformation. With out getting too far within the weeds, Structured Streaming saves out the state of the aggregation as a checkpoint each time the evaluation is up to date.
That is what saves you a fortune in compute value: as a substitute of re-processing all the information from scratch each time, updates merely choose up the place the final replace left off.
+ # Watermark knowledge with an InvoiceDate of -7 days
+ .withWatermark("InvoiceDate", f"7 days")
If you get new knowledge, there’s a superb likelihood that you could be obtain knowledge out-of-order. Watermarking your knowledge permits you to outline a cutoff for the way far again aggregates may be up to date. In a way, it creates a boundary between “dwell” and “settled” knowledge.
As an example: let’s say this knowledge product incorporates knowledge as much as the seventh of the month. We’ve set our watermark to 7 days. This implies aggregates from the seventh to the first are nonetheless “dwell”. New updates might change aggregates from the first to the seventh, however any new knowledge that lagged behind greater than 7 days gained’t be included within the replace – aggregates previous to the first are “settled”, and updates for that interval are ignored.
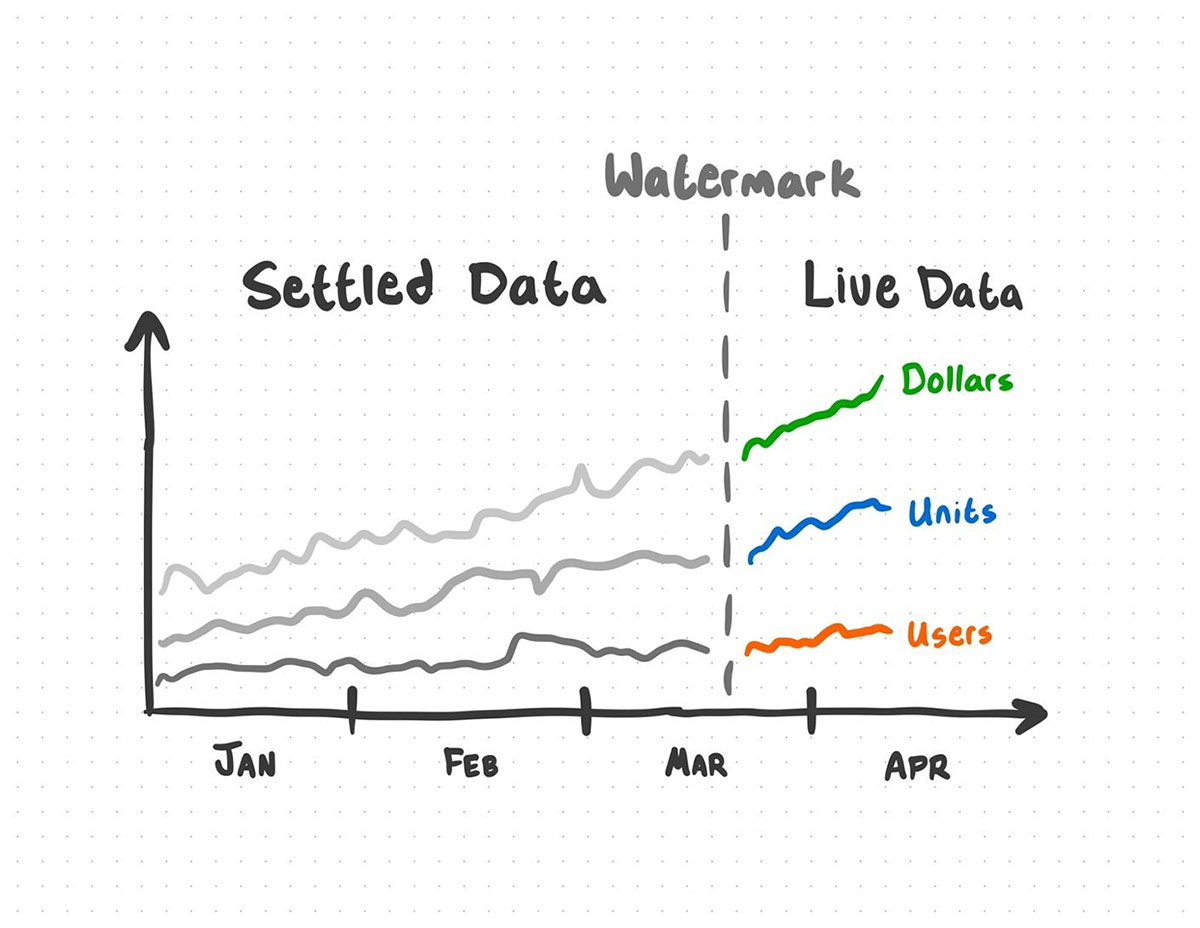
New knowledge that falls exterior of the watermark just isn’t included into the evaluation.
It’s vital to notice that the column you employ to watermark have to be both a Timestamp or a Window.
4. Use Structured Streaming-compatible transformations
+ F.approx_count_distinct("CustomerID", 0.05)
So as to maintain your checkpoint states from ballooning, it’s possible you’ll want to exchange a few of your transformations with extra storage-efficient options. For a column that will comprise a lot of distinctive particular person values, the approx_count_distinct operate will get you outcomes inside an outlined relative commonplace deviation.
+ agg_df.writeStream
.format("delta")
+ .outputMode("replace")
+ .set off(as soon as = True)
+ .possibility("checkpointLocation", CHECKPOINT_DIR)
+ .toTable("analytics.online_retail_aggregations")
The ultimate step is to output the evaluation right into a Delta desk. With this comes just a few choices that decide how your stream will behave:
.outputMode("replace")configures the stream in order that the aggregation will choose up the place it left off every time the code runs as a substitute of operating from scratch. To re-do an aggregation from scratch, you should use"full"– in impact, doing a standard batch mixture whereas nonetheless preserving the aggregation state for a future"replace"run.set off(as soon as = True)will set off the question as soon as, when the road of output code is began, after which cease the question as soon as all the new knowledge has been processed."checkpointLocation"lets this system know the place checkpoints must be saved.
These configuration choices make the stream behave most intently like the unique one-shot resolution.
This all comes collectively to create a scalable resolution to your rising knowledge. If new knowledge is added to your supply, your evaluation will consider the brand new knowledge with out costing an arm and a leg.
You’d be exhausting pressed to seek out any context the place knowledge isn’t going to be up to date sooner or later. It’s a delicate settlement that knowledge analysts, engineers, and scientists make once we work with fashionable knowledge – it’s going to develop, and we’ve to seek out methods to deal with that progress.
With Spark Structured Streaming, we are able to use the most recent and biggest knowledge to ship the perfect merchandise, with out the complications that include scale.

{kind=link}