

This can be a joint put up co-authored with Nir Tsruya from Klarna Financial institution AB.
Klarna is a number one international funds and buying service, offering smarter and extra versatile buying and buy experiences to 150 million lively customers throughout greater than 500,000 retailers in 45 nations. Klarna affords direct funds, pay after supply choices, and instalment plans in a clean one-click buy expertise that lets customers pay when and the way they like to. The power to make the most of knowledge to make near-real-time selections is a supply of aggressive benefit for Klarna.
This put up presents a reference structure for real-time queries and decision-making on AWS utilizing Amazon Kinesis Information Analytics for Apache Flink. As well as, we clarify why the Klarna Choice Tooling staff chosen Kinesis Information Analytics for Apache Flink for his or her first real-time choice question service. We present how Klarna makes use of Kinesis Information Analytics for Apache Flink as a part of an end-to-end resolution together with Amazon DynamoDB and Apache Kafka to course of real-time decision-making.
AWS affords a wealthy set of providers that you should use to understand real-time insights. These providers embody Kinesis Information Analytics for Apache Flink, the answer Klarna that makes use of to underpin automated decision-making of their enterprise immediately. Kinesis Information Analytics for Apache Flink means that you can simply construct stream processing purposes for quite a lot of sources together with Amazon Kinesis Information Streams, Amazon Managed Streaming for Apache Kafka (Amazon MSK), and Amazon MQ.
The problem: Actual-time decision-making at scale
Klarna’s prospects count on a real-time, frictionless, on-line expertise when buying and paying on-line. Within the background, Klarna must assess dangers resembling credit score threat, fraud makes an attempt, and cash laundering for each buyer credit score request in each working geography. The end result of this threat evaluation is known as a choice. Choices generate tens of millions of threat evaluation transactions a day that should be run in near-real time. The ultimate choice is the report of whether or not Klarna has accredited or rejected the request to increase credit score to a shopper. These underwriting selections are essential artefacts. First, they comprise data that should be continued for authorized causes. Second, they’re used to construct profiles and fashions which can be fed into underwriting insurance policies to enhance the choice course of. Underneath the hood, a choice is the sum of various transactions (for instance, credit score checks), coordinated and continued through a choice retailer.
Klarna wished to construct a framework to make sure selections persist efficiently, guaranteeing well timed threat evaluation and fast selections for patrons. First, the Klarna staff regarded to resolve the issue of manufacturing and capturing selections through the use of a mixture of Apache Kafka and AWS Lambda. By publishing choice artefacts on to a Kafka matter, the Klarna staff discovered that prime latency might trigger lengthy transaction wait occasions or transactions to be rejected altogether, resulting in delays in getting ratified selections to prospects in a well timed style and potential misplaced income. This strategy additionally brought on operational overhead for the Klarna staff, together with administration of the schema evolution, replaying previous occasions, and native integration of Lambda with their self-managed Apache Kafka clusters.
Design necessities
Klarna was capable of set out their necessities for an answer to seize threat evaluation artefacts (selections), appearing as a supply of fact for all underwriting selections inside Klarna. The important thing necessities included at-least as soon as reliability and millisecond latency, enabling real-time entry to decision-making and the power to replay previous occasions in case of lacking knowledge in downstream methods. Moreover, the staff wanted a system that might scale to maintain tempo with Klarna’s speedy [10 times] development.
Resolution overview
The answer consists of two parts: a mixture of an extremely obtainable API with DynamoDB as the information retailer to retailer every choice, and Amazon DynamoDB Streams with Kinesis Information Analytics. Kinesis Information Analytics is a completely managed Apache Flink service and used to stream, course of, enrich, and standardize the choice in actual time and replay previous occasions (if wanted).
The next diagram illustrates the general circulate from end-user to the downstream methods.
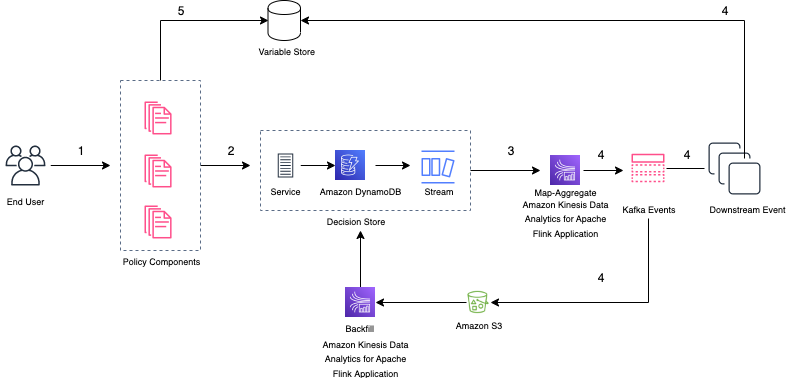
The circulate consists of the next steps:
- Because the end-user makes a purchase order, the coverage parts assess threat and the choice is shipped to a choice retailer through the Choice Retailer API.
- The Choice Retailer API persists the information in DynamoDB and responds to the requester. Choices for every transaction are time-ordered and streamed by DynamoDB Streams. Choice Retailer additionally permits centralised schema administration and handles evolution of occasion schemas.
- The Kinesis Information Analytics for Apache Flink software is the patron of DynamoDB streams. The applying makes certain that the selections captured are conforming to the anticipated occasion schema that’s then revealed to a Kafka matter to be consumed by varied downstream methods. Right here, Kinesis Information Analytics for Apache Flink performs an important half within the supply of these occasions: aggregating, enriching, and mapping knowledge to stick to the occasion schema. This offers a standardized manner for customers to entry selections from their respective producers. The applying permits at-least as soon as supply functionality, and Flink’s checkpoint and retry mechanism ensures that each occasion is processed and continued.
- The revealed Kafka occasions are consumed by the downstream methods and saved in an Amazon Easy Storage Service (Amazon S3) bucket. The occasions saved in Amazon S3 mirror each choice ever taken by the manufacturing coverage parts, and can be utilized by the choice retailer to backfill and replay any previous occasions. Along with preserving the historical past of choice occasions, occasions are additionally saved as a set of variables within the variable retailer.
- Coverage parts use the variable retailer to verify for related previous selections to find out if a request could be accepted or denied instantly. The request is then processed as described by the previous workflow, and the subsequent subsequent request might be answered by the variable retailer based mostly on the results of the earlier choice.
The choice retailer offers a standardized workflow for processing and producing occasions for downstream methods and buyer help. With all of the occasions captured and safely saved in DynamoDB, the choice retailer offers an API for help engineers (and different supporting instruments like chatbots) to question and entry previous selections in near-real time.
Resolution impression
The answer supplied advantages in three areas.
First, the managed nature of Kinesis Information Analytics allowed the Klarna staff to concentrate on value-adding software growth as an alternative of managing infrastructure. The staff is ready to onboard new use circumstances in lower than every week. They’ll take full benefit of the auto scaling function in Kinesis Information Analytics and pre-built sources and locations.
Second, the staff can use Apache Flink to make sure the accuracy, completeness, consistency, and reliability of knowledge. Flink’s native functionality of stateful computation and knowledge accuracy via the usage of checkpoints and savepoints straight helps Klarna staff’s imaginative and prescient so as to add extra logic into the pipelines, permitting the staff to develop to completely different use circumstances confidently. Moreover, the low latency of the service ensures that enriched choice artefacts can be found to customers and subsequently to the coverage brokers for future decision-making in near-real time.
Third, the answer permits the Klarna staff to reap the benefits of the Apache Flink open-source neighborhood, which offers wealthy neighborhood help and the chance to contribute again to the neighborhood by bug fixing or including new options.
This resolution has confirmed to scale with elevated adoption of a brand new use case, translating to a 10-times enhance in occasions over 3 months.
Classes discovered
The Klarna staff confronted a couple of challenges with Flink serialization and upgrading Apache Flink variations. Flink serialization is an fascinating idea and demanding for the applying’s efficiency. Flink makes use of a special set of serializers with a view to serialize knowledge between the operators. It’s as much as the staff to configure the very best and most effective serializer based mostly on the use case. The Klarna staff configured the objects as Flink POJO, which lowered the pipeline runtime by 85%. For extra data, discuss with Flink Serialization Tuning Vol. 1: Selecting your Serializer — for those who can earlier than deploying a Flink software to manufacturing.
The opposite problem confronted by the staff was upgrading the Apache Flink model in Kinesis Information Analytics. Presently, the Kinesis Information Analytics for Apache Flink software requires the creation of a brand new Kinesis Information Analytics for Apache Flink software. At the moment, reusing a snapshot (the binary artefact representing the state of the Flink software, used to revive the applying to the final checkpoint taken) will not be potential between two completely different purposes. For that motive, upgrading the Apache Flink model requires extra steps with a view to guarantee the applying doesn’t lose knowledge.
What’s subsequent for Klarna and Kinesis Information Analytics for Apache Flink?
The staff is trying into increasing the utilization of Kinesis Information Analytics and Flink in Klarna. As a result of the staff is already extremely skilled within the know-how, their first ambition might be to personal the infrastructure of a Kinesis Information Analytics for Apache Flink deployment, and join it to completely different Klarna knowledge sources. The staff then will host enterprise logic supplied by different departments in Klarna resembling Fraud Prevention. It will enable the specialised groups to focus on the enterprise logic and fraud detection algorithms, whereas choice tooling will deal with the infrastructure.
Klarna, AWS, and the Flink neighborhood
A key a part of selecting Kinesis Information Analytics for Apache Flink was the open-source neighborhood and help.
A number of groups inside Klarna created completely different implementations of a Flink DynamoDB connector, which have been used internally by a number of groups. Klarna then recognized the chance to create a single maintained DynamoDB Flink connector and contribute it to the open-source neighborhood. This has initiated a collaboration inside Klarna, led by the Klarna Flink consultants and accompanied by Flink open-source contributors from AWS.
The primary precept for designing the DynamoDB Flink connector was using the completely different write capability modes of DynamoDB. DynamoDB helps On-demand and Provisioned capability modes and every behaves in a different way in the case of the way it handles incoming throughput. On-demand mode will routinely scale up DynamoDB write capability and apply itself to the incoming load. Nonetheless, Provisioned mode is extra limiting, and can throttle incoming visitors in accordance with the provisioned write capability.
To adjust to this course of, the DynamoDB Flink connector was designed to permit concurrent writes to DynamoDB. The variety of concurrent requests could be configured to adjust to DynamoDB’s capability mode. As well as, the DynamoDB Flink connector helps backpressure dealing with in case the DynamoDB write provisioning is low in comparison with the incoming load from the Apache Flink software.
On the time of writing, the DynamoDB Flink connector has been open sourced.
Conclusion
Klarna has efficiently been working Kinesis Information Analytics for Apache Flink in manufacturing since October 2020. It offers a number of key advantages. The Klarna growth staff can concentrate on growth, not on cluster and operational administration. Their purposes could be rapidly modified and uploaded. The low latency properties of the service guarantee a near-real-time expertise for end-users, knowledge customers, and producers, which underpin threat evaluation and the decision-making processes underpinning steady visitors development. On the similar time, exactly-once processing together with Flink checkpoints and savepoints signifies that essential decision-making and authorized knowledge will not be misplaced.
To study extra about Kinesis Information Analytics and getting began, discuss with Utilizing a Studio pocket book with Kinesis Information Analytics for Apache Flink and Extra Kinesis Information Analytics Options on GitHub.
In regards to the authors
 Nir Tsruya is a Lead Engineer in Klarna. He leads 2 engineering groups focusing primarily on actual time knowledge processing and analytics at giant scale.
Nir Tsruya is a Lead Engineer in Klarna. He leads 2 engineering groups focusing primarily on actual time knowledge processing and analytics at giant scale.
 Ankit Gupta is a Senior Options Architect at Amazon Net Serves based mostly in Stockholm, Sweden, the place we helps prospects throughout the Nordics achieve Cloud. He’s significantly keen about constructing robust Networking basis in Cloud.
Ankit Gupta is a Senior Options Architect at Amazon Net Serves based mostly in Stockholm, Sweden, the place we helps prospects throughout the Nordics achieve Cloud. He’s significantly keen about constructing robust Networking basis in Cloud.
 Daniel Arenhage is a Options Architect at Amazon Net Companies based mostly in Gothenburg, Sweden.
Daniel Arenhage is a Options Architect at Amazon Net Companies based mostly in Gothenburg, Sweden.

{kind=link}