

It is a visitor weblog publish co-written with Addison Higley and Ramzi Yassine from Hudl.
Hudl Agile Sports activities Applied sciences, Inc. is a Lincoln, Nebraska primarily based firm that gives instruments for coaches and athletes to evaluation recreation footage and enhance particular person and workforce play. Its preliminary product line served faculty {and professional} American soccer groups. At this time, the corporate offers video providers to youth, novice, {and professional} groups in American soccer in addition to different sports activities, together with soccer, basketball, volleyball, and lacrosse. It now serves 170,000 groups in 50 completely different sports activities all over the world. Hudl’s total aim is to seize and convey worth to each second in sports activities.
Hudl’s mission is to make each second in sports activities rely. Hudl does this by increasing entry to extra moments by way of video and information and placing these moments in context. Our aim is to extend entry by completely different folks and enhance context with extra information factors for each buyer we serve. Utilizing information to generate analytics, Hudl is ready to flip information into actionable insights, telling highly effective tales with video and information.
To greatest serve our clients and supply essentially the most highly effective insights attainable, we want to have the ability to examine massive units of information between completely different sources. For instance, enriching our MongoDB and Amazon DocumentDB (with MongoDB compatibility) information with our software logging information results in new insights. This requires resilient information pipelines.
On this publish, we talk about how Hudl has iterated on one such information pipeline utilizing AWS Glue to enhance efficiency and scalability. We speak in regards to the preliminary structure of this pipeline, and a number of the limitations related to this strategy. We additionally talk about how we iterated on that design utilizing Apache Hudi to dramatically enhance efficiency.
Downside assertion
A knowledge pipeline that ensures high-quality MongoDB and Amazon DocumentDB statistics information is out there in our central information lake, and is a requirement for Hudl to have the ability to ship sports activities analytics. It’s essential to keep up the integrity of the info between MongoDB and Amazon DocumentDB transactional information with the info lake capturing modifications in near-real time together with upserts to data within the information lake. As a result of Hudl statistics are backed by MongoDB and Amazon DocumentDB databases, along with a broad vary of different information sources, it’s essential that related MongoDB and Amazon DocumentDB information is out there in a central information lake the place we will run analytics queries to check statistics information between sources.
Preliminary design
The next diagram demonstrates the structure of our preliminary design.

Let’s talk about the important thing AWS providers of this structure:
- AWS Knowledge Migration Service (AWS DMS) allowed our workforce to maneuver shortly in delivering this pipeline. AWS DMS offers our workforce a full snapshot of the info, and in addition gives ongoing change information seize (CDC). By combining these two datasets, we will guarantee our pipeline delivers the most recent information.
- Amazon Easy Storage Service (Amazon S3) is the spine of Hudl’s information lake due to its sturdiness, scalability, and industry-leading efficiency.
- AWS Glue permits us to run our Spark workloads in a serverless style, with minimal setup. We selected AWS Glue for its ease of use and velocity of growth. Moreover, options comparable to AWS Glue bookmarking simplified our file administration logic.
- Amazon Redshift gives petabyte-scale information warehousing. Amazon Redshift offers persistently quick efficiency, and straightforward integrations with our S3 information lake.
The info processing movement consists of the next steps:
- Amazon DocumentDB holds the Hudl statistics information.
- AWS DMS offers us a full export of statistics information from Amazon DocumentDB, and ongoing modifications in the identical information.
- Within the S3 Uncooked Zone, the info is saved in JSON format.
- An AWS Glue job merges the preliminary load of statistics information with the modified statistics information to offer a snapshot of statistics information in JSON format for reference, eliminating duplicates.
- Within the S3 Cleansed Zone, the JSON information is normalized and transformed to Parquet format.
- AWS Glue makes use of a COPY command to insert Parquet information into Amazon Redshift consumption base tables.
- Amazon Redshift shops the ultimate desk for consumption.
The next is a pattern code snippet from the AWS Glue job within the preliminary information pipeline:
Challenges
Though this preliminary answer met our want for information high quality, we felt there was room for enchancment:
- The pipeline was gradual – The pipeline ran slowly (over 2 hours) as a result of for every batch, the entire dataset was in contrast. Each file needed to be in contrast, flattened, and transformed to Parquet, even when only some data have been modified from the earlier each day run.
- The pipeline was costly – As the info measurement grew each day, the job period additionally grew considerably (particularly in step 4). To mitigate the impression, we wanted to allocate extra AWS Glue DPUs (Knowledge Processing Items) to scale the job, which led to increased value.
- The pipeline restricted our means to scale – Hudl’s information has an extended historical past of speedy development with rising clients and sporting occasions. Given this pattern, our pipeline wanted to run as effectively as attainable to deal with solely altering datasets to have predictable efficiency.
New design
The next diagram illustrates our up to date pipeline structure.
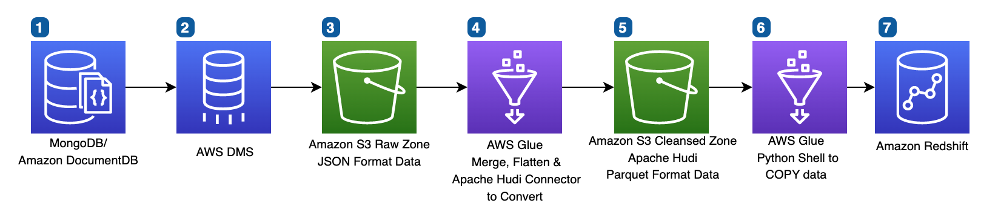
Though the general structure appears roughly the identical, the inner logic in AWS Glue was considerably modified, together with addition of Apache Hudi datasets.
In step 4, AWS Glue now interacts with Apache HUDI datasets within the S3 Cleansed Zone to upsert or delete modified data as recognized by AWS DMS CDC. The AWS Glue to Apache Hudi connector helps convert JSON information to Parquet format and upserts into the Apache HUDI dataset. Retaining the total paperwork in our Apache HUDI dataset permits us to simply make schema modifications to our ultimate Amazon Redshift tables while not having to re-export information from our supply programs.
The next is a pattern code snippet from the brand new AWS Glue pipeline:
Outcomes
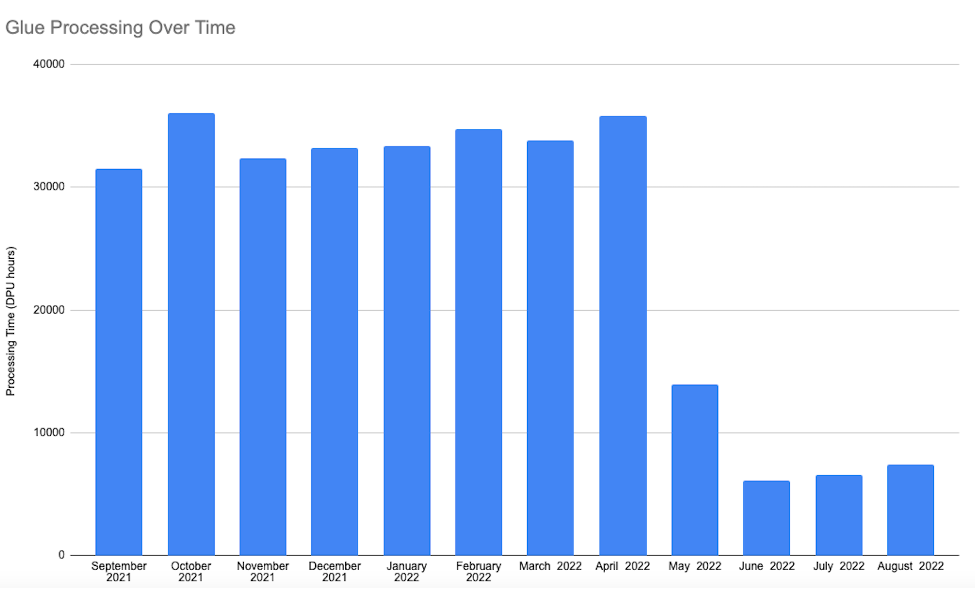
With this new strategy utilizing Apache Hudi datasets with AWS Glue deployed after Could 2022, the pipeline runtime was predictable and cheaper than the preliminary strategy. As a result of we solely dealt with new or modified data by eliminating the total outer be part of over your entire dataset, we noticed an 80–90% discount in runtime for this pipeline, thereby decreasing prices by 80–90% in comparison with the preliminary strategy. The next diagram illustrates our processing time earlier than and after implementing the brand new pipeline.
Conclusion
With Apache Hudi’s open-source information administration framework, we simplified incremental information processing in our AWS Glue information pipeline to handle information modifications on the file degree in our S3 information lake with CDC from Amazon DocumentDB.
We hope that this publish will encourage your group to construct AWS Glue pipelines with Apache Hudi datasets that cut back value and convey efficiency enhancements utilizing serverless applied sciences to realize what you are promoting targets.
In regards to the authors
 Addison Higley is a Senior Knowledge Engineer at Hudl. He manages over 20 information pipelines to assist guarantee information is out there for analytics so Hudl can ship insights to clients.
Addison Higley is a Senior Knowledge Engineer at Hudl. He manages over 20 information pipelines to assist guarantee information is out there for analytics so Hudl can ship insights to clients.
 Ramzi Yassine is a Lead Knowledge Engineer at Hudl. He leads the structure, implementation of Hudl’s information pipelines and information purposes, and ensures that our information empowers inside and exterior analytics.
Ramzi Yassine is a Lead Knowledge Engineer at Hudl. He leads the structure, implementation of Hudl’s information pipelines and information purposes, and ensures that our information empowers inside and exterior analytics.
 Swagat Kulkarni is a Senior Options Architect at AWS and an AI/ML fanatic. He’s keen about fixing real-world issues for patrons with cloud-native providers and machine studying. Swagat has over 15 years of expertise delivering a number of digital transformation initiatives for patrons throughout a number of domains, together with retail, journey and hospitality, and healthcare. Exterior of labor, Swagat enjoys journey, studying, and meditating.
Swagat Kulkarni is a Senior Options Architect at AWS and an AI/ML fanatic. He’s keen about fixing real-world issues for patrons with cloud-native providers and machine studying. Swagat has over 15 years of expertise delivering a number of digital transformation initiatives for patrons throughout a number of domains, together with retail, journey and hospitality, and healthcare. Exterior of labor, Swagat enjoys journey, studying, and meditating.
 Indira Balakrishnan is a Principal Options Architect within the AWS Analytics Specialist SA Group. She is keen about serving to clients construct cloud-based analytics options to resolve their enterprise issues utilizing data-driven choices. Exterior of labor, she volunteers at her children’ actions and spends time together with her household.
Indira Balakrishnan is a Principal Options Architect within the AWS Analytics Specialist SA Group. She is keen about serving to clients construct cloud-based analytics options to resolve their enterprise issues utilizing data-driven choices. Exterior of labor, she volunteers at her children’ actions and spends time together with her household.

{kind=link}