
This publish was co-written with Rajiv Arora, Director of Information Science Platform at Gilead Life Sciences.
Gilead Sciences, Inc. is a biopharmaceutical firm dedicated to advancing revolutionary medicines to stop and deal with life-threatening illnesses, together with HIV, viral hepatitis, irritation, and most cancers. A frontrunner in virology, Gilead traditionally relied on these medication for progress however now by means of strategic investments, Gilead is increasing and growing their focus in oncology, having acquired Kite and Immunomedics to spice up their publicity to cell remedy and non-cell remedy, making it the first progress engine. As a result of Gilead is increasing into biologics and huge molecule therapies, and has an bold objective of launching 10 revolutionary therapies by 2030, there may be heavy emphasis on utilizing knowledge with AI and machine studying (ML) to speed up the drug discovery pipeline.
Amazon Redshift Serverless is a totally managed cloud knowledge warehouse that permits you to seamlessly create your knowledge warehouse with no infrastructure administration required. You pay just for the compute assets and storage that you just use. Redshift Serverless measures knowledge warehouse capability in Redshift Processing Items (RPUs), that are a part of the compute assets. The entire knowledge saved in your warehouse, corresponding to tables, views, and customers, make up a namespace in Redshift Serverless.
One of many advantages of Redshift Serverless is that you just don’t have to dimension your knowledge warehouse in your peak workload. The height workload contains loading periodic giant datasets in multi-terabyte vary. You possibly can set a base RPU from 8 as much as 512 and Redshift Serverless will robotically scale the RPUs to satisfy your workload calls for. This makes it easy to handle your knowledge warehouse in an economical method.
On this publish, we share how Gilead collaborated with AWS to revamp their knowledge ingestion course of. They used Redshift Serverless as their knowledge producer to load third-party medical claims knowledge in a quick and cost-effective approach, lowering load occasions from days to hours.
Gilead use case
Gilead masses quite a lot of knowledge from a whole lot of sources to their R&D knowledge atmosphere. They just lately wanted to do a month-to-month load of 140 TB of uncompressed healthcare claims knowledge in beneath 24 hours after receiving it to supply analysts and knowledge scientists with up-to-date info on a affected person’s healthcare journey. This knowledge quantity is predicted to extend month-to-month and is absolutely refreshed every month. The three-node RA3 16XL provisioned cluster that had beforehand been internet hosting their warehouse was taking round 12 hours to ingest this knowledge to Amazon Redshift, and Gilead was seeking to optimize the information ingestion course of in a extra dynamic method. Working with Amazon Redshift specialists from AWS, Gilead selected Redshift Serverless as a technique to cost-effectively load this knowledge after which use Redshift knowledge sharing to share the ultimate dataset to 2 further Redshift knowledge warehouses for end-user queries.
Loading knowledge is a key course of for any analytical system, together with Amazon Redshift. When loading very giant datasets, it’s necessary to not solely load the information as shortly as doable but additionally in a approach that optimizes the consumption queries.
Gilead’s healthcare claims knowledge took 40 hours to load, which meant delays in utilizing the information for downstream processes. The groups sought enhancements, concentrating on a most 24-hour SLA for the load. They achieved the load in 8 hours, an 80% discount in time to make knowledge obtainable.
Resolution overview
After collaborating, the Gilead and AWS groups selected a two-step course of to load the information to Amazon Redshift. First, the information was loaded and not using a distkey and sortkey, which let the load course of use the total parallel assets of the cluster. Then we used a deep copy to redistribute this knowledge and add the specified distribution and kind traits.
The answer makes use of Redshift Serverless. The group needed to ingest knowledge to satisfy the required SLA, and the next approaches had been benchmarked:
- COPY command – The COPY command makes use of the Amazon Redshift massively parallel processing (MPP) structure to learn and cargo knowledge in parallel from information on Amazon Easy Storage Service (Amazon S3)
- Information lake analytics – Amazon Redshift Spectrum is used to question knowledge immediately from information on Amazon S3 by deciding on a subset of columns and avoiding the intermediate step of copying knowledge to staging desk
Preliminary Resolution strategy: Single COPY command
The group decided it could be simpler to use the distribution and kind keys in a post-copy step. The info was loaded first utilizing automated distribution of information. This took roughly 12 hours to finish. The group created open and closed claims tables with outlined dist keys and with 20% of the columns to alleviate the necessity to question the bigger desk. With this success, we discovered that we will nonetheless enhance the massive copy, as detailed within the following sections.
Proposed Resolution strategy 1: Parallel COPY command
Primarily based on the preliminary resolution strategy above, the group examined yearly parallel copy instructions as illustrated within the following diagram.

Under are the findings and learnings from this strategy:
- Ingesting knowledge for 4 years utilizing parallel copy confirmed a 25% efficiency enchancment over the one copy command.
- In comparison with Preliminary resolution strategy, the place we had been taking 12 hours to ingest the information, we additional optimized this runtime by 67% by segregating the information ingestion into separate yearly staging tables and operating parallel copy instructions.
- After the information was loaded into staging yearly tables, we created the open and closed declare tables with an auto
distkeywith the subset of columns required for bigger reporting teams. It took a further 1 hour to create.
The group used a manifest file to make it possible for the COPY command masses all the required information for the respective yr for ingesting.
Proposed Resolution strategy 2: Information Lake analytics
The group used this strategy with Redshift Spectrum to load solely the required columns to Redshift Serverless, which prevented loading knowledge into a number of yearly tables and on to a single desk. The next diagram illustrates this strategy.

The workflow consists of the next steps:
- Crawl the information utilizing AWS Glue.
- Create a knowledge lake exterior schema and desk in Redshift Serverless.
- Create two separate claims desk for open and closed claims as a result of open claims are most incessantly consumed and are 20% of the columns and 100% of the information.
- Create open and closed tables with selective columns wanted for optimum efficiency optimization throughout consumption as a substitute of all columns within the authentic third-party dataset. The info quantity distribution is as follows:
- Complete variety of open claims information = 50 billion
- Complete variety of closed claims information = 200 billion
- General, complete variety of information = 250 billion
- Distribute open and closed tables with a customer-identified
distkey. - Configure knowledge ingestion into open and closed claims tables mixed utilizing Redshift Serverless with 512 RPUs. This took 1.5 hours, which is additional improved by 70% in comparison with situation 1. We selected 512 RPUs as a way to load knowledge within the quickest approach doable.
On this technique, knowledge ingestion was streamlined by solely loading important fields from the medical claims dataset and by splitting the desk into open and closed claims. Open claims knowledge is most incessantly accessed and constitutes solely 20% of columns so by splitting the tables. The group not solely improved the ingestion efficiency but additionally consumption.
Amazon Redshift just lately launched automated mounting of AWS Glue Information Catalog, making it simpler to run knowledge lake analytics with out manually creating exterior schemas. You possibly can question knowledge lake tables immediately from Amazon Redshift Question Editor v2 or your favourite SQL editors.
Suggestions and greatest practices
Contemplate the next suggestions when loading large-scale knowledge in Amazon Redshift.
- Use Redshift Serverless with most 512 RPUs to effectively and shortly load knowledge
- Relying on consumption use case and question sample, undertake both of the next approaches:
- When consumption queries require solely chosen fields from the dataset and most incessantly entry a subset of information, use knowledge lake queries to load solely the related columns from Amazon S3 into Amazon Redshift
- When consumption queries require all fields, use COPY instructions with a manifest file to ingest knowledge in parallel into a number of logically separated tables and create a database view with UNION ALL of all tables
- Keep away from utilizing varchar(max) whereas creating tables and create VARCHAR columns with the correct dimension
Remaining Structure
The next diagram reveals the high-level closing structure that was applied.
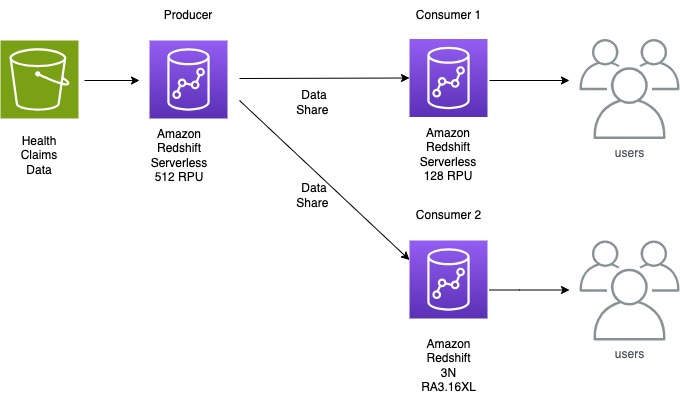
Conclusion
With the scalability of Redshift Serverless, knowledge sharing to decouple ingestion from consumption workloads, and knowledge lake analytics to ingest knowledge, Gilead made their 140 TB dataset obtainable to their analysts inside hours of it being delivered. The revolutionary structure of utilizing a serverless ingestion knowledge warehouse, a serverless consumption knowledge warehouse for energy customers, and their authentic 3-node provisioned cluster for traditional queries provides Gilead isolation to make sure knowledge masses don’t have an effect on their customers. The structure offers scalability to serve rare giant queries with their serverless client together with the advantage of a fixed-cost and fixed-performance possibility of their provisioned cluster for his or her commonplace consumer queries. Because of the month-to-month schedule of the information load and the variable want for giant queries by customers, Redshift Serverless proved to be an economical possibility in comparison with merely growing the provisioned cluster to serve every of those use circumstances.
This cut up producer/client mannequin of utilizing Redshift serverless can carry advantages to many workloads which have related efficiency traits to Gilead’s warehouse. Clients recurrently run giant knowledge masses occasionally, and people processes compete with consumer queries. With this sample, you may depend on your queries to carry out constantly no matter whether or not new knowledge is being loaded to the system. This strikes a steadiness between minimizing value whereas sustaining efficiency and frees the system directors to load knowledge with out affecting customers.
Concerning the Authors
 Rajiv Arora is a Director of Medical Information Science at Gilead Sciences with over 20 years of expertise within the trade. He’s liable for the multi-modal knowledge platform for the event group and helps all statistical and predictive analytical infrastructure for RWE and Superior Analytical features.
Rajiv Arora is a Director of Medical Information Science at Gilead Sciences with over 20 years of expertise within the trade. He’s liable for the multi-modal knowledge platform for the event group and helps all statistical and predictive analytical infrastructure for RWE and Superior Analytical features.
 Ritesh Kumar Sinha is an Analytics Specialist Options Architect based mostly out of San Francisco. He has helped clients construct scalable knowledge warehousing and massive knowledge options for over 16 years. He likes to design and construct environment friendly end-to-end options on AWS. In his spare time, he loves studying, strolling, and doing yoga.
Ritesh Kumar Sinha is an Analytics Specialist Options Architect based mostly out of San Francisco. He has helped clients construct scalable knowledge warehousing and massive knowledge options for over 16 years. He likes to design and construct environment friendly end-to-end options on AWS. In his spare time, he loves studying, strolling, and doing yoga.
 Raks Khare is an Analytics Specialist Options Architect at AWS based mostly out of Pennsylvania. He helps clients architect knowledge analytics options at scale on the AWS platform.
Raks Khare is an Analytics Specialist Options Architect at AWS based mostly out of Pennsylvania. He helps clients architect knowledge analytics options at scale on the AWS platform.
 Brent Sturdy is a Senior Options Architect within the Healthcare and Life Sciences group at AWS. He has greater than 15 years of expertise within the trade, specializing in knowledge and analytics and DevOps. At AWS, he works intently with giant Life Sciences clients to assist them ship new and revolutionary therapies.
Brent Sturdy is a Senior Options Architect within the Healthcare and Life Sciences group at AWS. He has greater than 15 years of expertise within the trade, specializing in knowledge and analytics and DevOps. At AWS, he works intently with giant Life Sciences clients to assist them ship new and revolutionary therapies.
 Phil Bates is a Senior Analytics Specialist Options Architect at AWS with over 25 years of information warehouse expertise.
Phil Bates is a Senior Analytics Specialist Options Architect at AWS with over 25 years of information warehouse expertise.

{kind=link}