

This put up is co-written with Dr. Quan Hoang Nguyen, CTO at Fantom Basis.
Right here at Fantom Basis (Fantom), we’ve developed a excessive efficiency, extremely scalable, and safe good contract platform. It’s designed to beat limitations of the earlier era of blockchain platforms. The Fantom platform is permissionless, decentralized, and open supply. Nearly all of decentralized purposes (dApps) hosted on the Fantom platform lack an analytics web page that gives data to the customers. Subsequently, we want to construct an information platform that helps an internet interface that shall be made public. It will enable customers to seek for a wise contract tackle. The applying then shows key metrics for that good contract. Such an analytics platform can provide insights and tendencies for purposes deployed on the platform to the customers, whereas the builders can proceed to concentrate on enhancing their dApps.
AWS Information Lab gives accelerated, joint-engineering engagements between clients and AWS technical assets to create tangible deliverables that speed up knowledge and analytics modernization initiatives. Information Lab has three choices: the Construct Lab, the Design Lab, and a Resident Architect. The Construct Lab is a 2–5 day intensive construct with a technical buyer workforce. The Design Lab is a half-day to 2-day engagement for purchasers who want a real-world structure advice primarily based on AWS experience, however aren’t but able to construct. Each engagements are hosted both on-line or at an in-person AWS Information Lab hub. The Resident Architect supplies AWS clients with technical and strategic steerage in refining, implementing, and accelerating their knowledge technique and options over a 6-month engagement.
On this put up, we share the expertise of our engagement with AWS Information Lab to speed up the initiative of creating an information pipeline from an thought to an answer. Over 4 weeks, we carried out technical design classes, reviewed structure choices, and constructed the proof of idea knowledge pipeline.
Use case assessment
The method began with us participating with our AWS Account workforce to submit a nomination for the info lab. This adopted by a name with the AWS Information Lab workforce to evaluate the suitability of necessities towards this system. After the Construct Lab was scheduled, an AWS Information Lab Architect engaged with us to conduct a sequence of pre-lab calls to finalize the scope, structure, targets, and success standards for the lab. The scope was to design an information pipeline that will ingest and retailer historic and real-time on-chain transactions knowledge, and construct an information pipeline to generate key metrics. As soon as ingested, knowledge must be remodeled, saved, and uncovered through REST-based APIs and consumed by an internet UI to show key metrics. For this Construct Lab, we select to ingest knowledge for Spooky, which is a decentralized trade (DEX) deployed on the Fantom platform and had the biggest Whole Worth Locked (TVL) at the moment. Key metrics such variety of wallets which have interacted with the dApp over time, variety of tokens and their worth exchanged for the dApp over time, and variety of transactions for the dApp over time have been chosen to visualise by a web-based UI.
We explored a number of structure choices and picked one for the lab that aligned intently with our finish objective. The full historic knowledge for the chosen good contract was roughly 1 GB since deployment of dApp on the Fantom platform. We used FTMScan, which permits us to discover and search on the Fantom platform for transactions, to estimate the speed of switch transactions to be roughly three to 4 per minute. This allowed us to design an structure for the lab that may deal with this knowledge ingestion price. We agreed to make use of an present utility often known as the knowledge producer that was developed internally by the Fantom workforce to ingest on-chain transactions in actual time. On checking transactions’ payload dimension, it was discovered to not exceed 100 kb for every transaction, which gave us the measure of variety of information that shall be created as soon as ingested by the info producer utility. A call was made to ingest the previous 45 days of historic transactions to populate the platform with sufficient knowledge to visualise key metrics. As a result of the function of backdating exists inside the knowledge producer utility, we agreed to make use of that. The Information Lab Architect additionally suggested us to think about using AWS Database Migration Service (AWS DMS) to ingest historic transactions knowledge put up lab. As a final step, we determined to construct a React-based webpage with Materials-UI that permits customers to enter a wise contract tackle and select the time interval, and the app fetches the mandatory knowledge to point out the metrics worth.
Resolution overview
We collectively agreed to include the next design ideas for the info lab structure:
- Simplified knowledge pipelines
- Decentralized knowledge structure
- Decrease latency as a lot as doable
The next diagram illustrates the structure that we constructed within the lab.
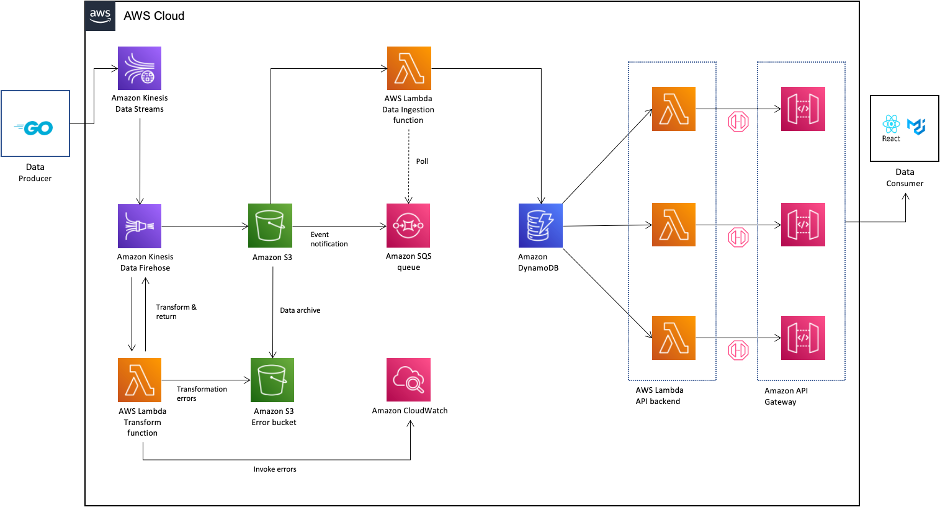
We collectively outlined the next success standards for the Construct Lab:
- Finish-to-end knowledge streaming pipeline to ingest on-chain transactions
- Historic knowledge ingestion of the chosen good contract
- Information storage and processing of on-chain transactions
- REST-based APIs to offer time-based metrics for the three outlined use circumstances
- A pattern net UI to show aggregated metrics for the good contract
Previous to the Construct Lab
As a prerequisite for the lab, we configured the info producer utility to make use of the AWS Software program Improvement Equipment (AWS SDK) and PUTRecords API operation to ship transactions knowledge to an Amazon Easy Storage Service (Amazon S3) bucket. For the Construct Lab, we constructed further logic inside the utility to ingest historic transactions knowledge along with real-time transactions knowledge. As a final step, we verified that transactions knowledge was captured and ingested right into a check S3 bucket.
AWS providers used within the lab
We used the next AWS providers as a part of the lab:
- AWS Id and Entry Administration (IAM) – We created a number of IAM roles with acceptable belief relationships and obligatory permissions that can be utilized by a number of providers to learn and write on-chain transactions knowledge and generated logs.
- Amazon S3 – We created an S3 bucket to retailer the incoming transactions knowledge as JSON-based information. We created a separate S3 bucket to retailer incoming transaction knowledge that didn’t be remodeled and shall be reprocessed later.
- Amazon Kinesis Information Streams – We created a brand new Kinesis knowledge stream in on-demand mode, which robotically scales primarily based on knowledge ingestion patterns and supplies hands-free capability administration. This stream was utilized by the info producer utility to ingest historic and real-time on-chain transactions. We mentioned being able to handle and predict value, and due to this fact have been suggested to make use of the provisioned mode when dependable estimates have been accessible for throughput necessities. We have been additionally suggested to proceed to make use of on-demand mode till the info visitors patterns have been unpredictable.
- Amazon Kinesis Information Firehose – We created a Firehose supply stream to remodel the incoming knowledge and writes it to the S3 bucket. To reduce latency, we set the supply stream buffer dimension to 1 MiB and buffer interval to 60 seconds. This could guarantee a file is written to the S3 bucket when both of the 2 circumstances are glad whatever the order. Transactions knowledge written to the S3 bucket was in JSON Traces format.
- Amazon Easy Queue Service (Amazon SQS) – We arrange an SQS queue of the kind Commonplace and an entry coverage for that SQS queue to permit incoming messages generated from S3 bucket occasion notifications.
- Amazon DynamoDB – So as to choose an information retailer for on-chain transactions, we would have liked a service that may retailer transactions payload of unstructured knowledge with various schemas, supplies the flexibility to cache question outcomes, and is a managed service. We picked DynamoDB for these causes. We created a single DynamoDB desk that holds the incoming transactions knowledge. After analyzing the entry question patterns, we determined to make use of the tackle subject of the good contract because the partition key and the timestamp subject as the kind key. The desk was created with auto scaling of learn and write capability modes as a result of the precise utilization necessities can be laborious to foretell at the moment.
- AWS Lambda – We created the next features:
- A Python-based Lambda perform to carry out transformations on the incoming knowledge from the info producer utility to flatten the JSON construction, convert the Unix-based epoch timestamp to a date/time worth, and convert hex-based string values to a decimal worth representing the variety of tokens.
- A second Lambda perform to parse incoming SQS queue messages. This message contained values for
bucket_nameandobject_key, which holds the reference to a newly created object inside the S3 bucket. The Lambda perform logic included parsing of this worth to acquire the reference to the S3 object, get the contents of the article, learn it into an information body object utilizing the AWS SDK for pandas (awswrangler) library, convert it right into a Pandas knowledge body object, and use the put_df API name to jot down a Pandas knowledge body object as an merchandise right into a DynamoDB desk. We select to make use of Pandas because of familiarity with the library and features required to carry out knowledge remodel operations. - Three separate Lambda features that incorporates the logic to question the DynamoDB desk and retrieve gadgets to combination and calculate metrics values. This calculated metrics worth inside the Lambda perform was formatted as an HTTP response to show as REST-based APIs.
- Amazon API Gateway – We created a REST primarily based API endpoint that makes use of Lambda proxy integration to go a wise contract tackle and time-based interval in minutes as a question string parameter to the backend Lambda perform. The response from the Lambda perform was a metrics worth. We additionally enabled cross-origin useful resource sharing (CORS) help inside API Gateway to efficiently question from the online UI that resides in a special area.
- Amazon CloudWatch – We used a Lambda perform in-built mechanism to ship perform metrics to CloudWatch. Lambda features include a CloudWatch Logs log group and a log stream for every occasion of your perform. The Lambda runtime setting sends particulars of every invocation to the log stream, and relays logs and different output out of your perform’s code.
Iterative improvement method
Throughout 4 days of the Construct Lab, we undertook iterative improvement. We began by creating the foundational layer and iteratively added further options by testing and knowledge validation. This allowed us to develop confidence of the answer being constructed as we examined the output of the metrics by a web-based UI and verified with the precise knowledge. As errors bought found, we deleted all the dataset and reran all the roles to confirm outcomes and resolve these errors.
Lab outcomes
In 4 days, we constructed an end-to-end streaming pipeline ingesting 45 days of historic knowledge and real-time on-chain transactions knowledge for the chosen Spooky good contract. We additionally developed three REST-based APIs for the chosen metrics and a pattern net UI that permits customers to insert a wise contract tackle, select a time frequency, and visualize the metrics values. In a follow-up name, our AWS Information Lab Architect shared post-lab steerage across the subsequent steps required to productionize the answer:
- Scaling of the proof of idea to deal with bigger knowledge volumes
- Safety finest practices to guard the info whereas at relaxation and in transit
- Finest practices for knowledge modeling and storage
- Constructing an automatic resilience method to deal with failed processing of the transactions knowledge
- Incorporating excessive availability and catastrophe restoration options to deal with incoming knowledge requests, together with including of the caching layer
Conclusion
Via a brief engagement and small workforce, we accelerated this undertaking from an thought to an answer. This expertise gave us the chance to discover AWS providers and their analytical capabilities in-depth. As a subsequent step, we’ll proceed to make the most of AWS groups to boost the answer constructed throughout this lab to make it prepared for the manufacturing deployment.
Be taught extra about how the AWS Information Lab can assist your knowledge and analytics on the cloud journey.
In regards to the Authors
 Dr. Quan Hoang Nguyen is at present a CTO at Fantom Basis. His pursuits embrace DLT, blockchain applied sciences, visible analytics, compiler optimization, and transactional reminiscence. He has expertise in R&D on the College of Sydney, IBM, Capital Markets CRC, Smarts – NASDAQ, and Nationwide ICT Australia (NICTA).
Dr. Quan Hoang Nguyen is at present a CTO at Fantom Basis. His pursuits embrace DLT, blockchain applied sciences, visible analytics, compiler optimization, and transactional reminiscence. He has expertise in R&D on the College of Sydney, IBM, Capital Markets CRC, Smarts – NASDAQ, and Nationwide ICT Australia (NICTA).
 Ankit Patira is a Information Lab Architect at AWS primarily based in Melbourne, Australia.
Ankit Patira is a Information Lab Architect at AWS primarily based in Melbourne, Australia.

{kind=link}