

Cloudera just lately launched a completely featured Open Knowledge Lakehouse, powered by Apache Iceberg within the personal cloud, along with what’s already been out there for the Open Knowledge Lakehouse within the public cloud since final 12 months. This launch signified Cloudera’s imaginative and prescient of Iceberg in every single place. Clients can deploy Open Knowledge Lakehouse wherever the info resides—any public cloud, personal cloud, or hybrid cloud, and port workloads seamlessly throughout deployments.
With Cloudera Open Knowledge Lakehouse within the personal cloud, you possibly can profit from following key options:
- Multi-engine interoperability and compatibility with Apache Iceberg, together with NiFi, Flink and SQL Stream Builder (SSB), Spark, and Impala.
- Time Journey: Reproduce a question as of a given time or snapshot ID, which can be utilized for historic audits, validating ML fashions, and rollback of inaccurate operations, for example.
- Desk Rollback: Permit customers to rapidly appropriate issues by resetting tables to an excellent state.
- Wealthy set of SQL (question, DDL, DML) instructions: Create or manipulate database objects, run queries, load and modify information, carry out time journey operations, and convert Hive exterior tables to Iceberg tables utilizing SQL instructions.
- In-place desk (schema, partition) evolution: Effortlessly evolve Iceberg desk schema and partition layouts with out rewriting desk information or migrating to a brand new desk, for instance.
- SDX Integration: Supplies frequent safety and governance insurance policies, in addition to information lineage and auditing.
- Iceberg Replication: Supplies catastrophe restoration and desk backups.
- Straightforward portability of workloads to public cloud and again with none code refactoring.
On this multi-part weblog publish, we’re going to indicate you methods to use the most recent Cloudera Iceberg innovation to construct an Open Knowledge Lakehouse on a personal cloud.
For this primary a part of the weblog sequence we are going to give attention to ingesting streaming information into the open information lakehouse and Iceberg tables making it out there for additional processing that we’ll display within the following blogs.
Answer Overview
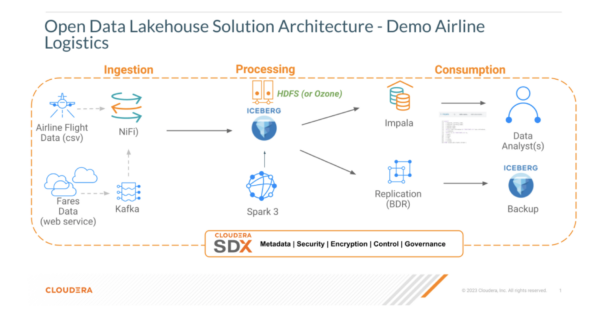
Pre-requisites
The next elements in Cloudera Open Knowledge Lakehouse on Non-public Cloud needs to be put in and configured and airline information units:
On this instance, we’re going to use NiFi as a part of CFM 2.1.6 to stream ingest information units to Iceberg. Please be aware, you can too leverage Flink and SQL Stream Builder in CSA 1.11 as properly for streaming ingestion. We use NiFi to ingest an airport route information set (JSON) and ship that information to Kafka and Iceberg. We then use Hue/Impala to try the tables we created.
Please reference consumer documentation for set up and configuration of Cloudera Knowledge Platform Non-public Cloud Base 7.1.9 and Cloudera Stream Administration 2.1.6.
Observe the steps beneath for utilizing NiFi to stream ingest information into Iceberg tables:
1- Create the routes Iceberg desk for NiFi ingestion in Hue/Impala execute the next DDL:

2- Obtain a pre-built move definition file discovered right here:
https://github.com/jingalls1217/airways/blob/principal/Datapercent20Flow/NiFiDemo.json
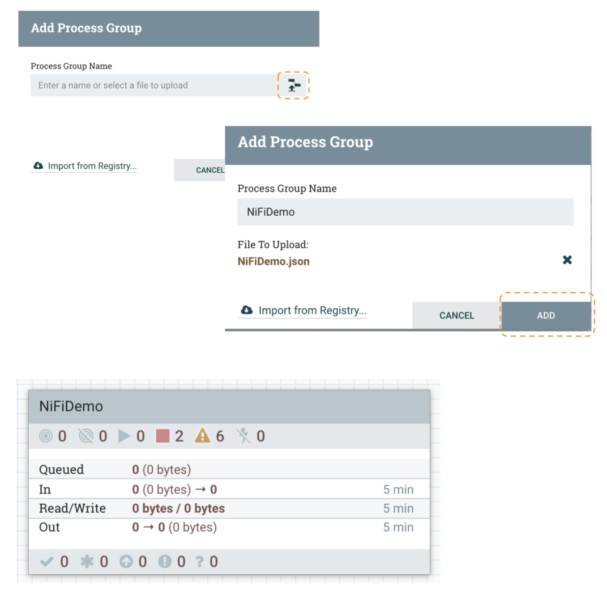
3-Create a brand new course of group in NiFi and add the move definition file downloaded in step 2. First click on the Browse button, choose the NiFiDemo.json file and click on the Add button.
4- Replace parameters as proven in desk beneath:

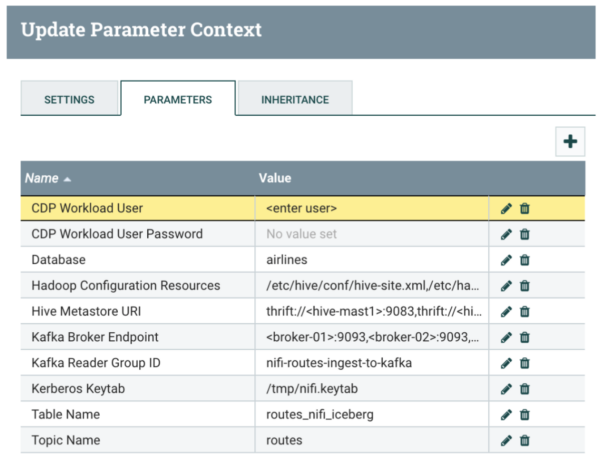
5- Click on into the NiFiDemo course of group:
-
- Proper click on on the NiFi canvas, go to Configuration and allow the Controller Companies.
- Open every Course of Group and proper click on on the canvas, go to Configuration and Allow any extra Controller Companies not but enabled.
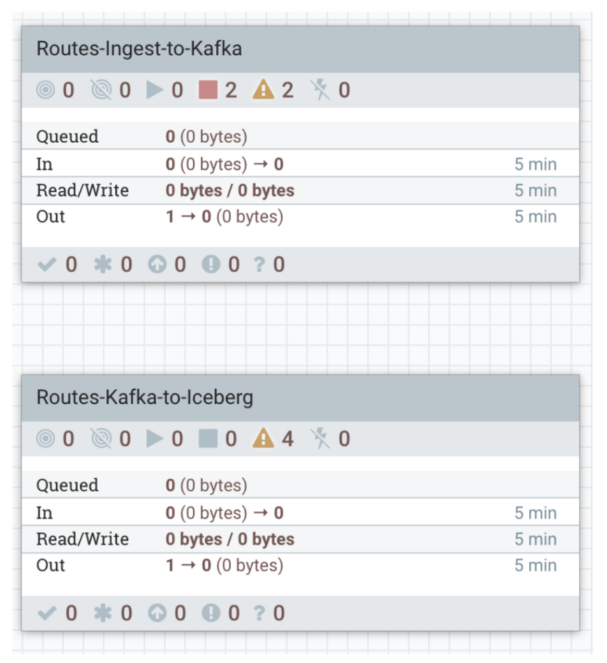
6- Begin the Routes ingest to Kafka move and monitor success/failure queues:
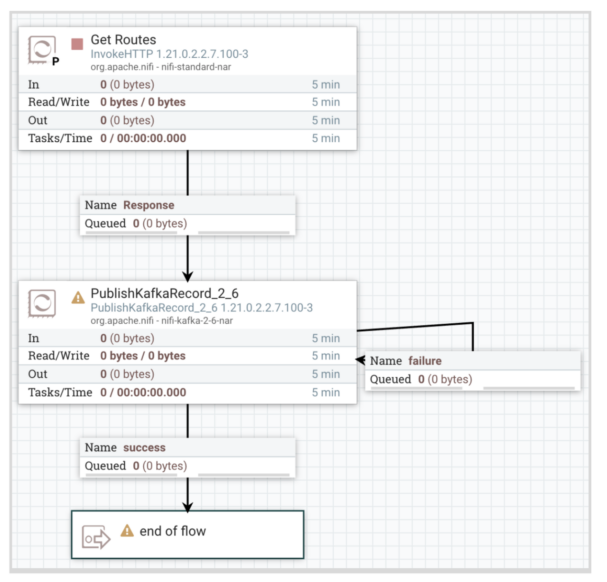
7- Begin the Routes Kafka to Iceberg move and monitor success/failure queues:
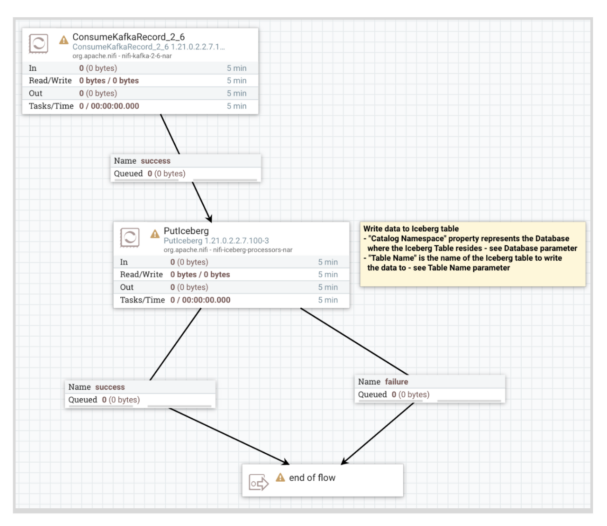
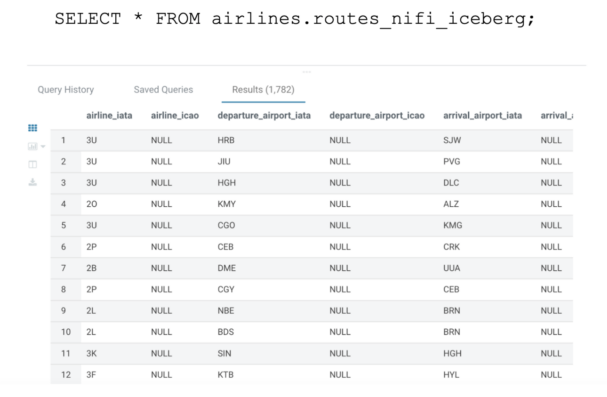
8- Examine the Routes Iceberg desk in Hue/Impala to see the info that has been loaded:
SELECT * FROM airways.routes_nifi_iceberg;
Conclusion
On this first weblog, we confirmed methods to use Cloudera Stream Administration (NiFi) to stream ingest information on to the Iceberg desk with none coding. Keep tuned for half two, Knowledge Processing with Apache Spark.
To construct an Open Knowledge Lakehouse in your personal cloud, obtain Cloudera Knowledge Platform Non-public Cloud Base 7.1.9 and comply with our Getting Began weblog sequence.
And since we provide the very same expertise in the private and non-private cloud you can too be part of one in every of our Two hour hands-on-lab workshops to expertise the open information lakehouse within the public cloud or join a free trial. If you’re excited about chatting about Cloudera Open Knowledge Lakehouse, contact your account group. As at all times, we welcome your suggestions within the feedback part beneath.

{kind=link}