

In the present day, lots of of 1000’s of shoppers use information lakes for analytics and machine studying. Nonetheless, information engineers must cleanse and put together this information earlier than it may be used. The underlying information needs to be correct and up to date for buyer to make assured enterprise selections. In any other case, information shoppers lose belief within the information and make suboptimal or incorrect selections. It’s a frequent process for information engineers to judge whether or not the info is correct and up to date or not. In the present day there are numerous information high quality instruments. Nonetheless, frequent information high quality instruments often require guide processes to observe information high quality.
AWS Glue Knowledge High quality is a preview characteristic of AWS Glue that measures and screens the info high quality of Amazon Easy Storage Service (Amazon S3) information lakes and in AWS Glue extract, remodel, and cargo (ETL) jobs. That is an open preview characteristic so it’s already enabled in your account within the obtainable Areas. You’ll be able to simply outline and measure the info high quality checks in AWS Glue Studio console with out writing codes. It simplifies your expertise of managing information high quality.
This put up is Half 2 of a four-post sequence to clarify how AWS Glue Knowledge High quality works. Take a look at the earlier put up on this sequence:
On this put up, we present how you can create an AWS Glue job that measures and screens the info high quality of a knowledge pipeline. We additionally present how you can take motion based mostly on the info high quality outcomes.
Resolution overview
Let’s think about an instance use case by which a knowledge engineer must construct a knowledge pipeline to ingest the info from a uncooked zone to a curated zone in a knowledge lake. As a knowledge engineer, one in every of your key duties—together with extracting, reworking, and loading information—is validating the standard of information. Figuring out information high quality points upfront helps you stop inserting dangerous information within the curated zone and keep away from arduous information corruption incidents.
On this put up, you’ll discover ways to simply arrange built-in and customized information validation checks in your AWS Glue job to stop dangerous information from corrupting the downstream high-quality information.
The dataset used for this put up is synthetically generated; the next screenshot reveals an instance of the info.

Arrange sources with AWS CloudFormation
This put up consists of an AWS CloudFormation template for a fast setup. You’ll be able to evaluate and customise it to fit your wants.
The CloudFormation template generates the next sources:
- An Amazon Easy Storage Service (Amazon S3) bucket (
gluedataqualitystudio-*). - The next prefixes and objects within the S3 bucket:
datalake/uncooked/buyer/buyer.csvdatalake/curated/buyer/scripts/sparkHistoryLogs/non permanent/
- AWS Identification and Entry Administration (IAM) customers, roles, and insurance policies. The IAM function (
GlueDataQualityStudio-*) has permission to learn and write from the S3 bucket. - AWS Lambda capabilities and IAM insurance policies required by these capabilities to create and delete this stack.
To create your sources, full the next steps:
- Sign up to the AWS CloudFormation console within the
us-east-1Area. - Select Launch Stack:

- Choose I acknowledge that AWS CloudFormation may create IAM sources.
- Select Create stack and watch for the stack creation step to finish.

Implement the answer
To start out configuring your answer, full the next steps:
- On the AWS Glue Studio console, select Jobs within the navigation pane.

- Choose Visible with a clean canvas and select Create.

- Select the Job Particulars tab to configure the job.

- For Title, enter
GlueDataQualityStudio. - For IAM Position, select the function beginning with
GlueDataQualityStudio-*. - For Glue model, select Glue 3.0.
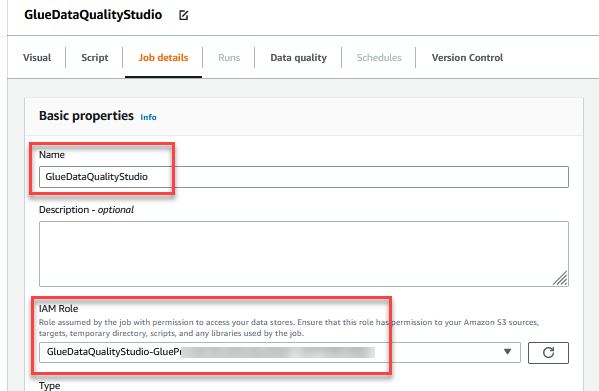
- For Job bookmark, select Disable. This lets you run this job a number of instances with the identical enter dataset.
- For Variety of retries, enter
0.
- Within the Superior properties part, present the S3 bucket created by the CloudFormation template (beginning with
gluedataqualitystudio-*).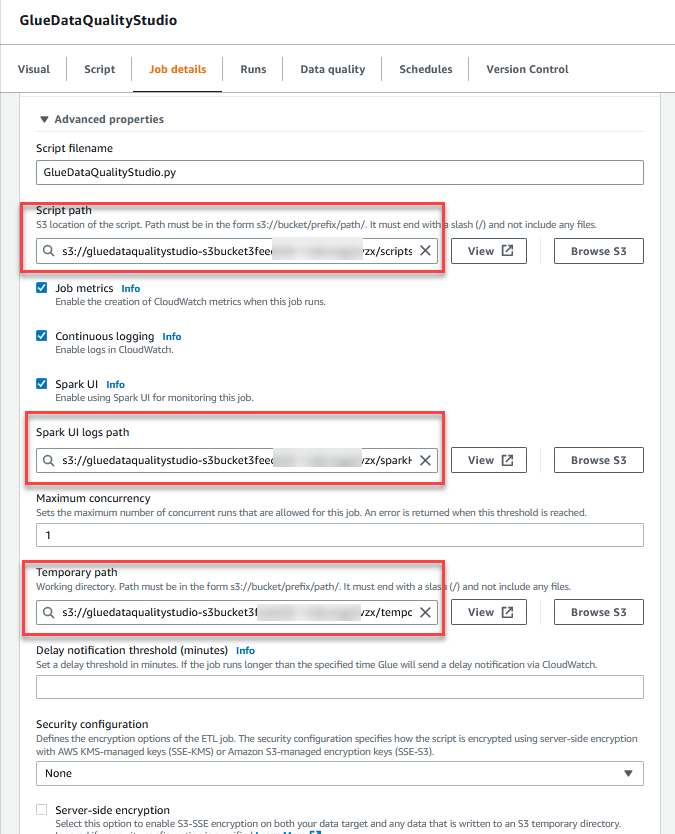
- Select Save.

- After the job is saved, select the Visible tab and on the Supply menu, select Amazon S3.
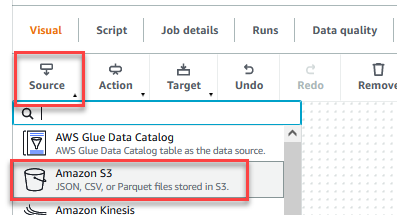
- On the Knowledge supply properties – S3 tab, for S3 supply sort, choose S3 location.
- Select Browse S3 and navigate to prefix
/datalake/uncooked/buyer/within the S3 bucket beginning withgluedataqualitystudio-*. - Select Infer schema.

- On the Motion menu, select Consider Knowledge High quality.
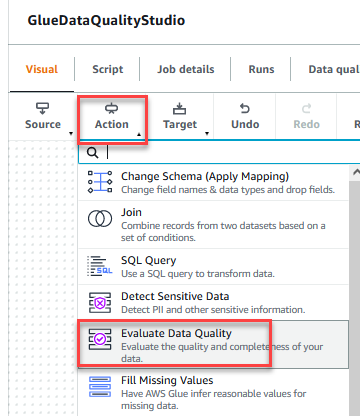
- Select the Consider Knowledge High quality node.

On the Remodel tab, now you can begin constructing information high quality guidelines. The primary rule you create is to examine ifCustomer_IDis exclusive and never null utilizing theisPrimaryKeyrule. - On the Rule sorts tab of the DQDL rule builder, seek for
isprimarykeyand select the plus signal.
- On the Schema tab of the DQDL rule builder, select the plus signal subsequent to
Customer_ID. - Within the rule editor, delete
id.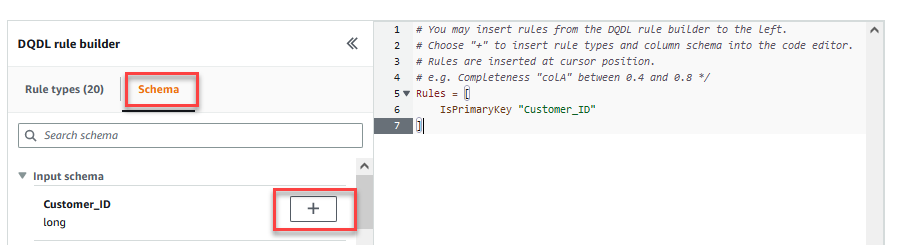
The subsequent rule we add checks that theFirst_Namecolumn worth is current for all of the rows. - You can even enter the info high quality guidelines straight within the rule editor. Add a comma (,) and enter
IsComplete "First_Name",after the primary rule.
Subsequent, you add a customized rule to validate that no row exists with outPhoneorE-mail. - Enter the next customized rule within the rule editor:

The Consider Knowledge High quality characteristic gives actions to handle the end result of a job based mostly on the job high quality outcomes. - For this put up, choose Fail job when information high quality fails and select Fail job with out loading goal information actions. Within the Knowledge high quality output setting part, select Browse S3 and navigate to prefix
dqresultswithin the S3 bucket beginning withgluedataqualitystudio-*.
- On the Goal menu, select Amazon S3.

- Select the Knowledge goal – S3 bucket node.
- On the Knowledge goal properties – S3 tab, for Format, select Parquet, and for Compression Sort, select Snappy.
- For S3 Goal Location, select Browse S3 and navigate to the prefix
/datalake/curated/buyer/within the S3 bucket beginning withgluedataqualitystudio-*.
- Select Save, then select Run.
 You’ll be able to view the job run particulars on the Runs tab. In our instance, the job fails with the error message “AssertionError: The job failed because of failing DQ guidelines for node: <node>.”
You’ll be able to view the job run particulars on the Runs tab. In our instance, the job fails with the error message “AssertionError: The job failed because of failing DQ guidelines for node: <node>.” You’ll be able to evaluate the info high quality outcome on the Knowledge high quality tab. In our instance, the customized information high quality validation failed as a result of one of many rows within the dataset had no
You’ll be able to evaluate the info high quality outcome on the Knowledge high quality tab. In our instance, the customized information high quality validation failed as a result of one of many rows within the dataset had no PhoneorE-mailworth. Consider Knowledge High quality outcomes can be written to the S3 bucket in JSON format based mostly on the info high quality outcome location parameter of the node.
Consider Knowledge High quality outcomes can be written to the S3 bucket in JSON format based mostly on the info high quality outcome location parameter of the node. - Navigate to
dqresultsprefix below the S3 bucket beginninggluedataqualitystudio-*. You will note that the info high quality result’s partitioned by date.
The next is the output of the JSON file. You need to use this file output to construct customized information high quality visualization dashboards.

You can even monitor the Consider Knowledge High quality node by way of Amazon CloudWatch metrics and set alarms to ship notifications about information high quality outcomes. To be taught extra on how you can arrange CloudWatch alarms, consult with Utilizing Amazon CloudWatch alarms.

Clear up
To keep away from incurring future prices and to scrub up unused roles and insurance policies, delete the sources you created:
- Delete the
GlueDataQualityStudiojob you created as a part of this put up. - On the AWS CloudFormation console, delete the
GlueDataQualityStudiostack.
Conclusion
AWS Glue Knowledge High quality gives a straightforward approach to measure and monitor the info high quality of your ETL pipeline. On this put up, you discovered how you can take mandatory actions based mostly on the info high quality outcomes, which helps you preserve excessive information requirements and make assured enterprise selections.
To be taught extra about AWS Glue Knowledge High quality, take a look at the documentation:
In regards to the Authors
 Deenbandhu Prasad is a Senior Analytics Specialist at AWS, specializing in massive information providers. He’s keen about serving to prospects construct trendy information structure on the AWS Cloud. He has helped prospects of all sizes implement information administration, information warehouse, and information lake options.
Deenbandhu Prasad is a Senior Analytics Specialist at AWS, specializing in massive information providers. He’s keen about serving to prospects construct trendy information structure on the AWS Cloud. He has helped prospects of all sizes implement information administration, information warehouse, and information lake options.
 Yannis Mentekidis is a Senior Software program Growth Engineer on the AWS Glue group.
Yannis Mentekidis is a Senior Software program Growth Engineer on the AWS Glue group.

{kind=link}