
Apache Spark is an open-source mission that was began at UC Berkeley AMPLab. It has an in-memory computing framework that enables it to course of knowledge workloads in batch and in real-time. Although Spark is written in Scala, you’ll be able to work together with Spark with a number of languages like Spark, Python, and Java.
Listed here are some examples of the issues you are able to do in your apps with Apache Spark:
- Construct steady ETL pipelines for stream processing
- SQL BI and analytics
- Do machine studying, and way more!
Since Spark helps SQL queries that may assist with knowledge analytics, you’re most likely pondering why would I take advantage of Rockset  ?
?
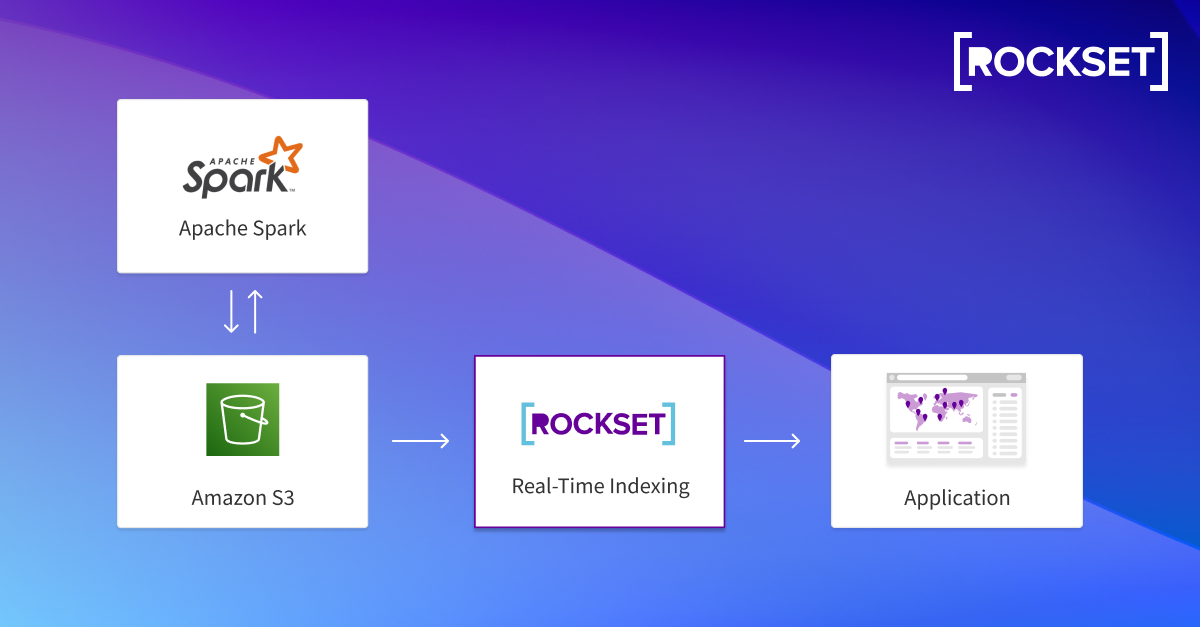
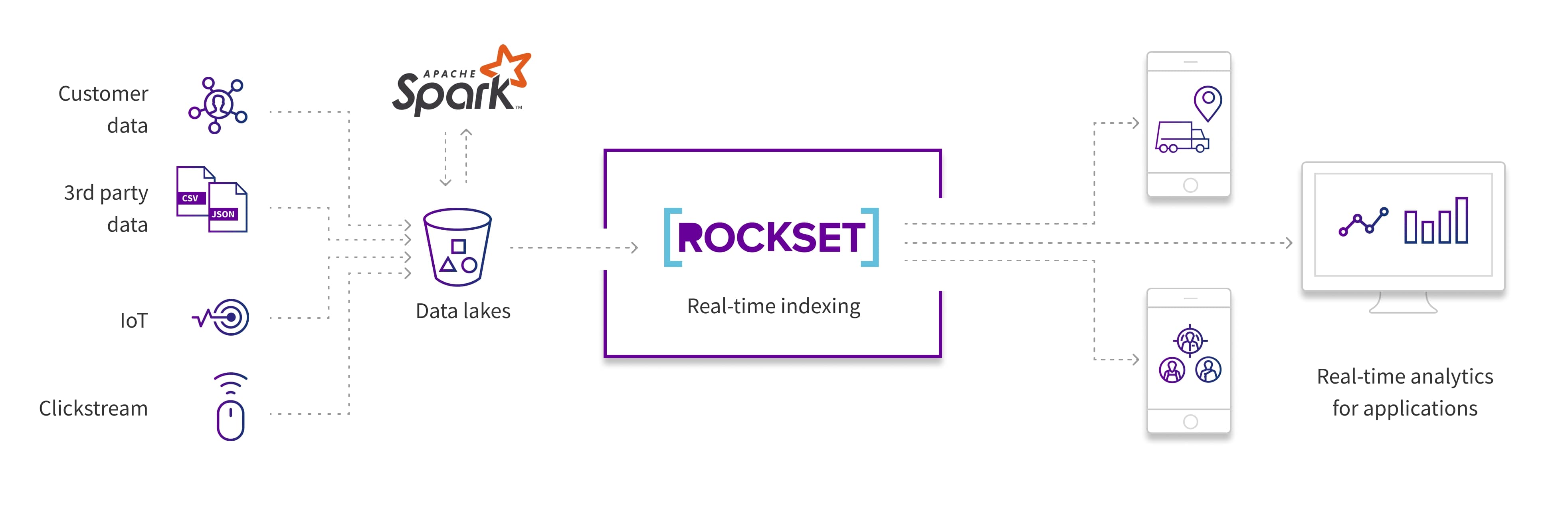
Rockset truly enhances Apache Spark for real-time analytics. If you happen to want real-time analytics for customer-facing apps, your knowledge purposes want millisecond question latency and assist for prime concurrency. When you remodel knowledge in Apache Spark and ship it to S3, Rockset pulls knowledge from S3 and routinely indexes it by way of the Converged Index. You’ll be capable of effortlessly search, mixture, and be part of collections, and scale your apps with out managing servers or clusters.
Let’s get began with Apache Spark and Rockset  !
!
Getting began with Apache Spark
You’ll want to make sure you have Apache Spark, Scala, and the most recent Java model put in. If you happen to’re on a Mac, you’ll be capable of brew set up it, in any other case, you’ll be able to obtain the most recent launch right here. Ensure that your profile is about to the right paths for Java, Spark, and such.
We’ll additionally must assist integration with AWS. You should utilize this hyperlink to search out the right aws-java-sdk-bundle for the model of Apache Spark you’re software is utilizing. In my case, I wanted aws-java-sdk-bundle 1.11.375 for Apache Spark 3.2.0.
When you’ve obtained all the things downloaded and configured, you’ll be able to run Spark in your shell:
$ spark-shell —packages com.amazonaws:aws-java-sdk:1.11.375,org.apache.hadoop:hadoop-aws:3.2.0
Be sure you set your Hadoop configuration values from Scala:
sc.hadoopConfiguration.set("fs.s3a.entry.key","your aws entry key")
sc.hadoopConfiguration.set("fs.s3a.secret.key","your aws secret key")
val rdd1 = sc.textFile("s3a://yourPath/sampleTextFile.txt")
rdd1.rely
It is best to see a quantity present up on the terminal.
That is all nice and dandy to rapidly present that all the things is working, and also you set Spark accurately. How do you construct a knowledge software with Apache Spark and Rockset?
Create a SparkSession
First, you’ll must create a SparkSession that’ll offer you quick entry to the SparkContext:
Embedded content material: https://gist.github.com/nfarah86/1aa679c02b74267a4821b145c2bed195
Learn the S3 knowledge
After you create the SparkSession, you’ll be able to learn knowledge from S3 and remodel the info. I did one thing tremendous easy, but it surely offers you an concept of what you are able to do:
Embedded content material: https://gist.github.com/nfarah86/047922fcbec1fce41b476dc7f66d89cc
Write knowledge to S3
After you’ve reworked the info, you’ll be able to write again to S3:
Embedded content material: https://gist.github.com/nfarah86/b6c54c00eaece0804212a2b5896981cd
Connecting Rockset to Spark and S3
Now that we’ve reworked knowledge in Spark, we will navigate to the Rockset portion, the place we’ll combine with S3. After this, we will create a Rockset assortment the place it’ll routinely ingest and index knowledge from S3. Rockset’s Converged Index means that you can write analytical queries that be part of, mixture, and search with millisecond question latency.
Create a Rockset integration and assortment
On the Rockset Console, you’ll wish to create an integration to S3. The video goes over the best way to do the mixing. In any other case, you’ll be able to simply try these docs to set it up too! After you’ve created the mixing, you’ll be able to programmatically create a Rockset assortment. Within the code pattern under, I’m not polling the gathering till the standing is READY. In one other weblog put up, I’ll cowl the best way to ballot a set. For now, once you create a set, make certain on the Rockset Console, the gathering standing is Prepared earlier than you write your queries and create a Question Lambda.
Embedded content material: https://gist.github.com/nfarah86/3106414ad13bd9c45d3245f27f51b19a
Write a question and create a Question Lambda
After your assortment is prepared, you can begin writing queries and making a Question Lambda. You’ll be able to consider a Question Lambda as an API to your SQL queries:
Embedded content material: https://gist.github.com/nfarah86/f8fe11ddd6bda7ac1646efad405b0405
This beautiful a lot wraps it up! Take a look at our Rockset Neighborhood GitHub for the code used within the Twitch stream.
You’ll be able to take heed to the complete video stream. The Twitch stream covers the best way to construct a howdy world with Apache Spark <=> S3 <=> Rockset.
Have questions on this weblog put up or Apache Spark + S3 + Rockset? You’ll be able to at all times attain out on our neighborhood web page.

{kind=link}