
You have got advanced, semi-structured knowledge—nested JSON or XML, as an illustration, containing blended varieties, sparse fields, and null values. It is messy, you do not perceive the way it’s structured, and new fields seem now and again. The appliance you are implementing wants to investigate this knowledge, combining it with different datasets, to return reside metrics and really helpful actions. However how are you going to interrogate the information and body your questions appropriately for those who do not perceive the form of your knowledge? The place do you start?
Schemaless Ingest of Uncooked Knowledge
With such unwieldy knowledge, and with so many unknowns, it will be best to make use of an information administration system that provides huge flexibility at write time. SQL databases don’t match the invoice; they often require that knowledge adhere to a set schema that can’t be simply modified. Organizations will sometimes construct hard-to-maintain ETL pipelines to feed knowledge into their SQL techniques.
NoSQL techniques, however, are designed to simplify knowledge writes and will require no schema, together with minimal or no upfront knowledge transformation. Taking an identical method, to permit advanced knowledge to be written as simply as doable, Rockset helps the schemaless ingest of your uncooked knowledge.
Good Schema to Allow SQL Queries
Whereas NoSQL techniques make it easy to write down knowledge into the system, studying knowledge out in a significant means is extra sophisticated. With out a recognized schema, it will be tough to adequately body the questions you wish to ask of the information. And, considerably clearly, querying with commonplace SQL shouldn’t be an possibility within the case of NoSQL techniques.
In distinction, querying SQL techniques, which require fastened schemas, is easy and well-understood. These techniques additionally benefit from higher efficiency on analytic queries.
Recognizing that having a schema is useful, Rockset {couples} the flexibleness of schemaless ingest at write time with the effectivity of Good Schema at learn time. Consider Good Schema as Rockset’s computerized era of a schema based mostly on the precise fields and kinds current within the ingested knowledge. It could characterize semi-structured knowledge, nested objects and arrays, blended varieties, and nulls, and allow relational SQL queries over all these constructs.
Utilizing Good Schema to Analyze Uncooked Knowledge
In Rockset, semi-structured knowledge codecs akin to JSON, XML, Parquet, CSV, XLSX, and PDF are intermediate knowledge illustration codecs; they’re neither a row sort nor a column sort, in distinction to different techniques that put all JSON values, for instance, right into a single column and provide you with no visibility into it. With Rockset, the information robotically will get saved as a scalar sort, an object, or an array. Although Rockset allows you to ingest and question uncooked knowledge composed of blended varieties, all fields are dynamically typed and all subject values are strongly typed. This permits Rockset to generate a Good Schema on the information.
With Good Schema, you may question the underlying schema of knowledge ingested in its uncooked kind to get all the sector names and their varieties throughout the dataset. Moreover, you too can get the frequency distribution of every subject throughout its varied blended varieties to assist get a way of which fields are sparse and which of them can probably co-occur. This potential to completely perceive the form of the information helps customers craft advanced queries to find significant insights from their knowledge.
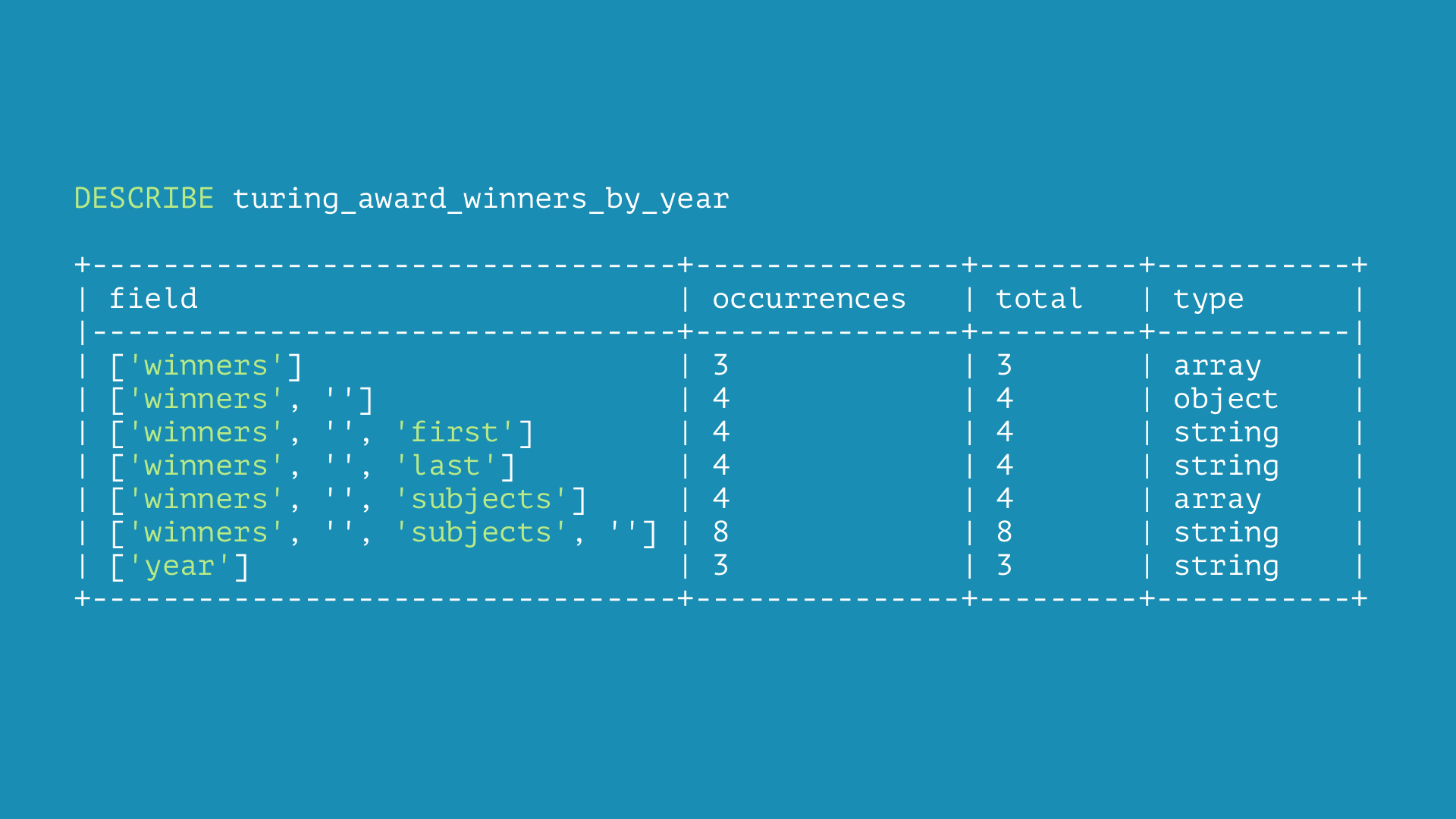
Rockset allows you to name DESCRIBE on an ingested assortment to know the underlying schema.
Utilization:
DESCRIBE <collection_name>
The output of DESCRIBE has the next fields:
- subject: Each distinct subject identify within the assortment
- sort: The knowledge sort of the sector
- occurrences: The variety of paperwork which have this subject within the given sort
- whole: Complete variety of paperwork within the assortment for high degree fields, and whole variety of paperwork which have the father or mother subject for nested fields
Let us take a look at a pattern JSON dataset that lists films and their scores throughout web sites akin to IMDB and Rotten Tomatoes (supply: https://www.kaggle.com/afzale/rating-vs-gross-collector/model/2#2018-2-4.json)
{
"12 Sturdy": {
"Style": "Motion",
"Gross": "$1,465,000",
"IMDB Metascore": "54",
"Popcorn Rating": 72,
"Ranking": "R",
"Tomato Rating": 54
},
"A Ciambra": {
"Style": "Drama",
"Gross": "unknown",
"IMDB Metascore": "70",
"Popcorn Rating": "unknown",
"Ranking": "unrated",
"Tomato Rating": "unkown"
},
"The Remaining Yr": {
"popcornscore": 48,
"ranking": "NR",
"tomatoscore": 84
}
}
This dataset has objects with nested fields, fields with blended varieties, and lacking fields.
The form of this dataset is succinctly captured under:
rockset> DESCRIBE movie_ratings
+--------------------------------------------+---------------+---------+-----------+
| subject | occurrences | whole | sort |
|--------------------------------------------+---------------+---------+-----------|
| ['12 Strong'] | 1 | 3 | object |
| ['12 Strong', 'Genre'] | 1 | 1 | string |
| ['12 Strong', 'Gross'] | 1 | 1 | string |
| ['12 Strong', 'IMDB Metascore'] | 1 | 1 | string |
| ['12 Strong', 'Popcorn Score'] | 1 | 1 | int |
| ['12 Strong', 'Rating'] | 1 | 1 | string |
| ['12 Strong', 'Tomato Score'] | 1 | 1 | int |
| ['A Ciambra'] | 1 | 3 | object |
| ['A Ciambra', 'Genre'] | 1 | 1 | string |
| ['A Ciambra', 'Gross'] | 1 | 1 | string |
| ['A Ciambra', 'IMDB Metascore'] | 1 | 1 | string |
| ['A Ciambra', 'Popcorn Score'] | 1 | 1 | string |
| ['A Ciambra', 'Rating'] | 1 | 1 | string |
| ['A Ciambra', 'Tomato Score'] | 1 | 1 | string |
| ['The Final Year'] | 1 | 3 | object |
| ['The Final Year', 'popcornscore'] | 1 | 1 | int |
| ['The Final Year', 'rating'] | 1 | 1 | string |
| ['The Final Year', 'tomatoscore'] | 1 | 1 | int |
+--------------------------------------------+---------------+---------+-----------+
Learn the way Good Schema, and the DESCRIBE command, helps you perceive and make the most of extra advanced knowledge, within the context of collections which have paperwork with every of the next properties:
In the event you’re to see Good Schema in motion, do not forget to take a look at our different weblog, Utilizing Good Schema to Speed up Insights from Nested JSON.

{kind=link}