

What’s Internet Scraping and Why is it used?
Information is a common want to unravel enterprise and analysis issues. Questionnaires, surveys, interviews, and kinds are all information assortment strategies; nevertheless, they do not fairly faucet into the largest information useful resource obtainable. The Web is a large reservoir of knowledge on each believable topic. Sadly, most web sites don’t permit the choice to avoid wasting and retain the information which could be seen on their net pages. Internet scraping solves this drawback and allows customers to scrape massive volumes of the wanted information.
Internet scraping is the automated gathering of content material and information from an internet site or every other useful resource obtainable on the web. In contrast to display scraping, net scraping extracts the HTML code below the webpage. Customers can then course of the HTML code of the webpage to extract information and perform information cleansing, manipulation, and evaluation.
Exhaustive quantities of this information may even be saved in a database for large-scale information evaluation tasks. The prominence and want for information evaluation, together with the quantity of uncooked information which could be generated utilizing net scrapers, has led to the event of tailored python packages which make net scraping straightforward as pie.
Purposes of Internet Scraping
- Sentiment evaluation: Whereas most web sites used for sentiment evaluation, equivalent to social media web sites, have APIs which permit customers to entry information, this isn’t at all times sufficient. So as to receive information in real-time concerning info, conversations, analysis, and developments it’s usually extra appropriate to net scrape the information.
- Market Analysis: eCommerce sellers can observe merchandise and pricing throughout a number of platforms to conduct market analysis concerning shopper sentiment and competitor pricing. This enables for very environment friendly monitoring of rivals and value comparisons to keep up a transparent view of the market.
- Technological Analysis: Driverless automobiles, face recognition, and suggestion engines all require information. Internet Scraping usually presents priceless info from dependable web sites and is among the most handy and used information assortment strategies for these functions.
- Machine Studying: Whereas sentiment evaluation is a well-liked machine studying algorithm, it’s only certainly one of many. One factor all machine studying algorithms have in widespread, nevertheless, is the massive quantity of knowledge required to coach them. Machine studying fuels analysis, technological development, and total development throughout all fields of studying and innovation. In flip, net scraping can gasoline information assortment for these algorithms with nice accuracy and reliability.
Understanding the Function of Selenium and Python in Scraping
Python has libraries for nearly any goal a person can suppose up, together with libraries for duties equivalent to net scraping. Selenium contains a number of completely different open-source tasks used to hold out browser automation. It helps bindings for a number of in style programming languages, together with the language we might be utilizing on this article: Python.
Initially, Selenium with Python was developed and used primarily for cross-browser testing; nevertheless, over time extra artistic use circumstances equivalent to selenium and python net scrapping have been discovered.
Selenium makes use of the Webdriver protocol to automate processes on numerous in style browsers equivalent to Firefox, Chrome, and Safari. This automation could be carried out domestically (for functions equivalent to testing an internet web page) or remotely (for net scraping).
Instance: Internet Scraping the Title and all Cases of a Key phrase from a Specified URL
The overall course of adopted when performing net scraping is:
- Use the webdriver for the browser getting used to get a selected URL.
- Carry out automation to acquire the data required.
- Obtain the content material required from the webpage returned.
- Carry out information parsing and manipulation on the content material.
- Reformat, if wanted, and retailer the information for additional evaluation.
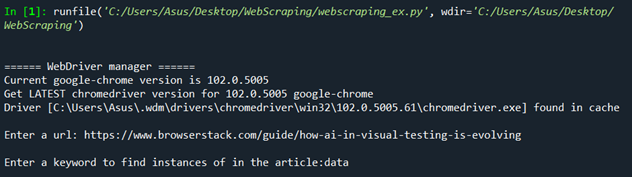
On this instance, person enter is taken for the URL of an article. Selenium is used together with BeautifulSoup to scrape after which perform information manipulation to acquire the title of the article, and all cases of a person enter key phrase present in it. Following this, a depend is taken of the variety of circumstances discovered of the key phrase, and all this textual content information is saved and saved in a textual content file referred to as article_scraping.txt.
Find out how to carry out Internet Scraping utilizing Selenium and Python
Pre-Requisites:
- Arrange a Python Atmosphere.
- Set up Selenium v4. In case you have conda or anaconda arrange then utilizing the pip package deal installer can be essentially the most environment friendly technique for Selenium set up. Merely run this command (on anaconda immediate, or instantly on the Linux terminal):
pip set up selenium
- Obtain the most recent WebDriver for the browser you want to use, or set up webdriver_manager by working the command, additionally set up BeautifulSoup:
pip set up webdriver_manager
pip set up beautifulsoup4
Step 1: Import the required packages.
from selenium import webdriverfrom selenium.webdriver.chrome.service import Servicefrom selenium.webdriver.help.ui import WebDriverWaitfrom selenium.webdriver.help import expected_conditions as ECfrom bs4 import BeautifulSoupimport codecsimport refrom webdriver_manager.chrome import ChromeDriverManager
Selenium is required in an effort to perform net scraping and automate the chrome browser we’ll be utilizing. Selenium makes use of the webdriver protocol, subsequently the webdriver supervisor is imported to acquire the ChromeDriver suitable with the model of the browser getting used. BeautifulSoup is required as an HTML parser, to parse the HTML content material we scrape. Re is imported in an effort to use regex to match our key phrase. Codecs are used to jot down to a textual content file.
Step 2: Get hold of the model of ChromeDriver suitable with the browser getting used.
driver=webdriver.Chrome(service=Service(ChromeDriverManager().set up()))
Step 3: Take the person enter to acquire the URL of the web site to be scraped, and net scrape the web page.
val = enter("Enter a url: ")wait = WebDriverWait(driver, 10)driver.get(val)
get_url = driver.current_url
wait.till(EC.url_to_be(val))
if get_url == val:
page_source = driver.page_source
The motive force is used to get this URL and a wait command is used in an effort to let the web page load. Then a verify is completed utilizing the present URL technique to make sure that the proper URL is being accessed.
Step 4: Use BeautifulSoup to parse the HTML content material obtained.
soup = BeautifulSoup(page_source,options="html.parser")
key phrase=enter("Enter a key phrase to seek out cases of within the article:")
matches = soup.physique.find_all(string=re.compile(key phrase))len_match = len(matches)title = soup.title.textual content
The HTML content material net scraped with Selenium is parsed and made right into a soup object. Following this, person enter is taken for a key phrase for which we’ll search the article’s physique. The key phrase for this instance is “information“. The physique tags within the soup object are looked for all cases of the phrase “information” utilizing regex. Lastly, the textual content within the title tag discovered inside the soup object is extracted.
Step 4: Retailer the information collected right into a textual content file.
file=codecs.open('article_scraping.txt', 'a+')file.write(title+"n")file.write("The next are all cases of your key phrase:n")depend=1for i in matches:file.write(str(depend) + "." + i + "n")depend+=1file.write("There have been "+str(len_match)+" matches discovered for the key phrase."file.shut()driver.stop()
Use codecs to open a textual content file titled article_scraping.txt and write the title of the article into the file, following this quantity, and append all cases of the key phrase inside the article. Lastly, append the variety of matches discovered for the key phrase within the article. Shut the file and stop the motive force.
Output:
Textual content File Output:
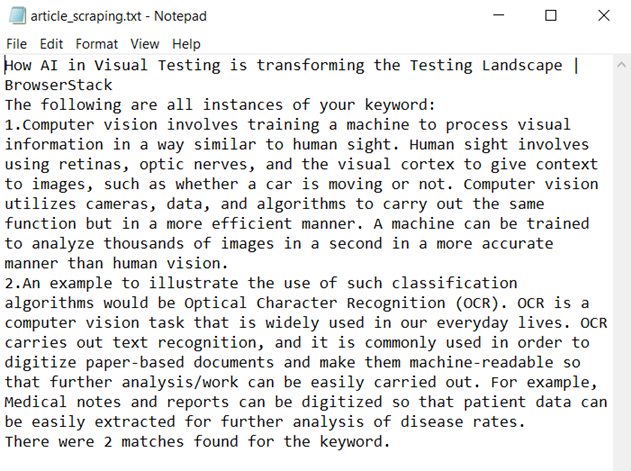
The title of the article, the 2 cases of the key phrase, and the variety of matches discovered could be visualized on this textual content file.
Find out how to use tags to effectively accumulate information from web-scraped HTML pages:
print([tag.name for tag in soup.find_all()])print([tag.text for tag in soup.find_all()])
The above code snippet can be utilized to print all of the tags discovered within the soup object and all textual content inside these tags. This may be useful to debug code or find any errors and points.
Different Options of Selenium with Python
You need to use a few of Selenium’s inbuilt options to hold out additional actions or maybe automate this course of for a number of net pages. The next are a few of the most handy options supplied by Selenium to hold out environment friendly Browser Automation and Internet Scraping with Python:
- Filling out kinds or finishing up searches
Instance of Google search automation utilizing Selenium with Python.
from selenium import webdriverfrom selenium.webdriver.chrome.service import Servicefrom webdriver_manager.chrome import ChromeDriverManagerfrom selenium.webdriver.widespread.keys import Keysfrom selenium.webdriver.widespread.by import By
driver = webdriver.Chrome(service=Service(ChromeDriverManager().set up()))
driver.get("https://www.google.com/")search = driver.find_element(by=By.NAME,worth="q")search.send_keys("Selenium")search.send_keys(Keys.ENTER)
First, the motive force hundreds google.com, which finds the search bar utilizing the identify locator. It varieties “Selenium” into the searchbar after which hits enter.
Output:
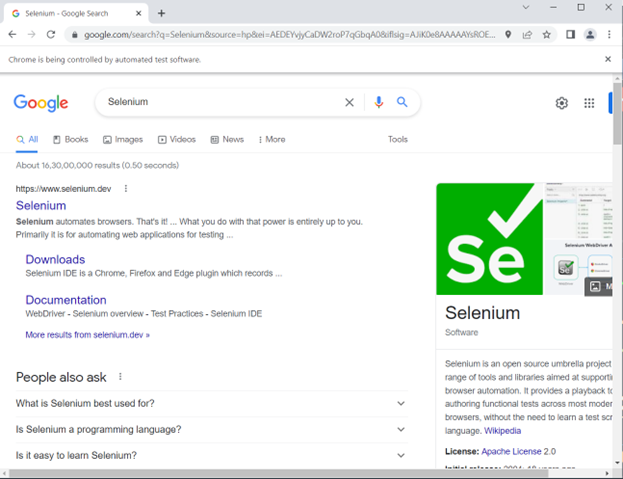
- Maximizing the window
driver.maximize_window()
- Taking Screenshots
driver.save_screenshot('article.png')
- Utilizing locators to seek out parts
For instance we do not wish to get all the web page supply and as an alternative solely wish to net scrape a choose few parts. This may be carried out through the use of Locators in Selenium.
These are a few of the locators suitable to be used with Selenium:
- Identify
- ID
- Class Identify
- Tag Identify
- CSS Selector
- XPath
Instance of scraping utilizing locators:
from selenium import webdriverfrom selenium.webdriver.chrome.service import Servicefrom selenium.webdriver.help.ui import WebDriverWaitfrom selenium.webdriver.help import expected_conditions as ECfrom selenium.webdriver.widespread.by import Byfrom webdriver_manager.chrome import ChromeDriverManager
driver = webdriver.Chrome(service=Service(ChromeDriverManager().set up()))
val = enter("Enter a url: ")
wait = WebDriverWait(driver, 10)driver.get(val)get_url = driver.current_urlwait.till(EC.url_to_be(val))if get_url == val:header=driver.find_element(By.ID, "toc0")print(header.textual content)
This instance’s enter is similar article because the one in our net scraping instance. As soon as the webpage has loaded the factor we would like is instantly retrieved through ID, which could be discovered through the use of Examine Factor.
Output:

The title of the primary part is retrieved through the use of its locator “toc0” and printed.
- Scrolling
driver.execute_script("window.scrollTo(0, doc.physique.scrollHeight);")
This scrolls to the underside of the web page and is usually useful for web sites which have infinite scrolling.
Conclusion
This information defined the method of Internet Scraping, Parsing, and Storing the Information collected. It additionally explored Internet Scraping particular parts utilizing locators in Python with Selenium. Moreover, it offered steerage on learn how to automate an internet web page in order that the specified information could be retrieved. The data offered ought to show to be of service to hold out dependable information assortment and carry out insightful information manipulation for additional downstream information evaluation.
It’s endorsed to run Selenium Exams on an actual machine cloud for extra correct outcomes because it considers actual person situations whereas working checks. With BrowserStack Automate, you may entry 3000+ actual device-browser mixtures and take a look at your net software totally for a seamless and constant person expertise.
The put up Find out how to carry out Internet Scraping utilizing Selenium and Python appeared first on Datafloq.

{kind=link}