

Extracting time collection on given geographical coordinates from satellite tv for pc or Numerical Climate Prediction information might be difficult due to the quantity of information and of its multidimensional nature (time, latitude, longitude, top, a number of parameters). Any such processing might be present in climate and local weather analysis, but additionally in functions like photovoltaic and wind energy. As an example, time collection describing the amount of photo voltaic power reaching particular geographical factors might help in designing photovoltaic energy crops, monitoring their operation, and detecting yield loss.
A generalization of the issue might be said as follows: how can we extract information alongside a dimension that’s not the partition key from a big quantity of multidimensional information? For tabular information, this downside might be simply solved with AWS Glue, which you need to use to create a job to filter and repartition the information, as proven on the finish of this publish. However what if the information is multidimensional and supplied in a domain-specific format, like within the use case that we need to sort out?
AWS Lambda is a serverless compute service that permits you to run code with out provisioning or managing servers. With AWS Step Features, you’ll be able to launch parallel runs of Lambda capabilities. This publish reveals how you need to use these companies to run parallel duties, with the instance of time collection extraction from a big quantity of satellite tv for pc climate information saved on Amazon Easy Storage Service (Amazon S3). You additionally use AWS Glue to consolidate the information produced by the parallel duties.
Observe that Lambda is a basic objective serverless engine. It has not been particularly designed for heavy information transformation duties. We’re utilizing it right here after having confirmed the next:
- Process length is predictable and is lower than quarter-hour, which is the utmost timeout for Lambda capabilities
- The use case is straightforward, with low compute necessities and no exterior dependencies that might decelerate the method
We work on a dataset supplied by EUMESAT: the MSG Complete and Diffuse Downward Floor Shortwave Flux (MDSSFTD). This dataset incorporates satellite tv for pc information at 15-minute intervals, in netcdf format, which represents roughly 100 GB for 1 12 months.
We course of the 12 months 2018 to extract time collection on 100 geographical factors.

Answer overview
To realize our purpose, we use parallel Lambda capabilities. Every Lambda operate processes 1 day of information: 96 information representing a quantity of roughly 240 MB. We then have 365 information containing the extracted information for every day, and we use AWS Glue to concatenate them for the total 12 months and break up them throughout the 100 geographical factors. This workflow is proven within the following structure diagram.

Deployment of this resolution: On this publish, we offer step-by-step directions to deploy every a part of the structure manually. If you happen to want an computerized deployment, we’ve got ready for you a Github repository containing the required infrastructure as code template.
The dataset is partitioned by day, with YYYY/MM/DD/ prefixes. Every partition incorporates 96 information that might be processed by one Lambda operate.
We use Step Features to launch the parallel processing of the twelve months of the 12 months 2018. Step Features helps builders use AWS companies to construct distributed functions, automate processes, orchestrate microservices, and create information and machine studying (ML) pipelines.
However earlier than beginning, we have to obtain the dataset and add it to an S3 bucket.
Conditions
Create an S3 bucket to retailer the enter dataset, the intermediate outputs, and the ultimate outputs of the information extraction.
Obtain the dataset and add it to Amazon S3
A free registration on the information supplier web site is required to obtain the dataset. To obtain the dataset, you need to use the next command from a Linux terminal. Present the credentials that you just obtained at registration. Your Linux terminal might be in your native machine, however you may as well use an AWS Cloud9 occasion. Just remember to have at the very least 100 GB of free storage to deal with all the dataset.
As a result of the dataset is kind of massive, this obtain might take a very long time. Within the meantime, you’ll be able to put together the subsequent steps.
When the obtain is full, you’ll be able to add the dataset to an S3 bucket with the next command:
If you happen to use non permanent credentials, they could expire earlier than the copy is full. On this case, you’ll be able to resume by utilizing the aws s3 sync command.
Now that the information is on Amazon S3, you’ll be able to delete the listing that has been downloaded out of your Linux machine.
Create the Lambda capabilities
For step-by-step directions on learn how to create a Lambda operate, discuss with Getting began with Lambda.
The primary Lambda operate within the workflow generates the listing of days that we need to course of:
We then use the Map state of Step Features to course of every day. The Map state will launch one Lambda operate for every aspect returned by the earlier operate, and can go this aspect as an enter. These Lambda capabilities might be launched concurrently for all the weather within the listing. The processing time for the total 12 months will subsequently be an identical to the time wanted to course of 1 single day, permitting scalability for very long time collection and huge volumes of enter information.
The next is an instance of code for the Lambda operate that processes every day:
You must affiliate a task to the Lambda operate to authorize it to entry the S3 buckets. As a result of the runtime is a couple of minute, you additionally should configure the timeout of the Lambda operate accordingly. Let’s set it to five minutes. We additionally improve the reminiscence allotted to the Lambda operate to 2048 MB, which is required by the netcdf4 library for extracting a number of factors at a time from satellite tv for pc information.
This Lambda operate is dependent upon the pandas and netcdf4 libraries. They are often put in as Lambda layers. The pandas library is supplied as an AWS managed layer. The netcdf4 library should be packaged in a customized layer.
Configure the Step Features workflow
After you create the 2 Lambda capabilities, you’ll be able to design the Step Features workflow within the visible editor by utilizing the Lambda Invoke and Map blocks, as proven within the following diagram.

Within the Map state block, select Distributed processing mode and improve concurrency restrict to 365 in Runtime settings. It will allow parallel processing of all the times.


The variety of Lambda capabilities that may run concurrently is restricted for every account. Your account could have inadequate quota. You possibly can request a quota improve.
Launch the state machine
Now you can launch the state machine. On the Step Features console, navigate to your state machine and select Begin execution to run your workflow.

It will set off a popup in which you’ll be able to enter non-compulsory enter on your state machine. For this publish, you’ll be able to go away the defaults and select Begin execution.

The state machine ought to take 1–2 minutes to run, throughout which period it is possible for you to to watch the progress of your workflow. You possibly can choose one of many blocks within the diagram and examine its enter, output, and different data in actual time, as proven within the following screenshot. This may be very helpful for debugging functions.
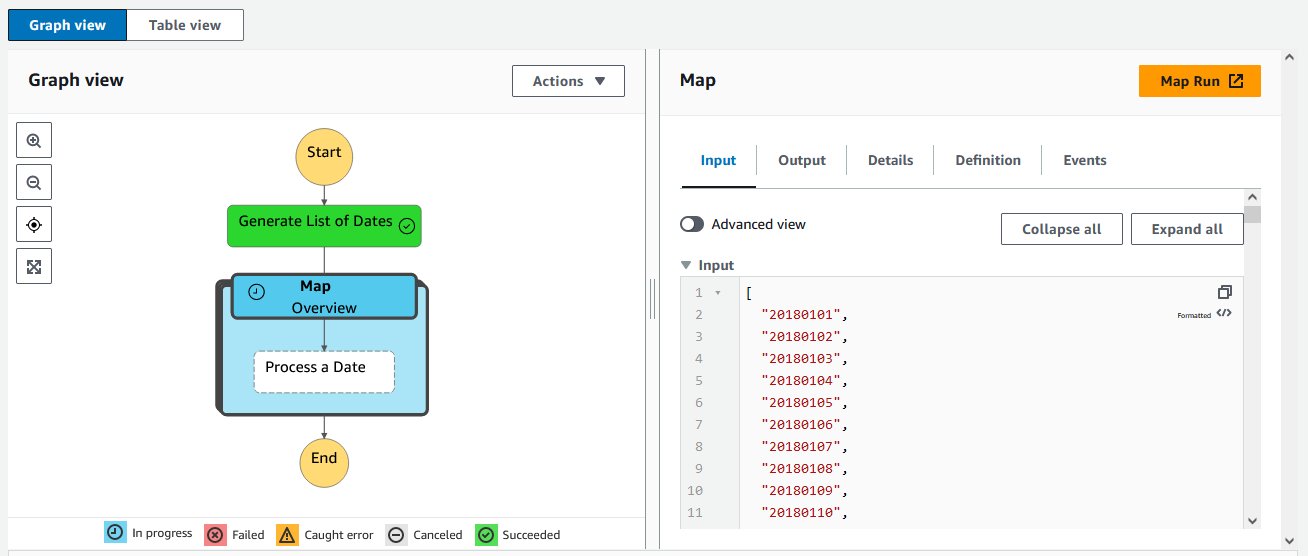
When all of the blocks flip inexperienced, the state machine is full. At this step, we’ve got extracted the information for 100 geographical factors for an entire 12 months of satellite tv for pc information.
Within the S3 bucket configured as output for the processing Lambda operate, we are able to examine that we’ve got one file per day, containing the information for all of the 100 factors.

Rework information per day to information per geographical level with AWS Glue
For now, we’ve got one file per day. Nonetheless, our purpose is to get time collection for each geographical level. This transformation entails altering the way in which the information is partitioned. From a day partition, we’ve got to go to a geographical level partition.
Fortuitously, this operation might be carried out very merely with AWS Glue.
- On the AWS Glue Studio console, create a brand new job and select Visible with a clean canvas.
For this instance, we create a easy job with a supply and goal block.
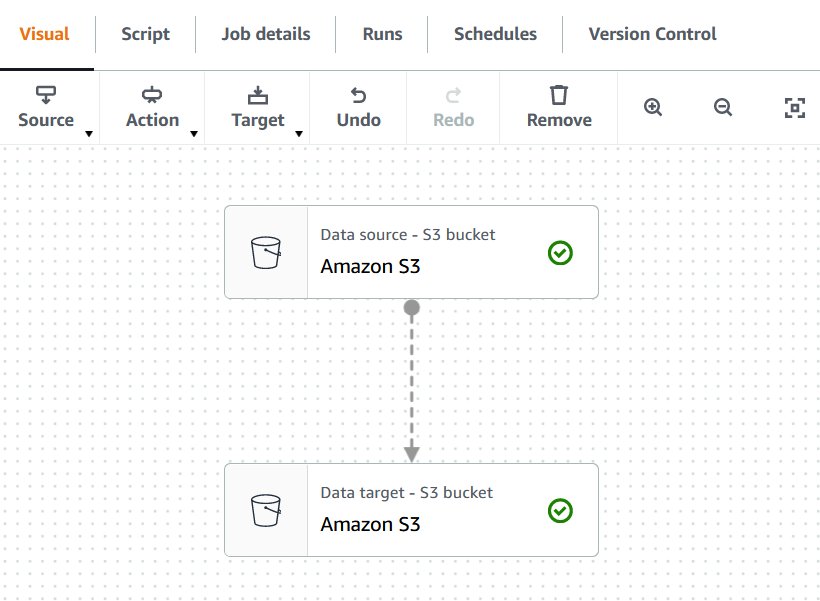
- Add a knowledge supply block.
- On the Knowledge supply properties tab, choose S3 location for S3 supply sort.
- For S3 URL, enter the situation the place you created your information within the earlier step.
- For Knowledge format, preserve the default as Parquet.
- Select Infer schema and consider the Output schema tab to substantiate the schema has been appropriately detected.
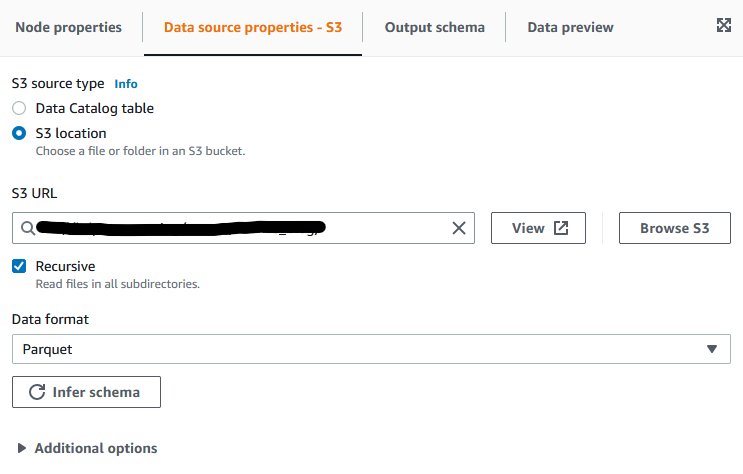
- Add a knowledge goal block.
- On the Knowledge goal properties tab, for Format, select Parquet.
- For Compression sort, select Snappy.
- For S3 Goal Location, enter the S3 goal location on your output information.
We now should configure the magic!
- Add a partition key, and select
point_id.
This tells AWS Glue the way you need your output information to be partitioned. AWS Glue will mechanically partition the output information in accordance with the point_id column, and subsequently we’ll get one folder for every geographical level, containing the entire time collection for this level as requested.
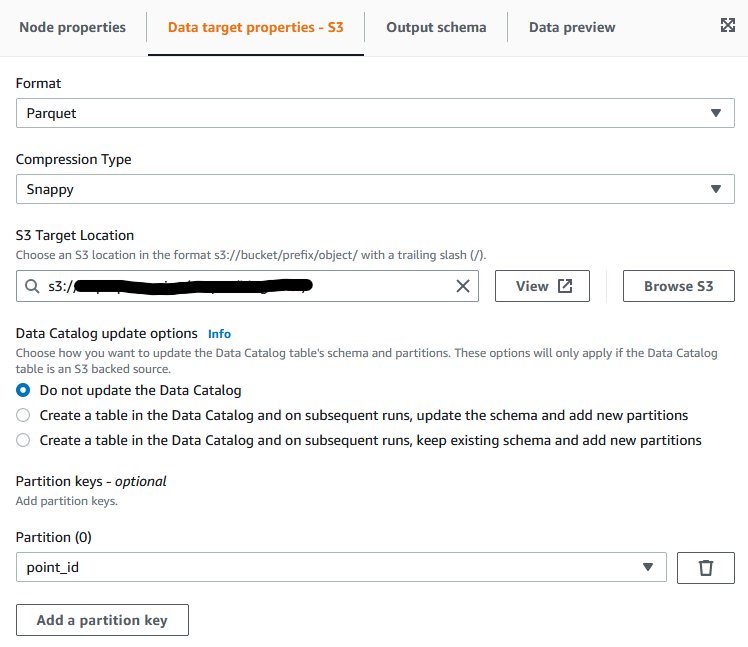
To complete the configuration, we have to assign an AWS Id and Entry Administration (IAM) function to the AWS Glue job.
- Select Job particulars, and for IAM function¸ select a task that has permissions to learn from the enter S3 bucket and to jot down to the output S3 bucket.
You might have to create the function on the IAM console when you don’t have already got an acceptable one.
- Enter a reputation for our AWS Glue job, reserve it, and run it.
We are able to monitor the run by selecting Run particulars. It ought to take 1–2 minutes to finish.
Last outcomes
After the AWS Glue job succeeds, we are able to examine within the output S3 bucket that we’ve got one folder for every geographical level, containing some Parquet information with the entire 12 months of information, as anticipated.
To load the time collection for a particular level right into a pandas information body, you need to use the awswrangler library out of your Python code:
If you wish to check this code now, you’ll be able to create a pocket book occasion in Amazon SageMaker, after which open a Jupyter pocket book. The next screenshot illustrates operating the previous code in a Jupyter pocket book.
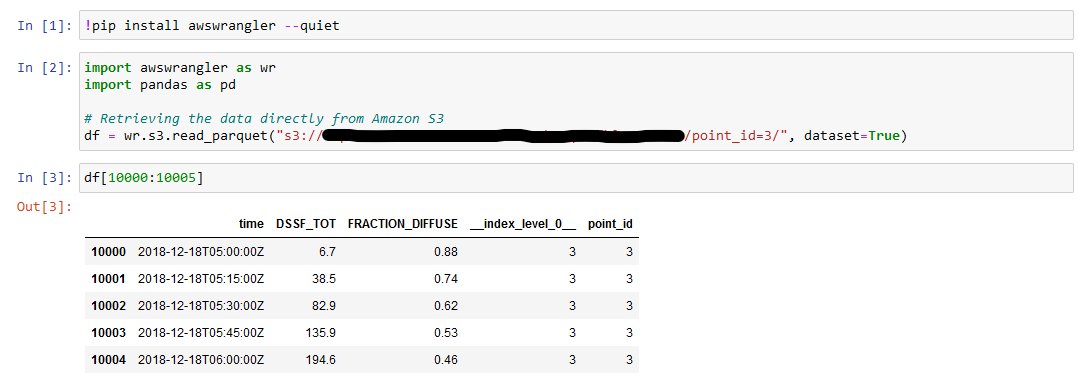
As we are able to see, we’ve got efficiently extracted the time collection for particular geographical factors!
Clear up
To keep away from incurring future prices, delete the assets that you’ve got created:
- The S3 bucket
- The AWS Glue job
- The Step Features state machine
- The 2 Lambda capabilities
- The SageMaker pocket book occasion
Conclusion
On this publish, we confirmed learn how to use Lambda, Step Features, and AWS Glue for serverless ETL (extract, remodel, and cargo) on a big quantity of climate information. The proposed structure allows extraction and repartitioning of the information in just some minutes. It’s scalable and cost-effective, and might be tailored to different ETL and information processing use instances.
Taken with studying extra concerning the companies offered on this publish? You’ll find hands-on labs to enhance your data with AWS Workshops. Moreover, take a look at the official documentation of AWS Glue, Lambda, and Step Features. It’s also possible to uncover extra architectural patterns and greatest practices at AWS Whitepapers & Guides.
In regards to the Writer

Lior Perez is a Principal Options Architect on the Enterprise staff primarily based in Toulouse, France. He enjoys supporting clients of their digital transformation journey, utilizing massive information and machine studying to assist remedy their enterprise challenges. He’s additionally personally keen about robotics and IoT, and consistently seems for brand new methods to leverage applied sciences for innovation.

{kind=link}