
Lately we have seen an enormous improve in the usage of on-demand logistics companies, reminiscent of on-line procuring and meals supply.
Most of those information purposes present a close to real-time monitoring of the ETA when you place the order. Constructing a scalable, distributed, and real-time ETA prediction system is a troublesome process, however what if we might simplify its design? We’ll break our system into items such that every part is answerable for one main job.
Let’s check out elements that represent the system.
- Supply driver/rider app – The Android/iOS app put in on a supply individual’s machine.
- Buyer app – The Android/iOS app put in on a buyer’s machine.
- Rockset – The question engine powering all of the fashions and companies.
- Message queue – Used for transferring information between numerous elements. For this instance, we’ll use Kafka.
- Key-value storage – Used for storing orders and parameters for the mannequin. For this instance, we’ll use DynamoDB.
Inputs to the Mannequin

Driver Location
To get an correct ETA estimation, you’ll need the supply individual’s place, particularly the latitude and longitude. You may get this data simply by way of GPS in a tool. A name to the machine GPS supplier returns latitude, longitude, and the accuracy of the situation in meters.
You possibly can run a background service within the app that retrieves the GPS coordinates each 10 seconds. The coordinates, as such, are too fine-grained to make a prediction. To extend the granularity of the GPS, we might be utilizing the idea of geohash. A geohash is a standardized N-letter hash of a location that represents an space of M sq. miles. N and M are inversely proportional, so a bigger N represents a smaller space M. You possibly can seek advice from this for more information on geohash.
There are tons of libraries accessible to transform latitude-longitude to geohash. Right here we’ll be utilizing geo by davidmoten to get a 6-7 letter geohash.
The service then pushes the geohash together with the coordinates to a Kafka matter. Rockset ingests information from this Kafka matter and updates it into a group known as places.
Orders
The orders positioned by a buyer are saved in DynamoDB for additional processing. An order usually goes by way of a life cycle consisting of the next states:
- CREATED
- PROCESSING
- CONFIRMED
- CANCELED
- IN TRANSIT
- DELIVERED
All the above state modifications are up to date in DynamoDB together with extra information such because the supply location, vacation spot location, order particulars, and so forth. As soon as an order is delivered, the precise time of arrival can be saved within the database.
Rockset additionally ingests updates from DynamoDB orders desk and updates it into a group known as orders.
ML Mannequin
Exponential Smoothing
We now have the precise time of arrival together with the supply and the vacation spot for order accessible from the orders desk. We’ll seek advice from it as TA. You possibly can take the imply of all of the TA with supply as supply individual’s newest location and vacation spot as buyer’s location, and you will get an approximate ETA. Nevertheless, this isn’t that correct because it would not account for altering elements, reminiscent of new development actions within the space or new shorter routes to the vacation spot.
To do this, we’d like a prediction mannequin that’s simplistic and straightforward to debug and has good accuracy.
That is the place exponential smoothing comes into play. An exponentially smoothened worth is calculated utilizing the system:
St = Alpha * Xt + (1 – Alpha) * St-1
the place
- St => Smoothened worth at time t
- Xt => Precise worth at time t
- Alpha => Smoothing issue
In our context, St represents the ETA and Xt represents the newest precise time of arrival for a source-destination pair in our orders desk.
ETAt = Alpha * TAt + (1 – Alpha) * ETAt-1
Rockset
The serving layer for the present system must fulfill three main standards:
- Means to deal with tens of millions of writes per minute – Every supply individual’s app might be pushing GPS coordinates each 5-10 seconds, which can result in a brand new ETA. A typical massive scale meals supply firm has nearly 100K supply individuals.
- The information fetch latency needs to be minimal – For an ideal UX, we should always be capable of replace ETA on the client app as quickly as it’s up to date.
- Means to deal with schema modifications on the fly – we will retailer extra metadata reminiscent of ETA prediction accuracy and mannequin model sooner or later. We do not need to create a brand new information supply each time we add a brand new discipline.
Rockset satisfies all of them. It has:
- Dynamic Scaling – Extra assets are added as and when wanted to deal with massive volumes of information.
- Distributed Question Processing – Parallelisation of queries throughout a number of nodes to reduce latency
- Schemaless Ingest – to help schema modifications on the fly.
Rockset has a built-in connector to Apache Kafka. We are able to use this Kafka connector to ingest location information of the supply individual.
To carry out exponential smoothing in Rockset, we create two Question Lambdas. Question Lambdas in Rockset are named, parameterized SQL queries saved in Rockset that may be executed from a devoted REST endpoint.
- calculate_ETA: The Question Lambda expects alpha, supply, and vacation spot as a parameter. It returns an exponentially smoothened ETA. It runs the next question to get the specified outcome:
SELECT
(:alpha * SUM(time period)) + (POW((1 - :alpha), MAX(idx))* MIN_BY(ta_i, time_i)) as ans
FROM
(
(
SELECT
order_id,
ta_i,
(ta_i * POW((1 - :alpha), (idx - 1))) AS time period,
time_i,
idx
FROM
(
SELECT
order_id,
CAST(ta AS int) as ta_i,
time_i,
ROW_NUMBER() OVER(
ORDER BY
time_i DESC, order_id ASC
) AS idx
FROM
commons.orders_fixed
WHERE
source_geohash = :supply
AND
destination_geohash = :vacation spot
ORDER BY
time_i DESC, order_id ASC
) AS idx
) AS phrases
)
- calculate_speed: This Question Lambda requires order_id as param and returns the typical velocity of the supply individual whereas in transit. It runs the next question:
SELECT
SUM(ST_DISTANCE(prev_geo, geo) /(ts - prev_ts)) / COUNT(*) AS velocity
FROM
(
SELECT
geo,
LEAD(geo, 1) OVER(
ORDER BY
ts DESC
) AS prev_geo,
ts,
LEAD(ts, 1) OVER(
ORDER BY
ts DESC
) AS prev_ts
FROM
(
SELECT
ST_GEOGPOINT(CAST(lng AS double), CAST(lat AS double)) AS geo,
order_id,
CAST(timestamp as int) AS ts
FROM
commons.places
WHERE
order_id = :order_id
) AS ts
) As velocity
Predict the ETA

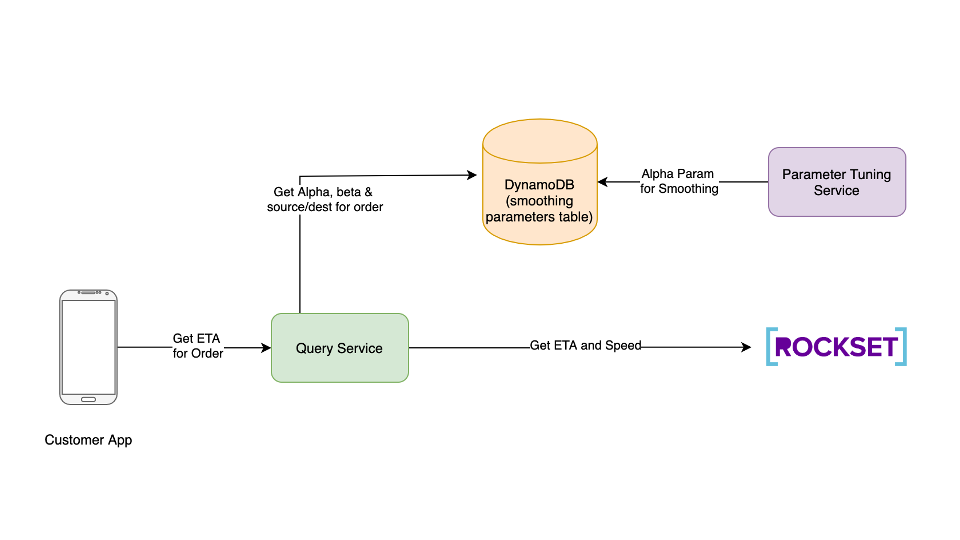
The client app initiates the request to foretell the ETA. It passes the order id within the API name.
The request goes to the question service. Question service performs the next features:
- Fetch the most recent smoothing elements Alpha and Beta from DynamoDB. Right here, Alpha is the smoothing parameter and Beta is the burden assigned to historic ETA whereas calculating the ultimate ETA. Refer step 6 for extra particulars
- Fetch the vacation spot geohash for the order id.
- Fetch the present driver geohash from the places assortment.
- Set off calculate_ETA Question Lamba in Rockset with smoothing issue alpha as param and driver geohash as supply geohash and vacation spot geohash from step 2. Let’s name this historic ETA.
curl --request POST
--url https://api.rs2.usw2.rockset.com/v1/orgs/self/ws/commons/lambdas/calculateETA/variations/f7d73fb5a786076c
-H 'Authorization: YOUR ROCKSET API KEY'
-H 'Content material-Sort: utility/json'
-d '{
"parameters": [
{
"name": "alpha",
"type": "float",
"value": "0.7"
},
{
"name": "destination",
"type": "string",
"value": "tdr38d"
},
{
"name": "source",
"type": "string",
"value": "tdr706"
}
]
}'
- Set off calculate_speed Question Lambda in Rockset with present order id as param
curl --request POST
--url https://api.rs2.usw2.rockset.com/v1/orgs/self/ws/commons/lambdas/calculate_speed/variations/cadaf89cba111c06
-H 'Authorization: YOUR ROCKSET API KEY'
-H 'Content material-Sort: utility/json'
-d '{
"parameters": [
{
"name": "order_id",
"type": "string",
"value": "abc"
}
]
}'
- The expected ETA is then calculated by question service as
Predicted ETA = Beta * (historic ETA) + (1 – Beta) * distance(driver, vacation spot)/velocity
The expected ETA is then returned to the client app.
Suggestions Loop
ML fashions require retraining in order that their predictions are correct. In our situation, it’s fairly essential to re-train the ML mannequin in order to account for altering climate circumstances, festivals, and so forth. That is the place the parameter tuning service comes into play.
Parameter Tuning Service

As soon as an ETA is predicted, you possibly can retailer the expected ETA, and the precise ETA in a group known as predictions. The first motivation to retailer this information in Rockset as an alternative of every other datastore is to create a real-time dashboard for measuring the accuracy of the mannequin. That is wanted to ensure the shoppers don’t see absurd ETA values of their apps.
The following query is the way to decide the smoothing issue Alpha. To resolve this situation, we create a parameter tuning service, which is only a Flink batch Job. We fetch all of the historic ETAs and TAs for orders for the previous 7-30 days. We use the distinction in these ETAs to calculate acceptable Alpha and Beta values. This may be completed utilizing a easy mannequin reminiscent of logistic regression.
As soon as the service calculates the Alpha and Beta parameters, they’re saved in DynamoDB in a desk named smoothing_parameters. The question service fetches the parameters from this desk when it receives a request from the patron app.
You possibly can practice the parameter tuning mannequin as soon as per week utilizing ETA information in places assortment.
Conclusion
The structure is designed to deal with greater than one million requests per minute whereas being versatile sufficient to help the scaling of the appliance on the fly. The structure additionally permits builders to change or insert elements reminiscent of including new options (e.g. climate) or including a filter layer to refine the ETA predictions. Right here, Rockset helps us clear up three main necessities:
- Low-latency complicated queries – Rockset permits us to make sophisticated queries reminiscent of exponential smoothing with simply an API name. That is completed by leveraging Question Lambdas. The Lambdas additionally help parameters that permit us to question for various places.
- Extremely scalable real-time ingestion – In case you have roughly 100K drivers in your platform and every of their apps sends a GPS location each 5 seconds, then you might be coping with a throughput of 1.2 million requests per minute. Rockset permits us to question this information inside seconds of occasions occurring.
- Knowledge from a number of sources – Rockset permits us to ingest from a number of sources, reminiscent of Kafka and DynamoDB, utilizing absolutely managed connectors that require minimal configuration.
Kartik Khare has been a Knowledge Engineer for 4 years and has additionally been running a blog about deep-dives on Massive Knowledge Methods on a private weblog and Medium. He at present works at Walmart Labs the place he works on the Realtime ML platforms. Previous to that, he was working for OlaCabs the place he was concerned in designing realtime surge pricing and advice programs.

{kind=link}