
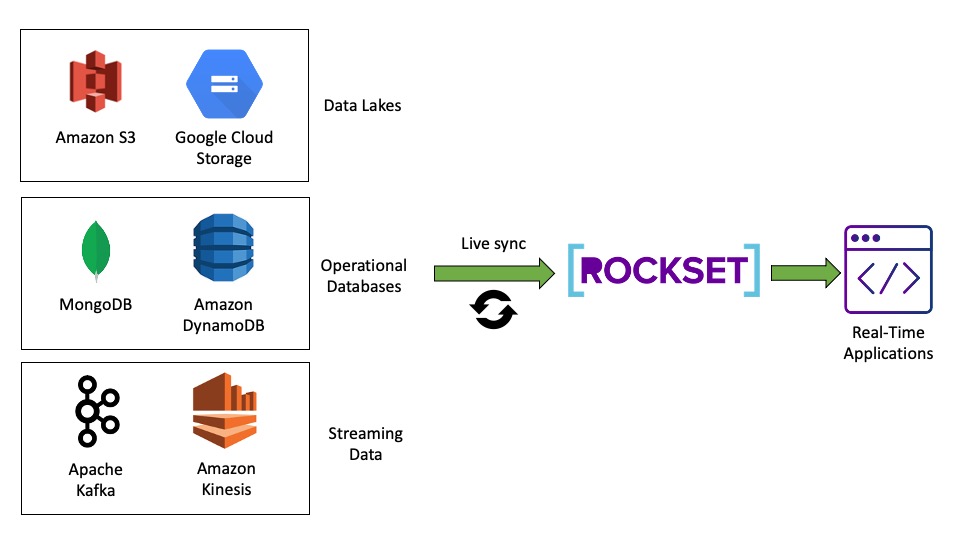
When working with a real-time analytics system you want your database to satisfy very particular necessities. This contains making the info out there for question as quickly as it’s ingested, creating correct indexes on the info in order that the question latency could be very low, and way more.
Earlier than it may be ingested, there’s normally an information pipeline for remodeling incoming information. You need this pipeline to take as little time as attainable, as a result of stale information doesn’t present any worth in a real-time analytics system.
Whereas there’s usually some quantity of knowledge engineering required right here, there are methods to attenuate it. For instance, as a substitute of denormalizing the info, you could possibly use a question engine that helps joins. This may keep away from pointless processing throughout information ingestion and cut back the storage bloat because of redundant information.
The Calls for of Actual-Time Analytics
Actual-time analytics functions have particular calls for (i.e., latency, indexing, and many others.), and your answer will solely be capable of present beneficial real-time analytics if you’ll be able to meet them. However assembly these calls for relies upon totally on how the answer is constructed. Let’s have a look at some examples.
Information Latency
Information latency is the time it takes from when information is produced to when it’s out there to be queried. Logically then, latency must be as little as attainable for real-time analytics.
In most analytics programs immediately, information is being ingested in large portions because the variety of information sources frequently will increase. It can be crucial that real-time analytics options be capable of deal with excessive write charges so as to make the info queryable as rapidly as attainable. Elasticsearch and Rockset every approaches this requirement in another way.
As a result of continuously performing write operations on the storage layer negatively impacts efficiency, Elasticsearch makes use of the reminiscence of the system as a caching layer. All incoming information is cached in-memory for a sure period of time, after which Elasticsearch ingests the cached information in bulk to storage.
This improves the write efficiency, however it additionally will increase latency. It’s because the info will not be out there to question till it’s written to the disk. Whereas the cache period is configurable and you may cut back the period to enhance the latency, this implies you might be writing to the disk extra ceaselessly, which in flip reduces the write efficiency.
Rockset approaches this drawback in another way.
Rockset makes use of a log-structured merge-tree (LSM), a function supplied by the open-source database RocksDB. This function makes it in order that at any time when Rockset receives information, it too caches the info in its memtable. The distinction between this strategy and Elasticsearch’s is that Rockset makes this memtable out there for queries.
Thus queries can entry information within the reminiscence itself and don’t have to attend till it’s written to the disk. This virtually utterly eliminates write latency and permits even current queries to see new information in memtables. That is how Rockset is ready to present lower than a second of knowledge latency even when write operations attain a billion writes a day.
Indexing Effectivity
Indexing information is one other essential requirement for real-time analytics functions. Having an index can cut back question latency by minutes over not having one. Then again, creating indexes throughout information ingestion could be finished inefficiently.
For instance, Elasticsearch’s major node processes an incoming write operation then forwards the operation to all of the duplicate nodes. The duplicate nodes in flip carry out the identical operation regionally. Because of this Elasticsearch reindexes the identical information on all duplicate nodes, again and again, consuming CPU sources every time.
Rockset takes a unique strategy right here, too. As a result of Rockset is a primary-less system, write operations are dealt with by a distributed log. Utilizing RocksDB’s distant compaction function, just one duplicate performs indexing and compaction operations remotely in cloud storage. As soon as the indexes are created, all different replicas simply copy the brand new information and change the info they’ve regionally. This reduces the CPU utilization required to course of new information by avoiding having to redo the identical indexing operations regionally at each duplicate.
Steadily Up to date Information
Elasticsearch is primarily designed for full textual content search and log analytics makes use of. For these instances, as soon as a doc is written to Elasticsearch, there’s decrease likelihood that it’ll be up to date once more.
The best way Elasticsearch handles updates to information will not be very best for real-time analytics that usually includes ceaselessly up to date information. Suppose you have got a JSON object saved in Elasticsearch and also you wish to replace a key-value pair in that JSON object. Whenever you run the replace question, Elasticsearch first queries for the doc, takes that doc into reminiscence, adjustments the key-value in reminiscence, deletes the doc from the disk, and at last creates a brand new doc with the up to date information.
Despite the fact that just one discipline of a doc must be up to date, an entire doc is deleted and listed once more, inflicting an inefficient replace course of. You might scale up your {hardware} to extend the velocity of reindexing, however that provides to the {hardware} price.
In distinction, real-time analytics typically includes information coming from an operational database, like MongoDB or DynamoDB, which is up to date ceaselessly. Rockset was designed to deal with these conditions effectively.
Utilizing a Converged Index, Rockset breaks the info down into particular person key-value pairs. Every such pair is saved in three other ways, and all are individually addressable. Thus when the info must be up to date, solely that discipline will probably be up to date. And solely that discipline will probably be reindexed. Rockset presents a Patch API that helps this incremental indexing strategy.
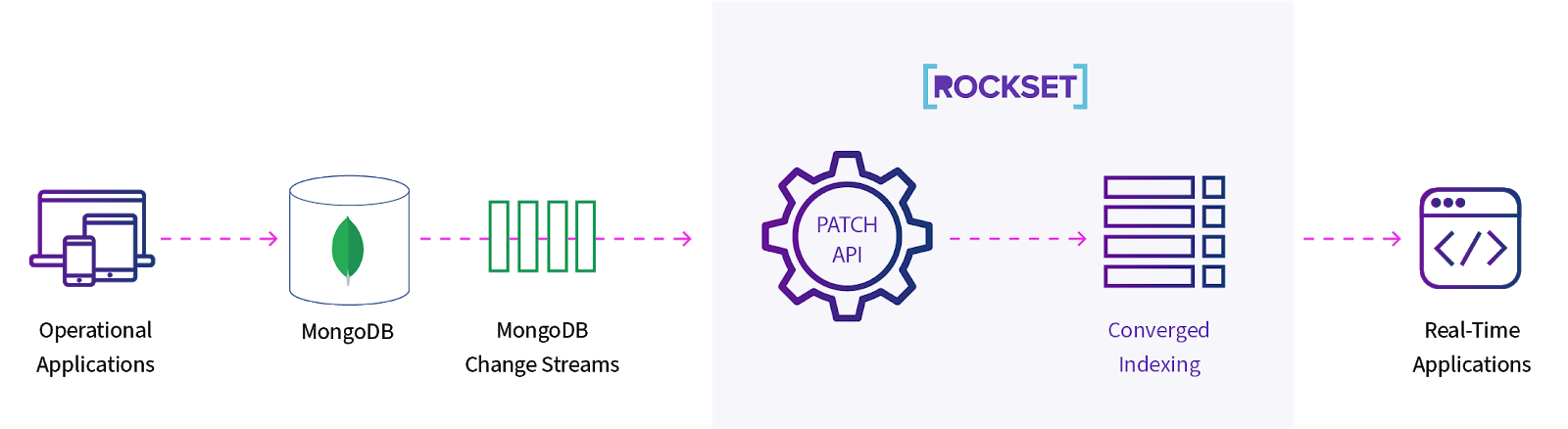
Determine 1: Use of Rockset’s Patch API to reindex solely up to date parts of paperwork
As a result of solely elements of the paperwork are reindexed, Rockset could be very CPU environment friendly and thus price environment friendly. This single-field mutability is particularly essential for real-time analytics functions the place particular person fields are ceaselessly up to date.
Becoming a member of Tables
For any analytics utility, becoming a member of information from two or extra completely different tables is important. But Elasticsearch has no native be a part of assist. Because of this, you might need to denormalize your information so you may retailer it in such a manner that doesn’t require joins to your analytics. As a result of the info must be denormalized earlier than it’s written, it should take further time to organize that information. All of this provides as much as an extended write latency.
Conversely, as a result of Rockset gives commonplace SQL question language assist and parallelizes be a part of queries throughout a number of nodes for environment friendly execution, it is rather straightforward to hitch tables for advanced analytical queries with out having to denormalize the info upon ingest.
Interoperability with Sources of Actual-Time Information
If you end up engaged on a real-time analytics system, it’s a given that you simply’ll be working with exterior information sources. The benefit of integration is essential for a dependable, secure manufacturing system.
Elasticsearch presents instruments like Beats and Logstash, or you could possibly discover a variety of instruments from different suppliers or the group, which let you join information sources—similar to Amazon S3, Apache Kafka, MongoDB—to your system. For every of those integrations, it’s a must to configure the instrument, deploy it, and likewise keep it. You must be sure that the configuration is examined correctly and is being actively monitored as a result of these integrations are usually not managed by Elasticsearch.
Rockset, alternatively, gives a a lot simpler click-and-connect answer utilizing built-in connectors. For every generally used information supply (for instance S3, Kafka, MongoDB, DynamoDB, and many others.), Rockset gives a unique connector.
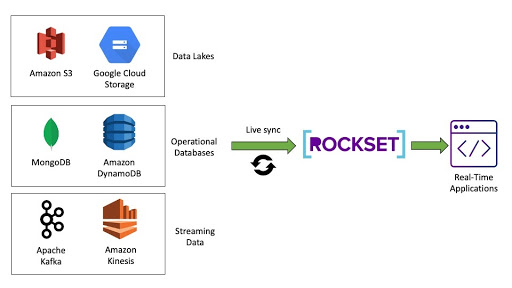
Determine 2: Constructed-in connectors to widespread information sources make it straightforward to ingest information rapidly and reliably
You merely level to your information supply and your Rockset vacation spot, and procure a Rockset-managed connection to your supply. The connector will repeatedly monitor the info supply for the arrival of recent information, and as quickly as new information is detected will probably be routinely synced to Rockset.

Abstract
In earlier blogs on this collection, we examined the operational components and question flexibility behind real-time analytics options, particularly Elasticsearch and Rockset. Whereas information ingestion could not all the time be high of thoughts, it’s however essential for improvement groups to think about the efficiency, effectivity and ease with which information could be ingested into the system, notably in a real-time analytics state of affairs.
When choosing the appropriate real-time analytics answer to your wants, it’s possible you’ll have to ask questions to determine how rapidly information could be out there for querying, making an allowance for any latency launched by information pipelines, how expensive it could be to index ceaselessly up to date information, and the way a lot improvement and operations effort it could take to connect with your information sources. Rockset was constructed exactly with the ingestion necessities for real-time analytics in thoughts.
You’ll be able to learn the Elasticsearch vs Rockset white paper to be taught extra in regards to the architectural variations between the programs and the migration information to discover shifting workloads to Rockset.
Different blogs on this Elasticsearch or Rockset for Actual-Time Analytics collection:

{kind=link}