
A typical function of legacy programs is the Vital Aggregator,
because the title implies this produces data very important to the working of a
enterprise and thus can’t be disrupted. Nevertheless in legacy this sample
virtually at all times devolves to an invasive extremely coupled implementation,
successfully freezing itself and upstream programs into place.
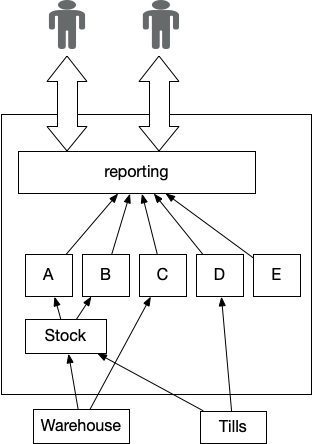
Determine 1: Reporting Vital Aggregator
Divert the Stream is a technique that begins a Legacy Displacement initiative
by creating a brand new implementation of the Vital Aggregator
that, so far as attainable, is decoupled from the upstream programs that
are the sources of the information it must function. As soon as this new implementation
is in place we are able to disable the legacy implementation and therefore have
much more freedom to alter or relocate the varied upstream information sources.
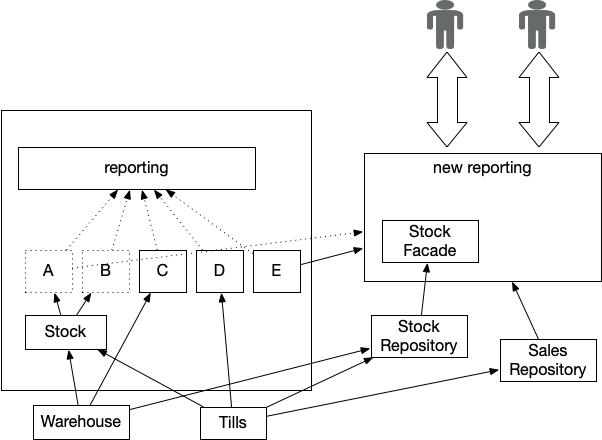
Determine 2: Extracted Vital Aggregator
The choice displacement method when we now have a Vital Aggregator
in place is to depart it till final. We are able to displace the
upstream programs, however we have to use Legacy Mimic to
make sure the aggregator inside legacy continues to obtain the information it
wants.
Both possibility requires the usage of a Transitional Structure, with
short-term elements and integrations required through the displacement
effort to both help the Aggregator remaining in place, or to feed information to the brand new
implementation.
How It Works
Diverting the Stream creates a brand new implementation of a cross chopping
functionality, on this instance that being a Vital Aggregator.
Initially this implementation may obtain information from
current legacy programs, for instance through the use of the
Occasion Interception sample. Alternatively it could be easier
and extra worthwhile to get information from supply programs themselves through
Revert to Supply. In observe we are likely to see a
mixture of each approaches.
The Aggregator will change the information sources it makes use of as current upstream programs
and elements are themselves displaced from legacy,
thus it is dependency on legacy is lowered over time.
Our new Aggregator
implementation may benefit from alternatives to enhance the format,
high quality and timeliness of information
as supply programs are migrated to new implementations.
Map information sources
If we’re going to extract and re-implement a Vital Aggregator
we first want to grasp how it’s linked to the remainder of the legacy
property. This implies analyzing and understanding
the last word supply of information used for the aggregation. It can be crucial
to recollect right here that we have to get to the last word upstream system.
For instance
whereas we would deal with a mainframe, say, because the supply of reality for gross sales
data, the information itself may originate in in-store until programs.
Making a diagram displaying the
aggregator alongside the upstream and downstream dependencies
is vital.
A system context diagram, or comparable, can work properly right here; we now have to make sure we
perceive precisely what information is flowing from which programs and the way
typically. It’s normal for legacy options to be
an information bottleneck: further helpful information from (newer) supply programs is
typically discarded because it was too tough to seize or characterize
in legacy. Given this we additionally must seize which upstream supply
information is being discarded and the place.
Person necessities
Clearly we have to perceive how the aptitude we plan to “divert”
is utilized by finish customers. For Vital Aggregator we frequently
have a really giant mixture of customers for every report or metric. This can be a
traditional instance of the place Function Parity can lead
to rebuilding a set of “bloated” studies that actually do not meet present
person wants. A simplified set of smaller studies and dashboards may
be a greater resolution.
Parallel working could be vital to make sure that key numbers match up
through the preliminary implementation,
permitting the enterprise to fulfill themselves issues work as anticipated.
Seize how outputs are produced
Ideally we wish to seize how present outputs are produced.
One method is to make use of a sequence diagram to doc the order of
information reception and processing within the legacy system, and even only a
circulate chart.
Nevertheless there are
typically diminishing returns in attempting to totally seize the present
implementation, it commonplace to seek out that key data has been
misplaced. In some circumstances the legacy code could be the one
“documentation” for a way issues work and understanding this could be
very tough or expensive.
One creator labored with a shopper who used an export
from a legacy system alongside a extremely advanced spreadsheet to carry out
a key monetary calculation. Nobody at present on the group knew
how this labored, fortunately we had been put in contact with a not too long ago retired
worker. Sadly once we spoke to them it turned out they’d
inherited the spreadsheet from a earlier worker a decade earlier,
and sadly this particular person had handed away some years in the past. Reverse engineering the
legacy report and (twice ‘model migrated’) excel spreadsheet was extra
work than going again to first ideas and defining from recent what
the calculation ought to do.
Whereas we is probably not constructing to function parity within the
substitute finish level we nonetheless want key outputs to ‘agree’ with legacy.
Utilizing our aggregation instance we would
now be capable of produce hourly gross sales studies for shops, nevertheless enterprise
leaders nonetheless
want the top of month totals and these must correlate with any
current numbers.
We have to work with finish customers to create labored examples
of anticipated outputs for given take a look at inputs, this may be very important for recognizing
which system, previous or new, is ‘right’ afterward.
Supply and Testing
We have discovered this sample lends itself properly to an iterative method
the place we construct out the brand new performance in slices. With Vital
Aggregator
this implies delivering every report in flip, taking all of them the best way
by means of to a manufacturing like atmosphere. We are able to then use
Parallel Working
to watch the delivered studies as we construct out the remaining ones, in
addition to having beta customers giving early suggestions.
Our expertise is that many legacy studies include undiscovered points
and bugs. This implies the brand new outputs hardly ever, if ever, match the present
ones. If we do not perceive the legacy implementation totally it is typically
very onerous to grasp the reason for the mismatch.
One mitigation is to make use of automated testing to inject identified information and
validate outputs all through the implementation section. Ideally we would
do that with each new and legacy implementations so we are able to evaluate
outputs for a similar set of identified inputs. In observe nevertheless resulting from
availability of legacy take a look at environments and complexity of injecting information
we frequently simply do that for the brand new system, which is our really useful
minimal.
It’s normal to seek out “off system” workarounds in legacy aggregation,
clearly it is essential to try to monitor these down throughout migration
work.
The commonest instance is the place the studies
wanted by the management workforce will not be truly accessible from the legacy
implementation, so somebody manually manipulates the studies to create
the precise outputs they
see – this typically takes days. As no-one needs to inform management the
reporting would not truly work they typically stay unaware that is
how actually issues work.
Go Reside
As soon as we’re pleased performance within the new aggregator is right we are able to divert
customers in direction of the brand new resolution, this may be executed in a staged trend.
This may imply implementing studies for key cohorts of customers,
a interval of parallel working and eventually chopping over to them utilizing the
new studies solely.
Monitoring and Alerting
Having the proper automated monitoring and alerting in place is important
for Divert the Stream, particularly when dependencies are nonetheless in legacy
programs. It’s worthwhile to monitor that updates are being acquired as anticipated,
are inside identified good bounds and in addition that finish outcomes are inside
tolerance. Doing this checking manually can shortly change into lots of work
and may create a supply of error and delay going forwards.
Typically we suggest fixing any information points discovered within the upstream programs
as we wish to keep away from re-introducing previous workarounds into our
new resolution. As an additional security measure we are able to go away the Parallel Working
in place for a interval and with selective use of reconciliation instruments, generate an alert if the previous and new
implementations begin to diverge too far.
When to Use It
This sample is most helpful when we now have cross chopping performance
in a legacy system that in flip has “upstream” dependencies on different elements
of the legacy property. Vital Aggregator is the commonest instance. As
an increasing number of performance will get added over time these implementations can change into
not solely enterprise vital but additionally giant and sophisticated.
An typically used method to this example is to depart migrating these “aggregators”
till final since clearly they’ve advanced dependencies on different areas of the
legacy property.
Doing so creates a requirement to maintain legacy up to date with information and occasions
as soon as we being the method of extracting the upstream elements. In flip this
implies that till we migrate the “aggregator” itself these new elements stay
to a point
coupled to legacy information buildings and replace frequencies. We even have a big
(and sometimes essential) set of customers who see no enhancements in any respect till close to
the top of the general migration effort.
Diverting the Stream gives a substitute for this “go away till the top” method,
it may be particularly helpful the place the fee and complexity of continuous to
feed the legacy aggregator is important, or the place corresponding enterprise
course of adjustments means studies, say, have to be modified and tailored throughout
migration.
Enhancements in replace frequency and timeliness of information are sometimes key
necessities for legacy modernisation
tasks. Diverting the Stream provides a possibility to ship
enhancements to those areas early on in a migration undertaking,
particularly if we are able to apply
Revert to Supply.
Information Warehouses
We frequently come throughout the requirement to “help the Information Warehouse”
throughout a legacy migration as that is the place the place key studies (or comparable) are
truly generated. If it seems the DWH is itself a legacy system then
we are able to “Divert the Stream” of information from the DHW to some new higher resolution.
Whereas it may be attainable to have new programs present an an identical feed
into the warehouse care is required as in observe we’re as soon as once more coupling our new programs
to the legacy information format together with it is attendant compromises, workarounds and, very importantly,
replace frequencies. We now have
seen organizations change important parts of legacy property however nonetheless be caught
working a enterprise on old-fashioned information resulting from dependencies and challenges with their DHW
resolution.
This web page is a part of:
Patterns of Legacy Displacement

Most important Narrative Article
Patterns

{kind=link}