
I first met with the Rockset staff once they have been simply 4 folks in a small workplace in San Francisco. I used to be stunned by their expertise and friendliness, however most significantly, their willingness to spend so much of time mentoring me. I knew little or no about Rockset’s applied sciences and didn’t know what to anticipate from such an agile early-stage startup, however determined to hitch the staff for a summer time internship anyway.
I Was Rockset’s First Ever Intern
Since I didn’t have a lot expertise with software program engineering, I used to be taken with touching as many alternative items as I might to get a really feel for what I is likely to be taken with. The staff was very accommodating of this—since I used to be the primary and solely intern, I had a number of freedom to discover totally different areas of the Rockset stack. I spent every week engaged on the Python consumer, every week engaged on the Java ingestion code, and every week engaged on the C++ SQL backend.
There may be at all times a number of work to be executed at a startup, so I had the chance to work on no matter was wanted and attention-grabbing to me. I made a decision to delve into the SQL backend, and began engaged on the question compiler and execution system. A whole lot of the work I did over the summer time ended up being targeted on aggregation queries, and on this weblog publish I’ll dive deeper into how aggregation queries are executed in Rockset. We’ll first speak about serial execution of easy and complicated aggregation queries, after which discover methods to distribute the workload to enhance time and house effectivity.
Serial Execution of Aggregation Queries
Let’s say we’ve got a desk rankings, the place every row consists of a person, a restaurant, an entree and that person’s ranking of that entree at that restaurant.
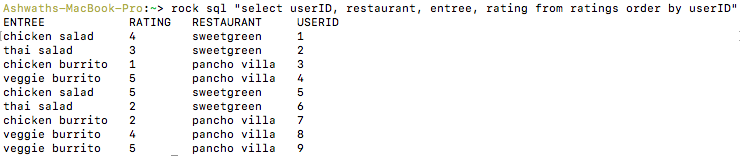
The aggregation question choose restaurant, avg(ranking) from rankings group by restaurant computes the typical ranking of every restaurant. (See right here for more information on the GROUP BY notation.)

A simple method to execute this computation could be to traverse the rows within the desk and construct a hash map from restaurant to a (sum, rely) pair, representing the sum and rely of all of the rankings seen thus far. Then, we are able to traverse every entry of the map and add (restaurant, sum/rely) to the set of returned outcomes. Certainly, for easy and low-memory aggregations, this single computation stage suffices. Nevertheless, with extra complicated queries, we’ll want a number of computation levels.
Suppose we needed to compute not simply the typical ranking of every restaurant, but in addition the breakdown of that common ranking by entree. The SQL question for that might be choose restaurant, entree, avg(ranking) from rankings group by rollup(restaurant, entree). (See our docs and this tutorial for more information on the ROLLUP notation).

Executing this question is similar to executing the earlier one, besides now we’ve got to assemble the important thing(s) for the hash map otherwise. The instance question has three distinct groupings: (), (restaurant) and (restaurant, entree). For every row within the desk, we create three hash keys, one for every grouping. A hash secret’s generated by hashing collectively an identifier for which grouping it corresponds to and the values of the columns within the grouping. We now have two computation levels: first, computing the hash keys, and second, utilizing the hash keys to construct a hash map that retains monitor of the operating sum and rely (just like the primary question). Going ahead, we’ll name them the hashing and aggregation levels, respectively.
Up to now, we’ve made the idea that the entire desk is saved on the identical machine and all computation is finished on the identical machine. Nevertheless, Rockset makes use of a distributed design the place knowledge is partitioned and saved on a number of leaf nodes and queries are executed on a number of aggregator nodes.
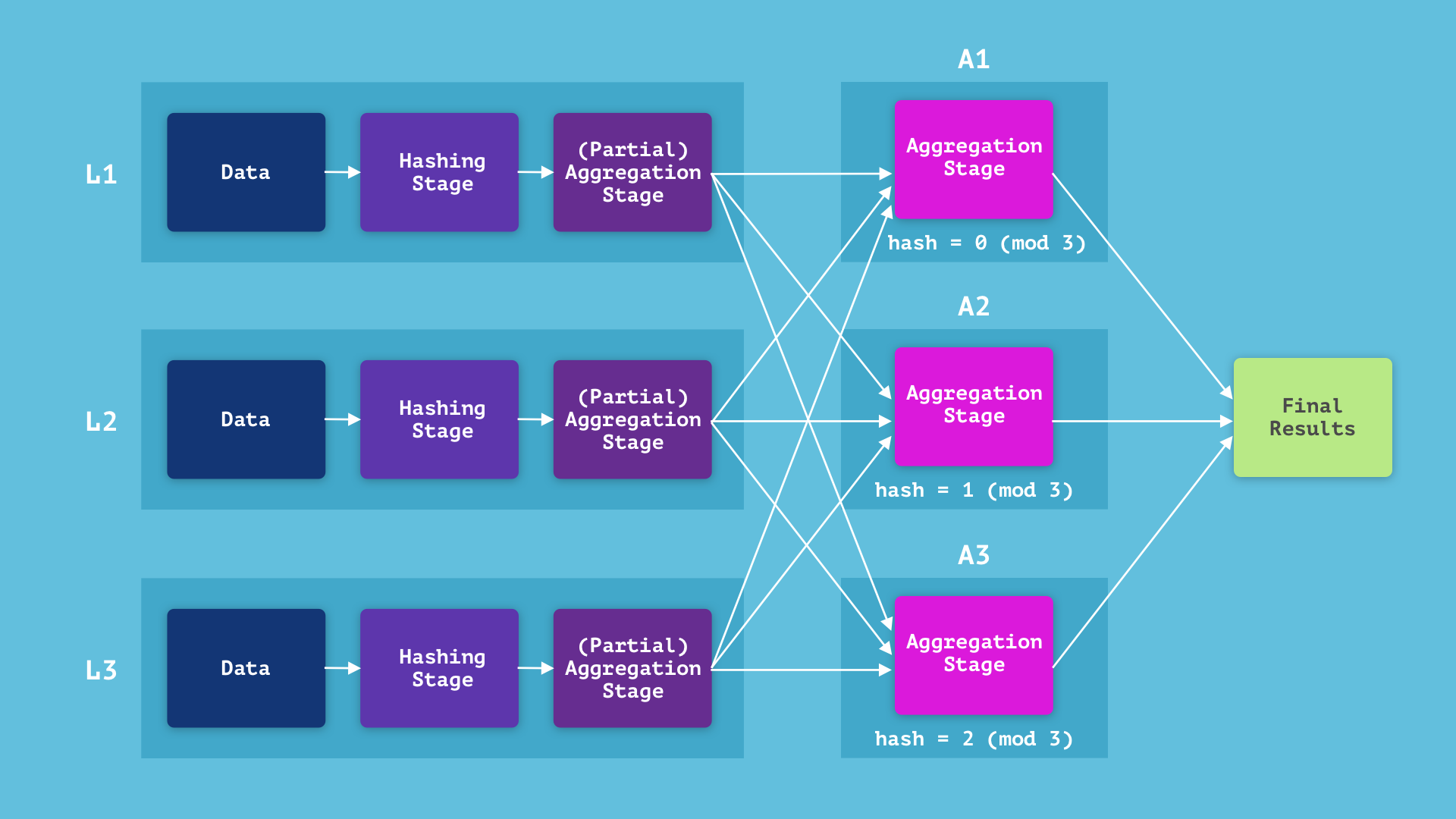
Lowering Question Latency Utilizing Partial Aggregations in Rockset
Let’s say there are three leaf machines (L1, L2, L3) and three aggregators (A1, A2, A3). (See this weblog publish for particulars on the Aggregator Leaf Tailer structure.) The easy answer could be to have all three leaves ship their knowledge to a single aggregator, say A1, and have A1 execute the hashing and aggregation levels. Observe that we are able to cut back the computation time by having the leaves run the hashing levels in parallel and ship the outcomes to the aggregator, which can then solely should run the aggregation stage.
We will additional cut back the computation time by having every leaf node run a “partial” aggregation stage on the information it has and ship that end result to the aggregator, which might then end the aggregation stage. In concrete phrases, if a single leaf incorporates a number of rows with the identical hash key, it doesn’t must ship all of them to an aggregator—it may possibly compute the sum and rely of these rows and solely ship that. In our instance, if the rows comparable to customers 4 and eight are each saved on the identical leaf, that leaf doesn’t must ship each rows to the aggregator. This decreases the serialization and communication load and parallelizes a few of the aggregation computation.
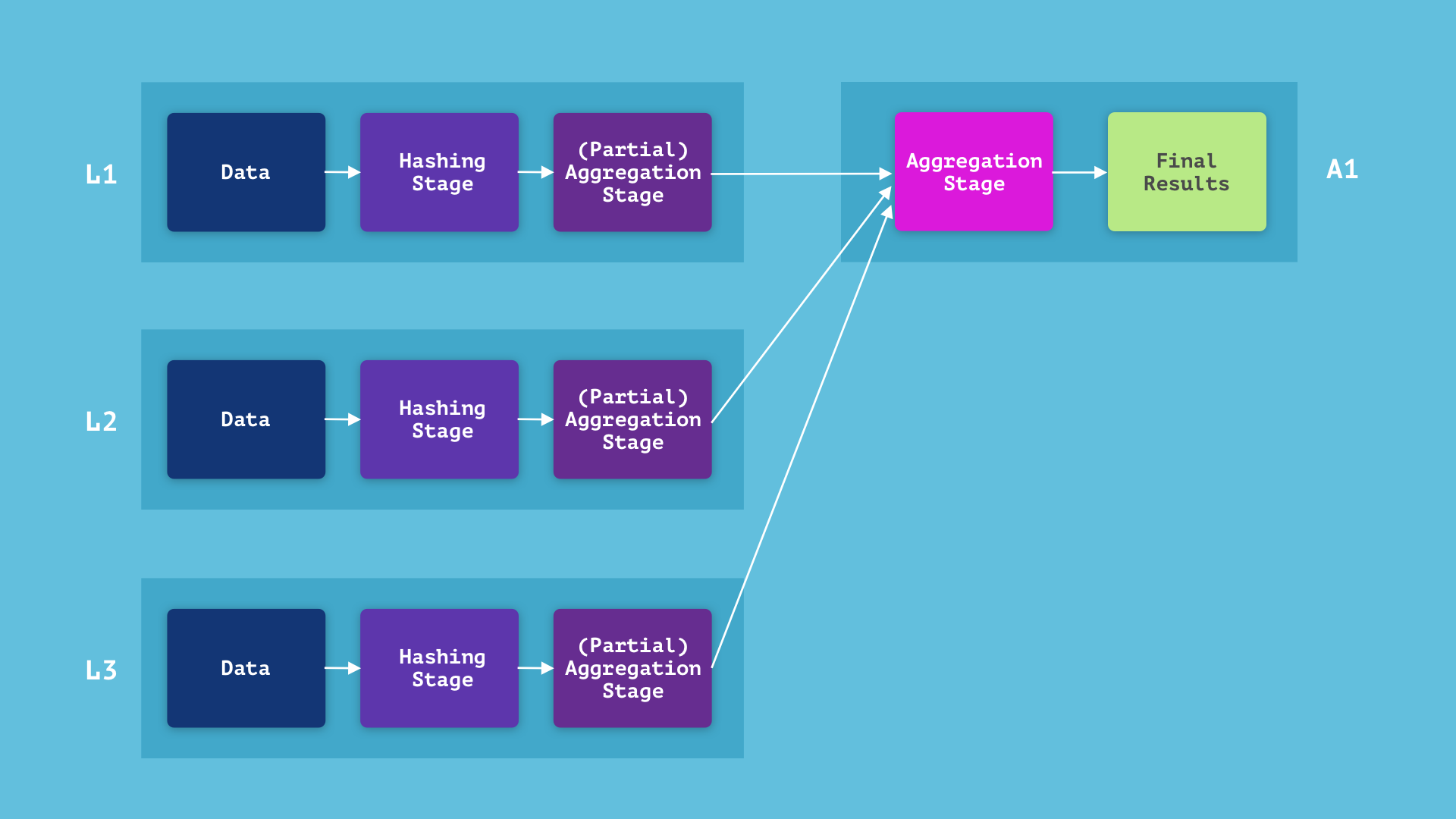
A crude evaluation tells us that for sufficiently massive datasets, this may often lower the computation time, but it surely’s straightforward to see that partial aggregations enhance some queries greater than others. The efficiency of the question choose rely(*) from rankings will drastically enhance, since as a substitute of sending all of the rows to the aggregator and counting them there, every leaf will rely the variety of rows it has and the aggregator will solely must sum them up. The crux of the question is run in parallel and the serialization load is drastically decreased. Quite the opposite, the efficiency of the question choose person, avg(ranking) group by person gained’t enhance in any respect (it’s going to truly worsen on account of overhead), for the reason that customers are all distinct so the partial aggregation levels gained’t truly accomplish something.
Lowering Reminiscence Necessities Utilizing Distributed Aggregations in Rockset
We’ve talked about decreasing the execution time, however what concerning the reminiscence utilization? Aggregation queries are particularly space-intensive, as a result of the aggregation stage can not run in a streaming style. It should see all of the enter knowledge earlier than having the ability to finalize any output row, and subsequently should retailer the complete hash map (which takes as a lot house as the entire output) till the top. If the output is just too massive to be saved on a single machine, the machine will run out of reminiscence and crash. Partial aggregations don’t assist with this drawback, nevertheless, operating the aggregation stage in a distributed style does. Specifically, we are able to run the aggregation stage on a number of aggregators concurrently, and distribute the information in a constant method.
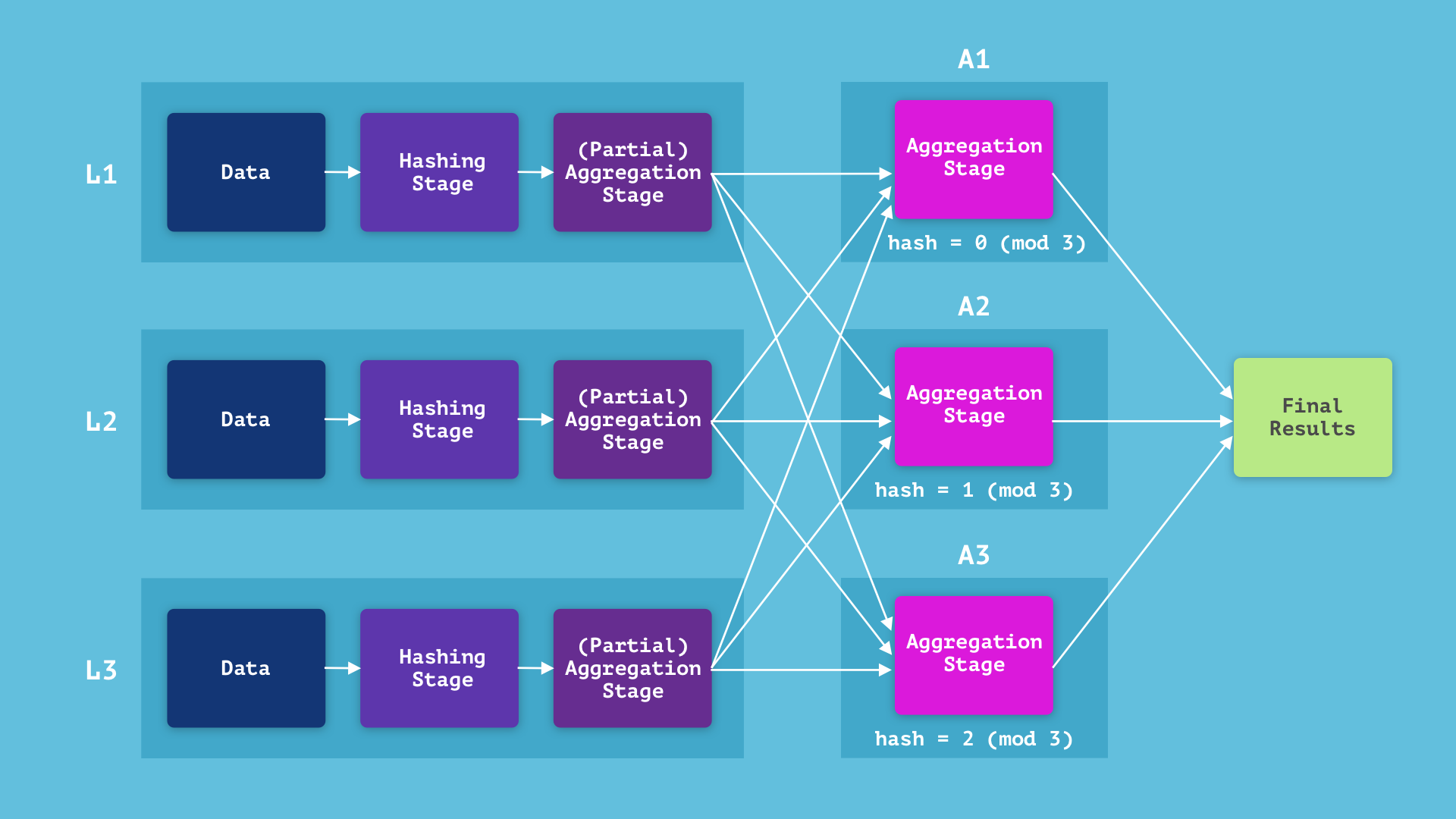
To resolve which aggregator to ship a row of information to, the leaves might merely take the hash key modulo the variety of obtainable aggregators. Every aggregator would then execute the aggregation stage on the information it receives, after which we are able to merge the end result from every aggregator to get the ultimate end result. This fashion, the hash map is distributed over all three aggregators, so we are able to compute aggregations which might be thrice as massive. The extra machines we’ve got, the bigger the aggregation we are able to compute.
My Rockset Internship – A Nice Alternative to Expertise Startup Life
Interning at Rockset gave me the chance to design and implement a number of the options we’ve talked about, and to be taught (at a excessive degree) how a SQL compiler and execution system is designed. With the mentorship of the Rockset staff, I used to be in a position to push these options into manufacturing inside every week of implementing them, and see how rapidly and successfully aggregation queries ran.
Past the technical points, it was very attention-grabbing to see how an agile, early-stage startup like Rockset capabilities on a day-to-day and month-to-month foundation. For somebody like me who’d by no means been at such a small startup earlier than, the expertise taught me a number of intangible expertise that I’m certain will likely be extremely helpful wherever I find yourself. The dimensions of the startup made for an open and collegial ambiance, which allowed me to realize experiences past a standard software program engineering position. As an illustration, for the reason that engineers at Rockset are additionally those in control of customer support, I might eavesdrop on any of these conversations and be included in discussions about how one can extra successfully serve clients. I used to be additionally uncovered to a number of the broader firm technique, so I might study how startups like Rockset plan and execute longer-term progress objectives.
For somebody who loves meals like I do, there’s no scarcity of choices in San Mateo. Rockset caters lunch from a special native restaurant every day, and as soon as every week the entire staff goes out for lunch collectively. The workplace is only a ten minute stroll from the Caltrain station, which makes commuting to the workplace a lot simpler. Along with a bunch of enjoyable folks to work with, after I was at Rockset we had off-sites each month (my favourite was archery).

In case you’re taken with challenges just like those mentioned on this weblog publish, I hope you’ll take into account making use of to hitch the staff at Rockset!

{kind=link}