

Within the publish Introducing the AWS ProServe Hadoop Migration Supply Package TCO device, we launched the AWS ProServe Hadoop Migration Supply Package (HMDK) TCO device and the advantages of migrating on-premises Hadoop workloads to Amazon EMR. On this publish, we dive deep into the device, strolling via all steps from log ingestion, transformation, visualization, and structure design to calculate TCO.
Answer overview
Let’s briefly go to the HMDK TCO device’s key options. The device supplies a YARN log collector to attach Hadoop Useful resource Supervisor to gather YARN logs. A Python-based Hadoop workload analyzer, referred to as the YARN log analyzer, scrutinizes Hadoop purposes. Amazon QuickSight dashboards showcase the outcomes from the analyzer. The identical outcomes additionally speed up the design of future EMR situations. Moreover, a TCO calculator generates the TCO estimation of an optimized EMR cluster for facilitating the migration.
Now let’s take a look at how the device works. The next diagram illustrates the end-to-end workflow.

Within the subsequent sections, we stroll via the 5 predominant steps of the device:
- Accumulate YARN job historical past logs.
- Remodel the job historical past logs from JSON to CSV.
- Analyze the job historical past logs.
- Design an EMR cluster for migration.
- Calculate the TCO.
Stipulations
Earlier than getting began, be certain to finish the next stipulations:
- Clone the hadoop-migration-assessment-tco repository.
- Set up Python 3 in your native machine.
- Have an AWS account with permission on AWS Lambda, QuickSight (Enterprise version), and AWS CloudFormation.
Accumulate YARN job historical past logs
First, you run a YARN log collector, start-collector.sh, in your native machine. This step collects Hadoop YARN logs and locations the logs in your native machine. The script connects your native machine with the Hadoop major node and communicates with Useful resource Supervisor. Then it retrieves the job historical past data (YARN logs from software managers) by calling the YARN ResourceManager software API.
Previous to working the YARN log collector, you might want to configure and set up the connection (HTTP: 8088 or HTTPS: 8090; the latter is really useful) to confirm the accessibility of YARN ResourceManager and enabled YARN Timeline Server (Timeline Server v1 or later are supported). It’s possible you’ll must outline the YARN logs’ assortment interval and retention coverage. To make sure that you acquire consecutive YARN logs, you should use a cron job to schedule the log collector in a correct time interval. For instance, for a Hadoop cluster with 2,000 day by day purposes and the setting yarn.resourcemanager.max-completed-applications set to 1,000, theoretically, you must run the log collector not less than twice to get all of the YARN logs. As well as, we suggest accumulating not less than 7 days of YARN logs for analyzing holistic workloads.
For extra particulars on configure and schedule the log collector, check with the yarn-log-collector GitHub repo.
Remodel the YARN job historical past logs from JSON to CSV
After acquiring YARN logs, you run a YARN log organizer, yarn-log-organizer.py, which is a parser to remodel JSON-based logs to CSV recordsdata. These output CSV recordsdata are the inputs for the YARN log analyzer. The parser additionally has different capabilities, together with sorting occasions by time, eradicating dedicates, and merging a number of logs.
For extra data on use the YARN log organizer, check with the yarn-log-organizer GitHub repo.
Analyze the YARN job historical past logs
Subsequent, you launch the YARN log analyzer to research the YARN logs in CSV format.
With QuickSight, you’ll be able to visualize YARN log information and conduct evaluation towards the datasets generated by pre-built dashboard templates and a widget. The widget robotically creates QuickSight dashboards within the goal AWS account, which configured in a CloudFormation template.
The next diagram illustrates the HMDK TCO structure.

The YARN log analyzer supplies 4 key functionalities:
- Add reworked YARN job historical past logs in CSV format (for instance,
cluster_yarn_logs_*.csv) to Amazon Easy Storage Service (Amazon S3) buckets. These CSV recordsdata are the outputs from the YARN log organizer. - Create a manifest JSON file (for instance,
yarn-log-manifest.json) for QuickSight and add it to the S3 bucket: - Deploy QuickSight dashboards utilizing a CloudFormation template, which is in YAML format. After deploying, select the refresh icon till you see the stack’s standing as
CREATE_COMPLETE. This step creates datasets on QuickSight dashboards in your AWS goal account.
- On the QuickSight dashboard, you could find insights of the analyzed Hadoop workloads from numerous charts. These insights enable you design future EMR situations for migration acceleration, as demonstrated within the subsequent step.

Design an EMR cluster for migration
The outcomes of the YARN log analyzer enable you perceive the precise Hadoop workloads on the present system. This step accelerates designing future EMR situations for migration through the use of an Excel template. The template comprises a guidelines for conducting workload evaluation and capability planning:
- Are the purposes working on the cluster getting used appropriately with their present capability?
- Is the cluster below load at a sure time or not? If that’s the case, when is the time?
- What varieties of purposes and engines (equivalent to MR, TEZ, or Spark) are working on the cluster, and what’s the useful resource utilization for every kind?
- Are completely different jobs’ run cycles (real-time, batch, advert hoc) working in a single cluster?
- Are any jobs working in common batches, and in that case, what are these schedule intervals? (For instance, each 10 minutes, 1 hour, 1 day.) Do you will have jobs that use lots of assets throughout a very long time interval?
- Do any jobs want efficiency enchancment?
- Are any particular organizations or people monopolizing the cluster?
- Are any blended growth and operation jobs working in a single cluster?
After you full the guidelines, you’ll have a greater understanding of design the longer term structure. For optimizing EMR cluster price effectiveness, the next desk supplies basic tips of selecting the right kind of EMR cluster and Amazon Elastic Compute Cloud (Amazon EC2) household.

To decide on the correct cluster kind and occasion household, you might want to carry out a number of rounds of research towards YARN logs primarily based on numerous standards. Let’s take a look at some key metrics.
Timeline
You will discover workload patterns primarily based on the variety of Hadoop purposes run in a time window. For instance, the day by day or hourly charts “Rely of Information by Startedtime” present the next insights:
- In day by day time collection charts, you evaluate the variety of software runs between working days and holidays, and amongst calendar days. If the numbers are comparable, it means the day by day utilizations of the cluster are comparable. However, if the deviation is massive, the proportion of advert hoc jobs is critical. You can also determine the potential weekly or month-to-month jobs on explicit days. Within the scenario, you’ll be able to simply see particular days in every week or a month with excessive workload focus.
- In hourly time collection charts, you additional perceive how purposes are run in hourly home windows. You will discover peak and off-peak hours in a day.
Customers
The YARN logs comprise the person ID of every software. This data helps you perceive who submits an software to a queue. Primarily based on the statistics of particular person and aggregated software runs per queue and per person, you’ll be able to decide the present workload distribution by person. Often, customers on the identical staff have shared queues. Someday, a number of groups have shared queues. When designing queues for customers, you now have insights that will help you design and distribute software workloads which can be extra balanced throughout queues than they beforehand had been.
Software sorts
You may phase workloads primarily based on numerous software sorts (equivalent to Hive, Spark, Presto, or HBase) and run engines (equivalent to MR, Spark, or Tez). For the compute-heavy workloads equivalent to MapReduce or Hive-on-MR jobs, use CPU-optimized situations. For memory-intensive workloads equivalent to Hive-on-TEZ, Presto, and Spark jobs, use memory-optimized situations.
ElapsedTime
You may categorize purposes by runtime. The embedded CloudFormation template robotically creates an elapsedGroup area in a QuickSight dashboard. This permits a key function to assist you to observe long-running jobs in one in every of 4 charts on QuickSight dashboards. Subsequently, you’ll be able to design tailor-made future architectures for these massive jobs.
The corresponding QuickSight dashboards embrace 4 charts. You may drill down every chart, which is related to at least one group.
| Group Quantity |
Runtime/Elapsed Time of a Job |
| 1 | Lower than 10 minutes |
| 2 | Between 10 minutes and half-hour |
| 3 | between half-hour and 1 hour |
| 4 | Better than 1 hour |
Within the chart of Group 4, you’ll be able to focus on scrutinizing massive jobs primarily based on numerous metrics, together with person, queue, software kind, timeline, useful resource utilization, and so forth. Primarily based on this consideration, you could have devoted queues on a cluster or a devoted EMR cluster for big jobs. In the meantime, chances are you’ll submit small jobs to shared queues.
Assets
Primarily based on useful resource (CPU, reminiscence) consumption patterns, you select the best measurement and household of EC2 situations for efficiency and value effectiveness. For compute-intensive purposes, we suggest situations of CPU-optimized households. For memory-intensive purposes, the memory-optimized occasion households are really useful.
As well as, primarily based on the character of the applying workloads and useful resource utilization over the time, chances are you’ll select a persistent or transient EMR cluster, Amazon EMR on EKS, or Amazon EMR Serverless.
After analyzing YARN logs by numerous metrics, you’re able to design future EMR architectures. The next desk lists examples of proposed EMR clusters. You will discover extra particulars within the optimized-tco-calculator GitHub repo.

Calculate TCO
Lastly, in your native machine, run tco-input-generator.py to combination YARN job historical past logs on an hourly foundation previous to utilizing an Excel template to calculate the optimized TCO. This step is essential as a result of the outcomes simulate the Hadoop workloads in future EMR situations.
The prerequisite of TCO simulation is to run tco-input-generator.py, which generates hourly aggregated logs. Subsequent, you open an Excel template file to allow macros and supply your inputs in inexperienced cells for calculating the TCO. Concerning the enter information, you enter the precise information measurement with out replication, and the {hardware} specs (vCore, mem) of the Hadoop major node and information nodes. You additionally want to pick out and add beforehand generated hourly aggregated logs. After you set the TCO simulation variables, equivalent to Area, EC2 kind, Amazon EMR excessive availability, engine impact, Amazon EC2 and Amazon EBS low cost (EDP), Amazon S3 quantity low cost, native foreign money fee, and EMR EC2 process/core pricing ratio and value/hour, the TCO simulator robotically calculates the optimum price of future EMR situations on Amazon EC2. The next screenshots present an instance of HMDK TCO outcomes.
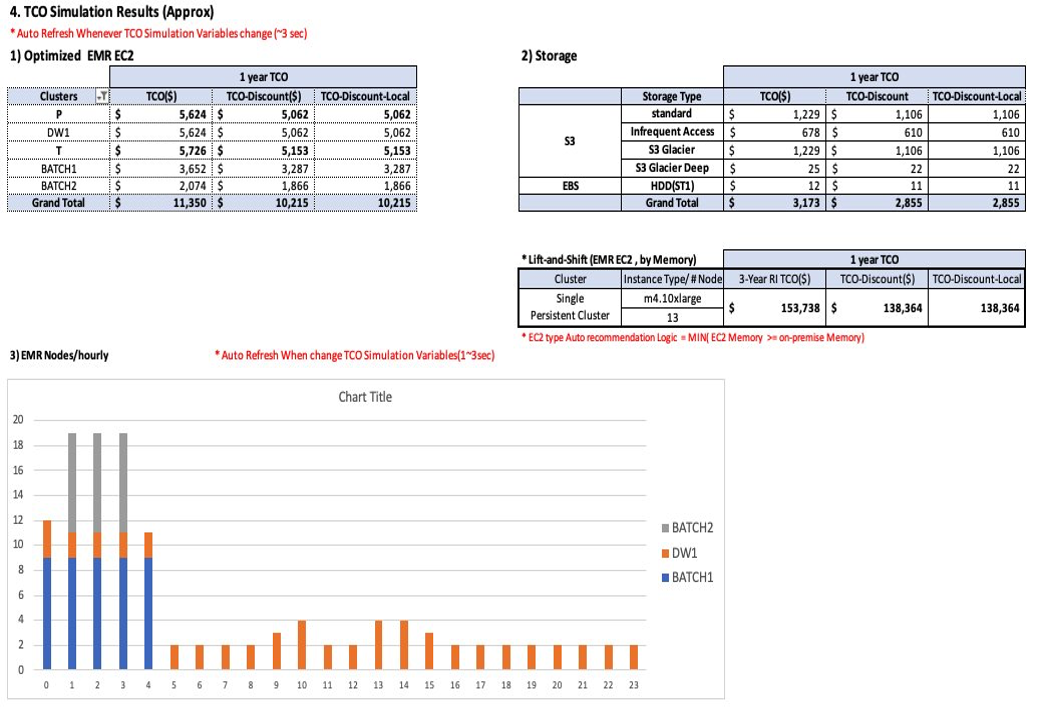
For extra data and directions of HMDK TCO calculations, check with the optimized-tco-calculator GitHub repo.
Clear up
After you full all of the steps and end testing, full the next steps to delete assets to keep away from incurring prices:
- On the AWS CloudFormation console, select the stack you created.
- Select Delete.
- Select Delete stack.
- Refresh the web page till you see the standing
DELETE_COMPLETE. - On the Amazon S3 console, delete S3 bucket you created.
Conclusion
The AWS ProServe HMDK TCO device considerably reduces migration planning efforts, that are the time-consuming and difficult duties of assessing your Hadoop workloads. With the HMDK TCO device, the evaluation normally takes 2–3 weeks. You too can decide the calculated TCO of future EMR architectures. With the HMDK TCO device, you’ll be able to rapidly perceive your workloads and useful resource utilization patterns. With the insights generated by the device, you might be geared up to design optimum future EMR architectures. In lots of use circumstances, a 1-year TCO of the optimized refactored structure supplies vital price financial savings (64–80% discount) on compute and storage, in comparison with lift-and-shift Hadoop migrations.
To study extra about accelerating your Hadoop migrations to Amazon EMR and the HMDK CTO device, check with the Hadoop Migration Supply Package TCO GitHub repo, or attain out to AWS-HMDK@amazon.com.
Concerning the authors
 Sungyoul Park is a Senior Observe Supervisor at AWS ProServe. He helps clients innovate their enterprise with AWS Analytics, IoT, and AI/ML companies. He has a specialty in large information companies and applied sciences and an curiosity in constructing buyer enterprise outcomes collectively.
Sungyoul Park is a Senior Observe Supervisor at AWS ProServe. He helps clients innovate their enterprise with AWS Analytics, IoT, and AI/ML companies. He has a specialty in large information companies and applied sciences and an curiosity in constructing buyer enterprise outcomes collectively.
 Jiseong Kim is a Senior Knowledge Architect at AWS ProServe. He primarily works with enterprise clients to assist information lake migration and modernization, and supplies steering and technical help on large information tasks equivalent to Hadoop, Spark, information warehousing, real-time information processing, and large-scale machine studying. He additionally understands apply applied sciences to unravel large information issues and construct a well-designed information structure.
Jiseong Kim is a Senior Knowledge Architect at AWS ProServe. He primarily works with enterprise clients to assist information lake migration and modernization, and supplies steering and technical help on large information tasks equivalent to Hadoop, Spark, information warehousing, real-time information processing, and large-scale machine studying. He additionally understands apply applied sciences to unravel large information issues and construct a well-designed information structure.
 George Zhao is a Senior Knowledge Architect at AWS ProServe. He’s an skilled analytics chief working with AWS clients to ship fashionable information options. He’s additionally a ProServe Amazon EMR area specialist who allows ProServe consultants on finest practices and supply kits for Hadoop to Amazon EMR migrations. His space of pursuits are information lakes and cloud fashionable information structure supply.
George Zhao is a Senior Knowledge Architect at AWS ProServe. He’s an skilled analytics chief working with AWS clients to ship fashionable information options. He’s additionally a ProServe Amazon EMR area specialist who allows ProServe consultants on finest practices and supply kits for Hadoop to Amazon EMR migrations. His space of pursuits are information lakes and cloud fashionable information structure supply.
 Kalen Zhang was the International Phase Tech Lead of Companion Knowledge and Analytics at AWS. As a trusted advisor of information and analytics, she curated strategic initiatives for information transformation, led information and analytics workload migration and modernization packages, and accelerated buyer migration journeys with companions at scale. She focuses on distributed techniques, enterprise information administration, superior analytics, and large-scale strategic initiatives.
Kalen Zhang was the International Phase Tech Lead of Companion Knowledge and Analytics at AWS. As a trusted advisor of information and analytics, she curated strategic initiatives for information transformation, led information and analytics workload migration and modernization packages, and accelerated buyer migration journeys with companions at scale. She focuses on distributed techniques, enterprise information administration, superior analytics, and large-scale strategic initiatives.

{kind=link}