

The quantity of knowledge has exploded during the last many years and governments are placing laws in place to offer higher safety and rights to people over their private knowledge. The Common Information Safety Regulation (GDPR) and California Client Privateness Act (CCPA) are one of the stringent privateness and knowledge safety legal guidelines that should be adopted by companies. Amongst different knowledge administration and knowledge governance necessities, these laws require firms to completely and fully delete all personally identifiable data (PII) collected a couple of buyer upon their specific request. This process, also called the “Proper to be Forgotten“, is to be executed throughout a specified interval (eg. inside one calendar month). Though this state of affairs would possibly sound like a difficult activity, it’s nicely supported whereas using Delta Lake, which was additionally described in our earlier weblog. This put up presents varied methods to deal with the “Proper to be Forgotten” necessities within the Information Lakehouse utilizing Delta Reside Tables (DLT). Delta desk is a strategy to retailer knowledge in tables, whereas Delta Reside Tables is a declarative framework that manages delta tables, by creating them and conserving them updated.
Method to implementing the “Proper to be Forgotten”
Whereas there are a lot of alternative ways of implementing the “Proper to be Forgotten” (e.g. Anonymization, Pseudonymization, Information Masking), the most secure methodology stays an entire erasure. All through the years, there have been a number of examples of incomplete or wrongfully carried out anonymization processes which resulted within the re-identification of people. In observe, eliminating the danger of re-identification usually requires an entire deletion of particular person information. As such the main focus of this put up can be deleting personally identifiable data (PII) from the storage as an alternative of making use of anonymization methods.
Level Deletes within the Information Lakehouse
With the introduction of Delta Lake know-how which helps and gives environment friendly level deletes in massive knowledge lakes utilizing ACID transactions and deletion vectors, it’s simpler to find and take away PII knowledge in response to shopper GDPR/CCPA requests. To speed up level deletes, Delta Lake gives many optimizations built-in, equivalent to knowledge skipping with Z-order and bloom filters, to scale back the quantity of knowledge wanted to be learn (eg. Z-order on fields used throughout DELETE operations).
Challenges in implementing the “Proper to be Forgotten”
The info panorama in a company might be massive, with many techniques storing delicate data. Due to this fact, it’s important to establish all PII knowledge and make the entire structure compliant with laws, which suggests completely deleting the information from all Supply Methods, Delta tables, Cloud Storage, and different techniques doubtlessly storing delicate knowledge for an extended interval (eg. dashboards, exterior purposes).
If deletes are initiated within the supply, they should be propagated to all subsequent layers of a medallion structure. To deal with deletes initiated within the supply, change knowledge seize (CDC) in Delta Reside Tables could come in useful. Nonetheless, since Delta Reside Tables handle delta tables inside a pipeline and at the moment don’t assist Change Information Feed, the CDC strategy can’t be used end-to-end throughout all layers to trace row-level modifications between the model of a desk. We want a unique technical resolution as introduced within the subsequent part.
By default, Delta Lake retains desk historical past together with deleted information for 30 days, and makes it out there for “time journey” and rollbacks. However even when earlier variations of the information are eliminated, the information remains to be retained within the cloud storage. Due to this fact, working a VACUUM command on the Delta tables is important to take away the recordsdata completely. By default, it will scale back the time journey capabilities to 7 days (configurable setting) and take away historic variations of the information in query from the cloud storage as nicely. Utilizing Delta Reside Tables is handy on this regard as a result of the VACUUM command is run routinely as a part of the upkeep duties inside 24 hours of a delta desk being up to date.
Now, let’s look into varied methods of implementing the “Proper to be Forgotten” necessities and fixing the above challenges to ensure all layers of the medallion structure are compliant with laws.
Technical approaches for implementing the “Proper to be Forgotten”
Answer 1 – Streaming Tables for Bronze and Materialized Views afterward
Essentially the most easy resolution to deal with the “Proper to be Forgotten”, is to straight delete information from all tables by executing a DELETE command.
A standard medallion structure contains append-only ingestion of supply knowledge to bronze tables with easy transformations. It is a excellent match for streaming tables which apply transformations incrementally and preserve the state. Streaming tables may be used to incrementally course of the information within the Silver layer. Nonetheless, the problem is that streaming tables can solely course of append queries (queries the place new rows are inserted into the supply desk and never modified). Consequently, deleting any report from a supply desk used for streaming will not be supported and breaks the stream.

Due to this fact, the Silver and Gold tables have to be materialized utilizing Materialized Views and recomputed totally each time information are deleted from the Bronze layer. The complete recomputation could also be averted through the use of Enzyme optimization (see Answer 2) or through the use of the skipChangeCommits choice to ignore transitions that delete or modify present information (see Answer 3).
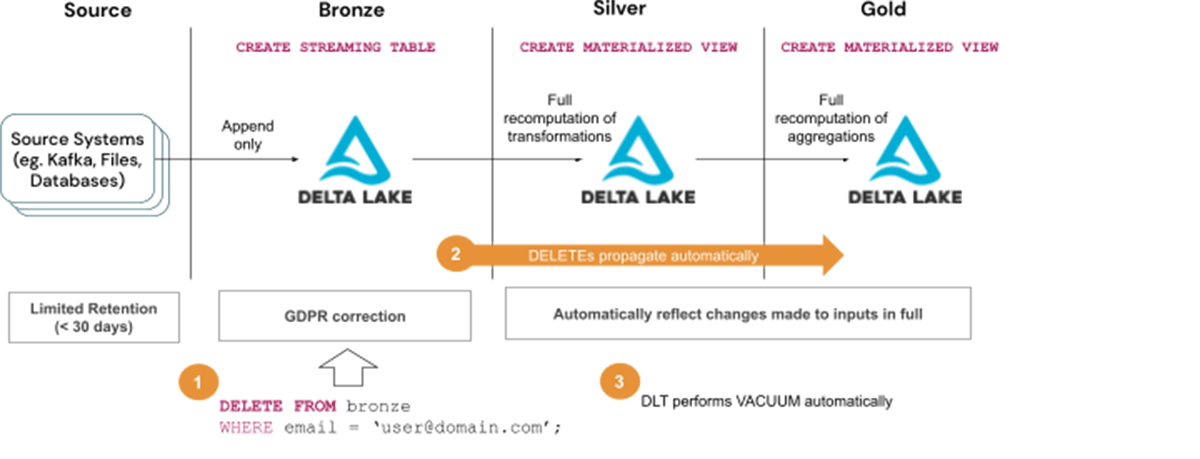
Steps to deal with GDPR/CCPA requests with Answer 1:
- Delete consumer data from Bronze tables
- Watch for the deletes to propagate to subsequent layers, ie. Silver and Gold tables
- Watch for the Vacuum to run routinely as a part of DLT upkeep duties
Think about using Answer 1 when:
- The kind of question used will not be supported by Enzyme optimization, in any other case, use Answer 2 as described beneath
- Full recomputation of tables is appropriate
The principle drawback of the above resolution is that the Materialized Views should recompute the ends in full which could not be fascinating as a consequence of value and latency constraints. Let’s look now at the way to enhance this through the use of Enzyme optimization in DLT.
Answer 2 – Streaming Tables for Bronze and Materialized Views with Enzyme afterward
Enzyme optimization (in personal preview) improves DLT pipeline latency by routinely and incrementally computing modifications to Materialized Views with out the necessity to use Streaming Tables. Meaning, deletes carried out within the Bronze tables will incrementally propagate to subsequent layers with out breaking the pipeline. The DLT pipeline with Enzyme enabled will solely replace rows within the Materialize View essential to materialize the consequence which might enormously scale back infrastructure prices.
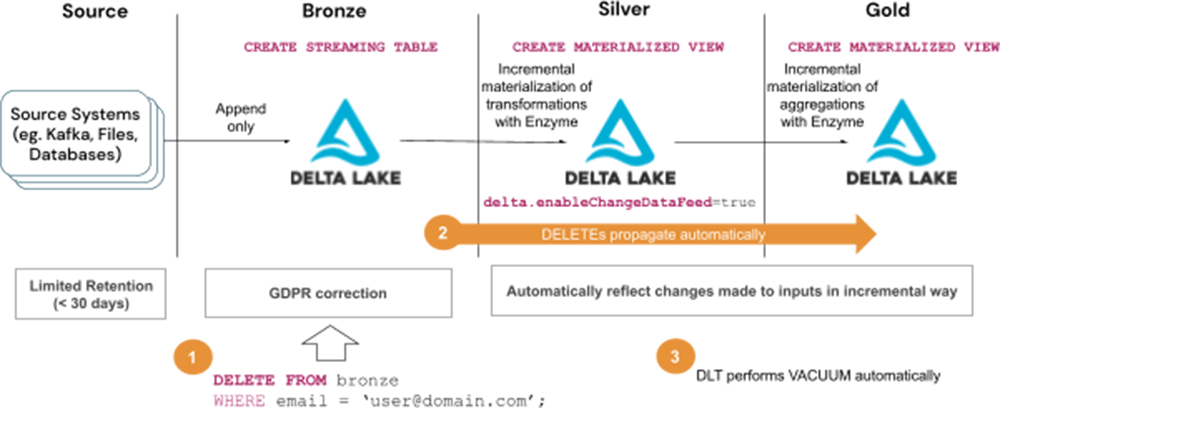
Steps to deal with GDPR/CCPA requests with Answer 2:
- Delete consumer data from Bronze tables
- Watch for the deletes to propagate to subsequent layers, ie. Silver and Gold tables
- Watch for the Vacuum to run routinely as a part of DLT upkeep duties
Think about using Answer 2 when:
- The kind of question used is supported by Enzyme optimization*
- Full recomputation of tables will not be acceptable as a consequence of value and latency necessities
*DLT Enzyme optimization, on the time of writing is in personal preview with assist to a couple chosen eventualities. The scope of which varieties of queries might be incrementally computed will increase over time. Please contact your Databricks consultant to get extra particulars.
Utilizing Enzyme optimization reduces infrastructure value and lowers the processing latency in comparison with Answer 1 the place full recomputation of Silver and Gold tables is required. But when the kind of question run will not be but supported by Enzyme, the options that comply with may be extra applicable.
Answer 3 – Streaming Tables for Bronze & Silver and Materialized Views afterward
As talked about earlier than, executing a delete on a supply desk used for streaming will break the stream. For that cause, utilizing Streaming Tables for Silver tables could also be problematic for dealing with GDPR/CCPA eventualities. The streams will break each time a request to delete PII knowledge is executed on the Bronze tables. With a view to remedy this subject, two various approaches can be utilized as introduced beneath.
Answer 3 (a) – Leveraging Full Refresh performance
The DLT framework gives a Absolutely Refresh (chosen) performance in order that the streams might be repaired by full recomputation of all or chosen tables. That is helpful because the “Proper to be Forgotten” stipulates that non-public data should be deleted solely inside a month from the request and never instantly. Meaning, the total recomputation might be decreased to simply as soon as a month. Furthermore, the total recomputation of the Bronze layer might be averted fully, by setting pipeline.reset.enable = false on the Bronze tables, permitting them to proceed incremental processing.
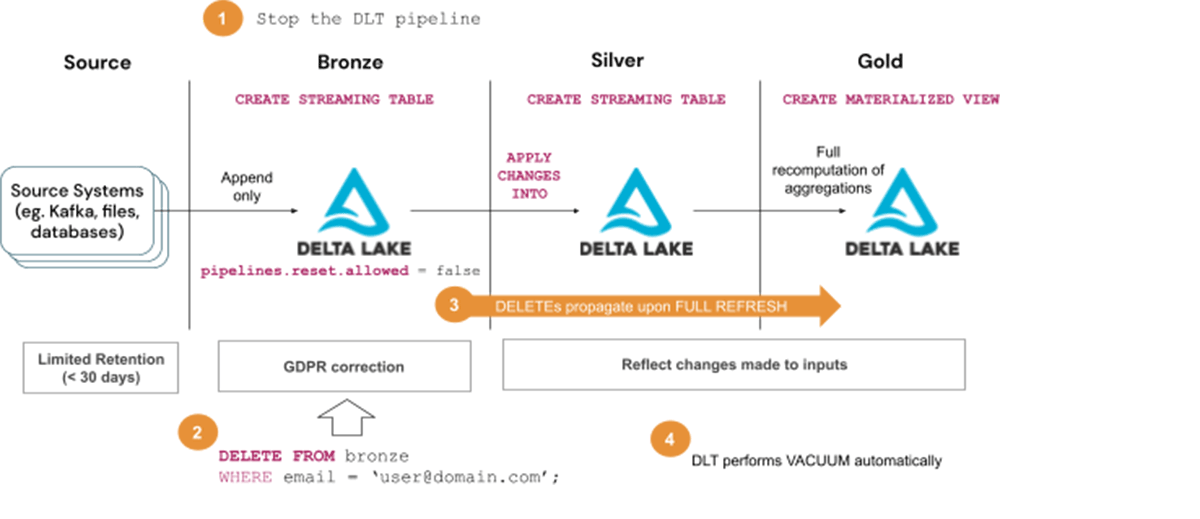
Steps to deal with GDPR/CCPA requests with Answer 3 (a) – execute as soon as monthly or so:
- Cease the DLT pipeline
- Delete consumer data from Bronze tables
- Begin the pipeline in full refresh (chosen) mode and wait till deletes propagate to subsequent layers, ie. Silver and Gold tables
- Watch for the Vacuum to run routinely as a part of DLT upkeep duties
Think about using Answer 3 (a) when:
- The kind of question used will not be supported by Enzyme optimization, in any other case, use Answer 2
- Full recomputation of Silver tables is appropriate to run as soon as monthly
Answer 3 (b) – Leveraging skipChangeCommits possibility
As an alternative choice to the Full Refresh strategy introduced above, the skipChangeCommits possibility can be utilized to keep away from full recomputation of tables. When this feature is enabled the streaming will disregard file-changing operations solely and won’t fail if a change (e.g. DELETE) is detected on a desk getting used as a supply. The downside of this strategy is that the modifications won’t be propagated to downstream tables therefore the DELETEs have to be executed within the subsequent layers individually. Additionally, be aware that the skipChangeCommits possibility will not be supported on queries that use APPLY CHANGES INTO assertion.
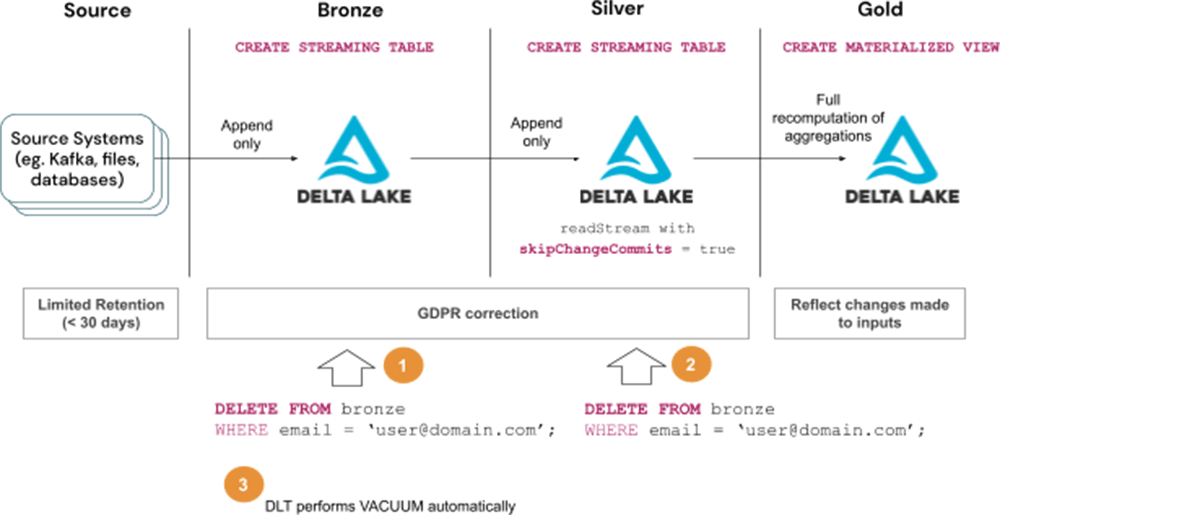
Steps to deal with GDPR/CCPA requests with Answer 3 (b):
- Delete consumer data from Bronze tables
- Delete consumer data from Silver tables and look forward to the modifications to propagate to Gold tables
- Watch for the Vacuum to run routinely as a part of DLT upkeep duties
Think about using Answer 3 (b) when:
- The kind of question used will not be supported by Enzyme optimization, in any other case, use Answer 2
- Full recomputation of Silver tables will not be acceptable
- Queries within the Silver layer are run in append mode (ie. not utilizing APPLY CHANGES INTO assertion)
Answer 3 (a) avoids full recomputation of tables and must be utilized in favor of Answer 3 (a) if APPLY CHANGES INTO assertion will not be used.
Answer 4 – Separate PII knowledge from the remainder of the information
Relatively than deleting information from all of the tables, it could be extra environment friendly to normalize and break up them into separate tables:
- PII desk(s) containing all delicate knowledge (eg. buyer desk) with particular person information identifiable by a surrogate key (eg. customer_id)
- All different knowledge which aren’t delicate and lose their capacity to establish an individual with out the opposite desk
On this case, dealing with the GDPR/CCPA request is so simple as eradicating the information from the PII desk. The remainder of the tables stay intact. The surrogate key saved within the tables (customer_id within the diagram) can’t be used to establish or hyperlink an individual so the information should still be used for ML or some analytics.
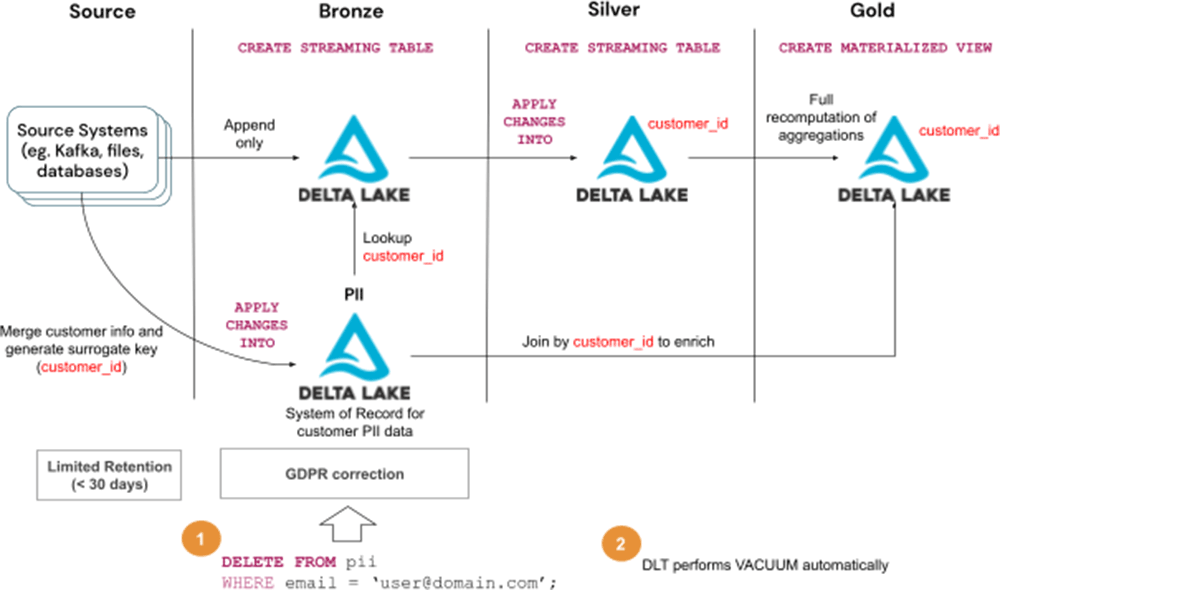
Steps to deal with GDPR/CCPA requests:
- Delete consumer data from the PII desk
- Watch for the Vacuum to run routinely as a part of DLT upkeep duties
Think about using Answer 4 when:
- Full recomputation of tables will not be acceptable
- Designing a brand new knowledge mannequin
- Managing numerous tables and needing a easy methodology to make the entire system compliant with laws
- Needing to have the ability to reuse a lot of the knowledge (eg. constructing ML fashions) whereas being compliant with laws
This strategy tries to construction datasets to restrict the scope of the laws. It’s an awesome possibility when designing new techniques and doubtless the very best holistic resolution for dealing with GDPR/CCPA requests out there. Nonetheless, it provides complexity to the presentation layer because the PII data must be retrieved (joined) from a separate desk each time wanted.
Conclusion
Companies that course of and retailer personally identifiable data (PII) should adjust to authorized laws, eg. GDPR, and CCPA. On this put up, totally different approaches for dealing with the “Proper to be Forgotten” requirement of the laws in query have been introduced utilizing Delta Reside Tables (DLT). Beneath please discover a abstract of all of the options introduced as a information to determine which one ought to match greatest.
| Answer | Think about using when |
|---|---|
|
1 – Streaming Tables for Bronze and Materialized Views afterward |
|
|
2 – Streaming Tables for Bronze and Materialized Views with Enzyme afterward |
|
|
3 (a) Full Refresh – Streaming Tables for Bronze & Silver and Materialized Views afterward |
|
|
3 (b) skipChangeCommits – Streaming Tables for Bronze & Silver and Materialized Views afterward |
|
|
4 – Separate PII knowledge from the remainder of the information |
|

{kind=link}