

On this four-part weblog collection, “Classes discovered from constructing Cybersecurity Lakehouses,” we’re discussing a lot of challenges organizations face with knowledge engineering when constructing out a Lakehouse for cybersecurity knowledge, and provide some options, suggestions, methods, and greatest practices that we’ve used within the area to beat them.
In half one, we started with uniform occasion timestamp extraction. In half two, we checked out find out how to spot and deal with delays in log ingestion. On this third weblog, we deal with among the points associated to parsing semi-structured machine-generated knowledge, utilizing the medallion structure as our guideline.
This weblog will define among the challenges confronted when parsing log-generated knowledge and provide some steering and greatest practices for producing knowledge captured and parsed precisely for analysts to achieve insights into irregular habits, potential breaches, and indicators of compromise. By the tip of this weblog, you’ll have a strong understanding of among the points confronted when capturing and parsing knowledge into the Cybersecurity Lakehouse and a few methods we are able to use to beat them.
Introduction
Parsing machine-generated logs within the context of cybersecurity is the cornerstone of understanding knowledge and gaining visibility and insights from exercise inside your group. Parsing generally is a gnarly and difficult process, however it’s a vital one if knowledge is to be analyzed, reported on, and visualized. With out producing correct and structured codecs, organizations are blind to the various traces of knowledge left in machine-generated knowledge by cyber assaults.
Parsing Challenges
There are a lot of challenges confronted when capturing uncooked knowledge, primarily when machine-generated knowledge is in a streaming format as is the case with many sources.
Timeliness: Information could arrive delayed or out of order. We mentioned this in <<half two>> in case you have been following the weblog collection. Preliminary knowledge seize will be brittle, and making solely the minimal transformation actions earlier than an preliminary write is critical.
Information Format: Log recordsdata are usually learn by a forwarding agent and transmitted to their vacation spot (presumably through third get together techniques). The identical knowledge could also be formatted in another way relying on the agent or middleman hosts. For example, a JSON report written on to cloud storage is not going to be wrapped with some other system data. Nonetheless, a report acquired by a Kafka cluster could have the JSON report encapsulated in a Kafka wrapper. This makes parsing the identical knowledge from totally different techniques an adaptive course of.
Information Inconsistency: Producing schemas for incoming knowledge can result in parsing errors. Fields could not exist in data they’re anticipated to seem in, or unpacking nested fields could result in duplicate column names, which should be appropriately dealt with.
Metadata Extraction: To grasp the origins of information sources, we want a mechanism to extract indicate, or transmit metadata fields corresponding to:
- Supply host
- File title (if file supply)
- Sourcetype for parsing functions
Wire knowledge could have traversed a number of community techniques, and the originating community host is now not obvious. File knowledge could also be saved in listing constructions partitioned by community host names, or originating sources. Capturing this data on the preliminary ingest is required to utterly perceive our knowledge.
Retrospective Parsing: Vital incident response or detection knowledge could require extracting solely components of a string.
Occasion Time: Programs output occasion timestamps in many various codecs. The system should precisely parse timestamps. Take a look at half one of this weblog collection for detailed details about this matter.
Altering log codecs: Log file codecs change often. New fields are added, outdated ones go away, and requirements for area naming are simply an phantasm!
Parsing Rules
Given the challenges outlined above, parsing uncooked knowledge is a brittle process and must be handled with care and methodically. Listed here are some guiding ideas for capturing and parsing uncooked log knowledge.
Take into consideration the parsing operations occurring in a minimum of three distinct phases:
- Seize the uncooked knowledge and parse solely what is critical to retailer the information for additional transformations
- Extract columns from the captured knowledge
- Filter and normalize occasions right into a Widespread Info Mannequin
- Optionally, enrich knowledge both earlier than or after (or each) the normalization course of
Preliminary Information Seize
The preliminary learn of information from log recordsdata and streaming sources is crucial and brittle a part of knowledge parsing. At this stage, make solely the naked minimal modifications to the information. Adjustments needs to be restricted to:
- Exploding blobs of information right into a single report per occasion
- Metadata extraction and addition
(_event_time, _ingest_time, _source, _sourcetype, _input_filename, _dvc_hostname)
Capturing uncooked unprocessed knowledge on this approach permits for knowledge re-ingestion at a later level ought to downstream errors happen.
Extracting Columns
The second section focuses on extracting columns from their authentic constructions the place wanted. Flattening STRUCTS and MAPs ensures the normalization section will be accomplished simply with out the necessity for complicated PySpark code to entry key data required for cyber analysts. Column flattening needs to be evaluated on a case-by-case foundation, as some use circumstances may profit from remaining MAP<STRING, STRING> codecs.
Occasion Normalization
Sometimes, a single knowledge supply can characterize tens or tons of of occasion varieties inside a single feed. Occasion normalization requires filtering particular occasion varieties into an event-specific Widespread Info Mannequin. For instance, a CrowdStrike knowledge supply could have endpoint course of exercise that needs to be filtered right into a process-specific desk but additionally has Home windows Administration Instrumentation (WMI) occasions that needs to be filtered and normalized right into a WMI-specific desk. Occasion normalization is the subject of our subsequent weblog. Keep tuned for that.
Databricks recommends an information design sample to logically manage these duties within the Lakehouse known as the ‘Medallion Structure‘.
Parsing Instance
The instance under exhibits find out how to put into follow the parsing ideas utilized to the Apache access_combined log format.
Beneath, we learn the uncooked knowledge as a textual content file.
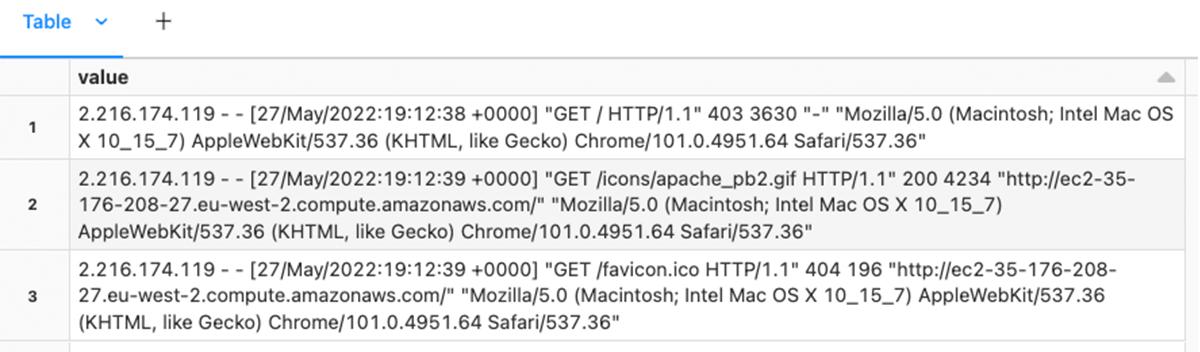
As described above, we wish to maintain any transformations to extracting or including metadata wanted to characterize the information supply. Since this knowledge supply is already represented as one row per occasion, no explode performance is required.
supply = "apache"
sourcetype = "access_combined"
timestamp_col = "worth"
timestamp_regex = '^([^ ]*) [^ ]* ([^ ]*) [([^]]*)]'
df = df.choose(
current_timestamp().forged(TimestampType()).alias("_ingest_time"),
to_timestamp(unix_timestamp(col(timestamp_col), timestamp_format).forged("timestamp"),
"dd-MM-yyyy HH:mm:ss.SSSZ").alias("_event_time"),
lit(supply).alias("_source"),
lit(sourcetype).alias("_sourcetype"),
input_file_name().alias("_source_file"),
"*").withColumn("_event_date", to_date(col("_event_time")))On this command, we extract the _event_time solely from the report and add new columns of metadata, capturing the input_file_name
At this stage, we must always write the bronze delta desk earlier than making any transformations to extract the columns from this knowledge supply. As soon as performed, we are able to create a silver desk by making use of an everyday expression to extract the person columns.
ex = r"^([d.]+) (S+) (S+) [.+] "(w+) (S+) .+" (d{3}) (d+) "(.+)" "(.+)"?$"
df = (df.choose('*',
regexp_extract("worth", ex, 1).alias('host'),
regexp_extract("worth", ex, 2).alias('consumer'),
regexp_extract("worth", ex, 4).alias('methodology'),
regexp_extract("worth", ex, 5).alias('path'),
regexp_extract("worth", ex, 6).alias('code'),
regexp_extract("worth", ex, 7).alias('measurement'),
regexp_extract("worth", ex, 8).alias('referer'),
regexp_extract("worth", ex, 9).alias('agent')
)
.withColumn("query_parameters", expr("""remodel(cut up(parse_url(path,
"QUERY"), "&"), x -> url_decode(x))""")))On this command we parse out the person columns and return a dataframe that can be utilized to jot down to the silver stage desk. At this level, a well-partitioned desk can be utilized for performing queries and creating dashboards, reviews, and alerts. Nonetheless, the ultimate stage for this datasource needs to be to use a standard data mannequin normalization course of. That is the subject of the subsequent a part of this weblog collection. Keep tuned!
Suggestions and greatest practices
Alongside our journey serving to clients with log supply parsing, we’ve developed a lot of suggestions and greatest practices, a few of that are offered under.
- Log codecs change. Develop reusable and version-controlled parsers.
- Use the medallion structure to parse and remodel soiled knowledge into clear constructions.
- Enable for schema evolution in your tables.
- Machine-generated knowledge is messy and modifications usually between software program releases.
- New assault vectors would require extraction of latest columns (some you might wish to write to tables, not simply create on the fly).
- Take into consideration storage retention necessities on the totally different phases of the medallion structure. Do you want to maintain the uncooked seize so long as the silver or gold tables?
Conclusion
Parsing and normalizing semi-structured machine-generated knowledge is a requirement for acquiring and sustaining good safety posture. There are a variety of things to think about, and the Delta Lake structure is well-positioned to speed up cybersecurity analytics. Some options not mentioned on this weblog are schema evolution, knowledge lineage, knowledge high quality, and ACID transactions, that are left for the reader.
Get in Contact
If you’re to be taught extra about how Databricks cyber options can empower your group to determine and mitigate cyber threats, attain out to [email protected] and take a look at our Lakehouse for Cybersecurity Purposes webpage.

{kind=link}