

On this four-part weblog sequence “Classes realized constructing Cybersecurity Lakehouses,” we’re discussing plenty of challenges organizations face with information engineering when constructing out a Lakehouse for Cybersecurity information, and supply some options, suggestions, tips, and greatest practices that we’ve got used within the area to beat them.
In half one, we started with uniform occasion timestamp extraction. On this second half, we are going to have a look at easy methods to spot and deal with delays in log ingestion, which is crucial to sustaining efficient safety operations.
By the tip of this weblog, you’ll have a stable understanding of a few of the points confronted and several other methods we will use to observe and report on information ingestion lag.
Why is information ingestion essential?
Well timed, correct, and searchable log information is vital in Safety Operations. Analysts require close to real-time visibility into safety occasions and incidents. Incident responders are sometimes required to take evasive motion to keep away from or mitigate additional harm to environments. Compliance and assurance features are legally required to exhibit information integrity and have regulatory compliance mandates that require well timed reporting of safety incidents.With out monitoring for information ingestion lag, how can every of those safety features know they’re offering the required service?
Challenges with Knowledge Ingestion Delays
Knowledge ingestion could also be delayed for a lot of causes, starting from conventional infrastructure-type points to delays brought on by the trendy information stack and its multi-hop ingestion route(s).
Conventional Infrastructure
In a standard non-SaaS kind surroundings, log sources are sometimes generated by methods both on-premises or in cloud internet hosting situations, usually with their very own log forwarding brokers put in domestically. Beneath are some examples of points that will come up to trigger delays in a extra conventional structure:
- Community outages
- Receiving system(s) useful resource hunger
- Forwarding and middleware tier failures and useful resource hunger
Fashionable Cloud Stack
Many SaaS suppliers permit both a scheduled or streaming export of log information from their merchandise for his or her clients to ingest into different analytics merchandise. Whereas streaming merchandise and SaaS providers exist, many organizations nonetheless select to land these log information into cloud object storage earlier than ingesting them right into a cyber analytics engine. This creates a multi-hop, time-delayed, and virtually batch-like ingestion sample. It’s a by-product of how trendy architectures usually interoperate relating to log information. Beneath are some examples of points that will come up when ingesting SaaS generated logs;
- SaaS supplier log export failures
- SaaS supplier log export delays
- Cloud storage bucket write failures
- Receiving system failure to acknowledge newly written information
Monitoring for Ingestion Points
In case you have learn half one of this weblog sequence, you’ll know that we advocate producing two metadata fields at ingestion time. _event_time and _ingest_time.
Capturing these two columns on the bronze layer of the medallion structure permits us to observe for delays in receiving and processing log information.
Two principal questions have to be answered:
- Is information coming in from every log supply on the anticipated charge?
- Is information coming in from every log supply on the anticipated frequency?
The examples beneath present how these may be completed.
The next dataframe contains each timestamps used to generate ingestion delay monitoring.
For every row within the dataframe we calculate the variety of minutes every file was delayed and write the outcome to a brand new column ingest_lag_mins.
df = df.withColumn("ingest_lag_mins", spherical((col("_ingest_time").solid("lengthy") - col("_event_time").solid("lengthy"))/60,0))
show(df)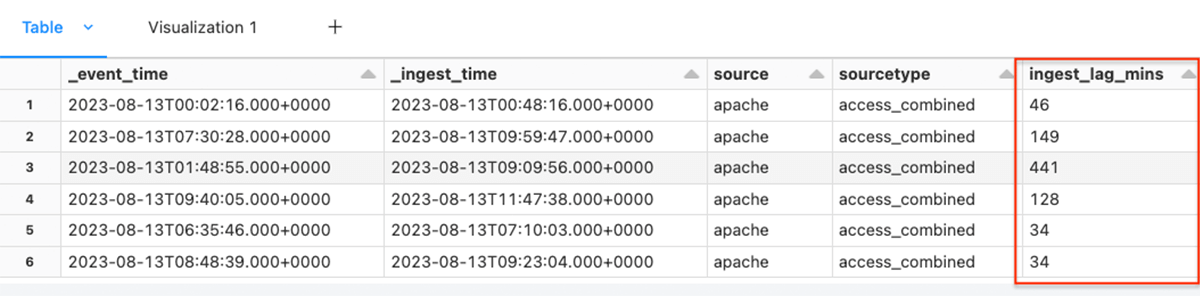
With the lag column created, it is rather easy to create a visualization utilizing the visualization editor.

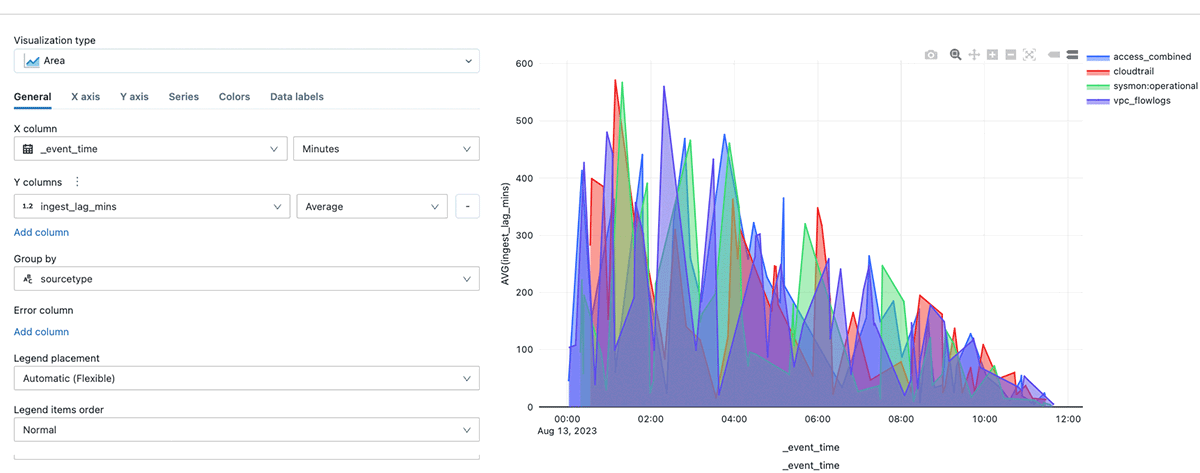
The picture above reveals the common lag in minutes over time by sourcetype.
It is a good start line for a dashboard. Nonetheless, we must always go forward and create studies that present exceptions that have to be investigated. To that finish, we will add an anticipated threshold in opposition to every log supply.
def add_threshold_column(input_df):
# Outline the situations and values for the 'threshold' column
threshold_mins = [
(col("sourcetype") == "access_combined", 300),
(col("sourcetype") == "vpc_flowlogs", 200)
]
default_value = 100
# apply situations and assign values to the new column
output_df = input_df.withColumn("threshold",
when(threshold_mins[0][0], threshold_mins[0][1])
.when(threshold_mins[1][0], threshold_mins[1][1])
.in any other case(default_value))
return output_df
df = add_threshold_column(df)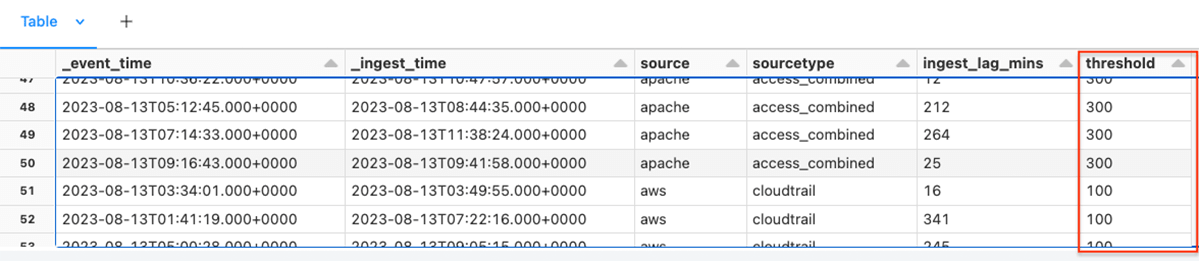
Lastly, report on these log sources which are performing outdoors of the edge values, or optionally multiples of threshold values.
from pyspark.sql.features import max
THRESHOLD_MODIFIER = 5
df2 = (df.groupBy("supply", "sourcetype", "threshold", "ingest_lag_mins").agg(max("_ingest_time").alias("last_seen"))
.the place(col("ingest_lag_mins") > THRESHOLD_MODIFIER*(col("threshold")))
.orderBy("last_seen", ascending=True)
)
show(df2)Within the command above, we outlined a THRESHOLD_MODIFIER to take away extra noise, and created a brand new column last_seen utilizing the PySpark operate MAX, and at last filtered just for data with an ingest lag time larger than the edge.

Monitoring for anticipated frequency
Log sources or reporting hosts are anticipated to ship information on a semi-frequent foundation. Relying on the exercise ranges, the frequency can fluctuate. There are numerous methods for figuring out sources not logging on the anticipated frequency. On this instance, we present a easy approach to report on sources not logging inside an anticipated time-frame. Different potential methods embrace
- Adapting the above and in search of multiples of threshold exceeded inside a time window
- Storing a devoted per log supply threshold for lacking sources and reporting by exception
- Making a baseline or regular frequency, and reporting based mostly on a a number of of ordinary deviation
from pyspark.sql.features import current_timestamp
df3 = (df.groupBy("supply", "sourcetype", "threshold").agg(max("_ingest_time").alias("last_seen"), current_timestamp().alias("t_now"))
)
show(df3)
Within the command above we create two new columns last_seen and t_now, and mixture by the supply and sourcetype to present us the newest occasion acquired for every log supply.
from pyspark.sql.varieties import IntegerType
df4 = (df3.withColumn('missing_minutes', ((col('t_now').solid('lengthy') - col('last_seen').solid('lengthy')) / 60).solid(IntegerType()))
.the place(col("missing_minutes") > 240)
)
show(df4)
Alternatively we could concatenate the supply and sourcetype columns and report a easy listing;
from pyspark.sql.varieties import IntegerType
from pyspark.sql.features import concat_ws
df4 = (df3.withColumn('missing_minutes', ((col('t_now').solid('lengthy') - col('last_seen').solid('lengthy')) / 60).solid(IntegerType()))
.the place(col("missing_minutes") > 240)
.choose(concat_ws(":", "supply", "sourcetype").alias("missing_log_source")))
show(df4)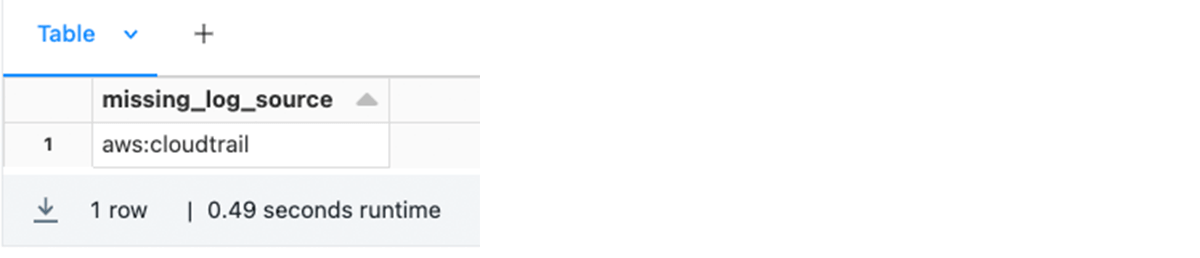
In case you are utilizing Databricks SQL (DB SQL), we advocate that you simply create a dashboard to revisit usually, and alerts for lacking and delayed log sources. One other risk is to schedule a pocket book run utilizing the Databricks Workflows performance and electronic mail outcomes for a run.
Ideas and greatest practices
Throughout this weblog, we’ve got explored a couple of choices to establish and report on delayed and lacking log sources. There are different methods to make this more practical and it’s left to the reader. Nonetheless, some preliminary ideas:
- Bucket occasions into time home windows and calculate the rolling common delays to offer a traditional delay by log supply.
- Retailer a per log supply ‘lacking’ property and report solely on these sources exceeding the lacking worth.
- Add dashboards to visualise all log sources with dropdowns to pick particular sources
Conclusion
Being conscious of information ingestion lags is vital to many components of safety and assurance features and, due to this fact, have to be monitored and resolved promptly. With out correct controls in place, a company could have blind spots and fail to satisfy compliance mandates.
Get in Contact
In case you are to study extra about how Databricks cyber options can empower your group to establish and mitigate cyber threats, attain out to [email protected] and take a look at our Lakehouse for Cybersecurity Purposes webpage.

{kind=link}