

Amazon Managed Streaming for Apache Kafka (Amazon MSK) runs Apache Kafka clusters for you within the cloud. Though utilizing cloud companies means you don’t should handle racks of servers any extra, we make the most of rack conscious options in Apache Kafka to unfold danger throughout AWS Availability Zones and enhance availability of Amazon MSK companies. Apache Kafka brokers have been rack conscious since model 0.10. Because the identify implies, rack consciousness offers a mechanism by which brokers could be configured to pay attention to the place they’re bodily situated. We are able to use the dealer.rack configuration variable to assign every dealer a rack ID.
Why would a dealer wish to know the place it’s bodily situated? Let’s discover two major causes. The primary authentic purpose revolves round designing for prime availability (HA) and resiliency in Apache Kafka. The following purpose, beginning in Apache Kafka 2.4, could be utilized for reducing prices of your cross-Availability Zone visitors from client purposes.
On this submit, we evaluation the HA and resiliency purpose in Apache Kafka and Amazon MSK, then we dive deeper into learn how to scale back the prices of cross-Availability Zone visitors with rack conscious shoppers.
Rack consciousness overview
The design choice for implementing rack consciousness is definitely fairly easy, so let’s begin with the important thing ideas. As a result of Apache Kafka is a distributed system, resiliency is a foundational assemble that should be addressed. In different phrases, in a distributed system, a number of dealer nodes going offline is a given and should be accounted for when working in manufacturing.
In Apache Kafka, one approach to plan for this inevitability is thru knowledge replication. You’ll be able to configure Apache Kafka with the subject replication issue. This setting signifies what number of copies of the subject’s partition knowledge must be maintained throughout brokers. A replication issue of three signifies the subject’s partitions must be saved on a minimum of three brokers, as illustrated within the following diagram.
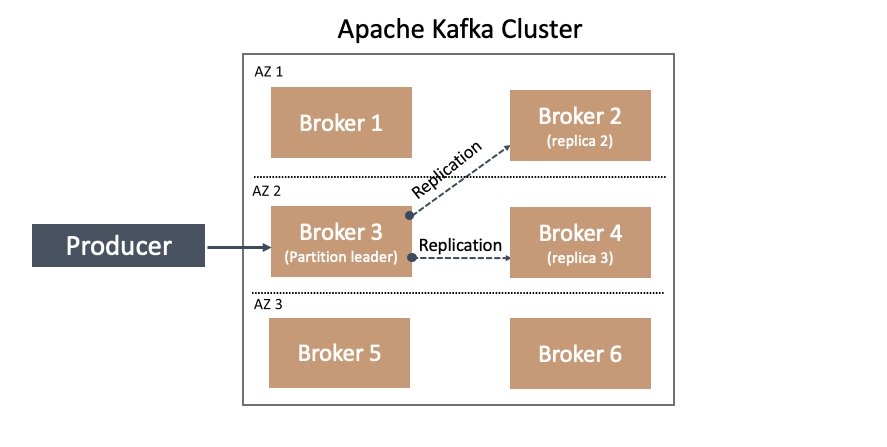
For extra info on replication in Apache Kafka, together with related terminology reminiscent of chief, duplicate, and followers, see Replication.
Now let’s take this a step additional.
With rack consciousness, Apache Kafka can select to steadiness the replication of partitions on brokers throughout completely different racks in line with the replication issue worth. For instance, in a cluster with six brokers configured with three racks (two brokers in every rack), and a subject replication issue of three, replication is tried throughout all three racks—a frontrunner partition is on a dealer in a single rack, with replication to the opposite two brokers in every of the opposite two racks.
This characteristic turns into particularly attention-grabbing when catastrophe planning for an Availability Zone going offline. How can we plan for HA on this case? Once more, the reply is present in rack consciousness. If we configure our dealer’s dealer.rack config setting primarily based on the Availability Zone (or knowledge middle location) during which it resides for instance, we could be resilient to Availability Zone failures. How does this work? We are able to construct upon the earlier instance—in a six-node Kafka cluster deployed throughout three Availability Zones, two nodes are in every Availability Zone and configured with a dealer.rack in line with their respective Availability Zone. Due to this fact, a replication issue of three is tried to retailer a duplicate of partition knowledge in every Availability Zone. This implies a duplicate of your subject’s knowledge resides in every Availability Zone, as illustrated within the following diagram.

One of many many advantages of selecting to run your Apache Kafka workloads in Amazon MSK is the dealer.rack variable on every dealer is ready mechanically in line with the Availability Zone during which it’s deployed. For instance, once you deploy a three-node MSK cluster throughout three Availability Zones, every node has a distinct dealer.rack setting. Or, once you deploy a six-node MSK cluster throughout three Availability Zones, you’ve a complete of three distinctive dealer.rack values.
Moreover, a noteworthy profit of selecting Amazon MSK is that replication visitors throughout Availability Zones is included with service. You’re not charged for dealer replication visitors that crosses Availability Zone boundaries!
On this part, we lined the primary purpose for being Availability Zone conscious: knowledge produced is unfold throughout all of the Availability Zones for the cluster, bettering sturdiness and availability when there are points on the Availability Zone degree.
Subsequent, let’s discover a second use of rack consciousness—learn how to use it to chop community visitors prices of Kafka shoppers.
Beginning in Apache Kafka 2.4, KIP-392 was applied to enable shoppers to fetch from the closest duplicate.
Earlier than closest duplicate fetching was allowed, all client visitors went to the chief of a partition, which might be in a distinct rack, or Availability Zone, than the consumer consuming knowledge. However with functionality from KIP-392 beginning in Apache Kafka 2.4, we will configure our Kafka shoppers to learn from the closest duplicate brokers fairly than the partition chief. This opens up the potential to keep away from cross-Availability Zone visitors prices if a reproduction follower resides in the identical Availability Zone because the consuming software. How does this occur? It’s constructed on the beforehand described rack consciousness performance in Apache Kafka brokers and prolonged to shoppers.
Let’s cowl a selected instance of learn how to implement this in Amazon MSK and Kafka shoppers.
Implement fetch from closest duplicate in Amazon MSK
Along with needing to deploy Apache Kafka 2.4 or above (Amazon MSK 2.4.1.1 or above), we have to set two configurations.
On this instance, I’ve deployed a three-broker MSK cluster throughout three Availability Zones, which implies one dealer resides in every Availability Zone. As well as, I’ve deployed an Amazon Elastic Compute Cloud (Amazon EC2) occasion in considered one of these Availability Zones. On this EC2 occasion, I’ve downloaded and extracted Apache Kafka, so I can use the command line instruments out there reminiscent of kafka-configs.sh and kafka-topics.sh within the bin/ listing. It’s essential to maintain this in thoughts as we progress by way of the next sections of configuring Amazon MSK, and configuring and verifying the Kafka client.
In your comfort, I’ve supplied an AWS CloudFormation template for this setup within the Assets part on the finish of this submit.
Amazon MSK configuration
There may be one dealer configuration and one client configuration that we have to modify as a way to enable shoppers to fetch from the closest duplicate. These are dealer.rack on the shoppers and duplicate.selector.class on the brokers.
As beforehand talked about, Amazon MSK mechanically units a dealer’s dealer.rack setting in line with Availability Zone. As a result of we’re utilizing Amazon MSK on this instance, this implies the dealer.rack configuration on every dealer is already configured for us, however let’s confirm that.
We are able to verify the dealer.rack setting in a number of other ways. As one instance, we will use the kafka-configs.sh script from my beforehand talked about EC2 occasion:
Relying on the environment, we should always obtain one thing much like the next outcome:
Be aware that BOOTSTRAP is simply an surroundings variable set to my cluster’s bootstrap server connection string. I set it beforehand with export BOOTSTRAP=<cluster particular>;
For instance: export BOOTSTRAP=b-1.myTestCluster.123z8u.c2.kafka.us-east-1.amazonaws.com:9092,b-2.myTestCluster.123z8u.c2.kafka.us-east-1.amazonaws.com:9092
For extra info on bootstrap servers, consult with Getting the bootstrap brokers for an Amazon MSK cluster.
From the command outcomes, we will see dealer.rack is ready to use1-az4 for dealer 1. The worth use1-az4 is decided from Availability Zone to Availability Zone ID mapping. You’ll be able to view this mapping on the Amazon Digital Non-public Cloud (Amazon VPC) console on the Subnets web page, as proven within the following screenshot.
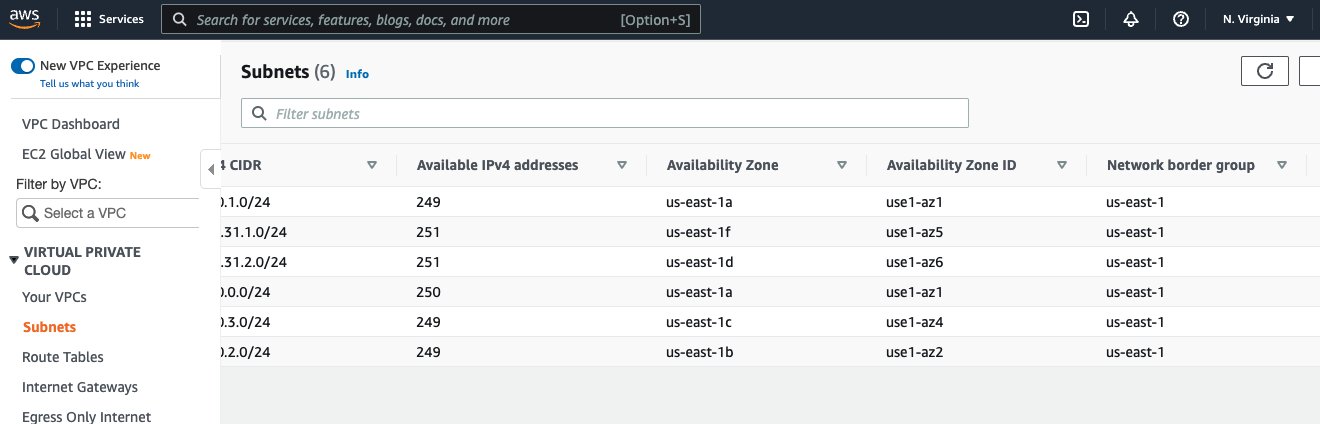
Within the previous screenshot, we will see the Availability Zone ID use1-az4. We word this worth for later use in our client configuration adjustments.
The dealer setting we have to set is duplicate.selector.class. On this case, the default worth for the configuration in Amazon MSK is null. See the next code:
This ends in the next:
That’s okay, as a result of Amazon MSK permits duplicate.selector.class to be overridden. For extra info, consult with Customized MSK configurations.
To override this setting, we have to affiliate a cluster configuration with this key set to org.apache.kafka.widespread.duplicate.RackAwareReplicaSelector. For instance, I’ve up to date and utilized the configuration of the MSK cluster used on this submit with the next:
The next screenshot exhibits the configuration.
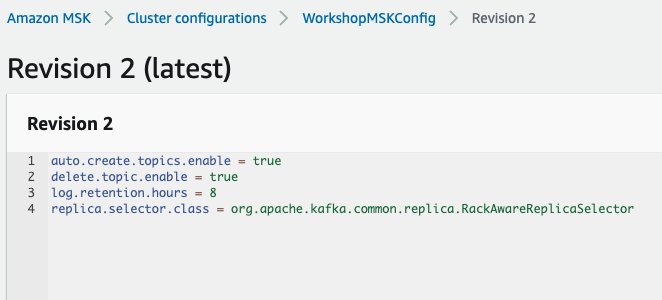
To study extra about making use of cluster configurations, see Amazon MSK configuration.
After updating the cluster’s configuration with this configuration, we will confirm it’s lively within the brokers with the next code:
We get the next outcomes:
With these two dealer settings in place, we’re prepared to maneuver on to the patron configuration.
Kafka client configuration and verification
On this part, we cowl an instance of working a client that’s rack conscious vs. one that’s not. We confirm by inspecting log information as a way to evaluate the outcomes of various configuration settings.
To carry out this comparability, let’s create a subject with six partitions and replication issue of three:
A replication issue of three means the chief partition is in a single Availability Zone, whereas the 2 replicas are distributed throughout every remaining Availability Zone. This offers a handy setup to check and confirm our client as a result of the patron is deployed in considered one of these Availability Zones. This enables us to check and make sure that the patron by no means crosses Availability Zone boundaries to fetch as a result of both the chief partition or duplicate copy is all the time out there from the dealer in the identical Availability Zone as the patron.
Let’s load pattern knowledge into the order subject utilizing the MSK Knowledge Generator with the next configuration:
Find out how to use the MSK Knowledge Generator is past the scope of this submit, however we generate pattern knowledge to the order subject with a random key (Web.uuid) and key pair values of product_id, amount, and customer_id. For our functions, it’s essential the generated key’s random sufficient to make sure the information is evenly distributed throughout partitions.
To confirm our client is studying from the closest duplicate, we have to flip up the logging. As a result of we’re utilizing the bin/kafka-console-consumer.sh script included with Apache Kafka distribution, we will replace the config/tools-log4j.properties file to affect the logging of scripts run within the bin/ listing, together with kafka-console-consumer.sh. We simply want so as to add one line:
The next code is the related portion from my config/tools-log4j.properties file:
Now we’re prepared to check and confirm from a client.
Let’s devour with out rack consciousness first:
We get outcomes reminiscent of the next:
We get rack: values as use1-az2, use1-az4, and use1-az1. This may fluctuate for every cluster.
That is anticipated as a result of we’re producing knowledge evenly throughout the order subject partitions and haven’t configured kafka-console-consumer.sh to fetch from followers but.
Let’s cease this client and rerun it to fetch from the closest duplicate this time. The EC2 occasion on this instance is situated in Availability Zone us-east-1, which implies the Availability Zone ID is use1-az1, as beforehand mentioned. To set this in our client, we have to set the consumer.rack configuration property as proven when working the next command:
Now, the log outcomes present a distinction:
For every log line, we now have two rack: values. The primary rack: worth exhibits the present chief, the second rack: exhibits the rack that’s getting used to fetch messages.
For a selected instance, think about the next line from the previous instance code:
The chief is recognized as rack: use1-az2, however the fetch request is shipped to use1-az1 as indicated by to node b-3.mskcluster-msk.jcojml.c23.kafka.us-east-1.amazonaws.com:9092 (id: 3 rack: use1-az1) (org.apache.kafka.purchasers.client.internals.Fetcher).
You’ll see one thing comparable in all different log traces. The fetch is all the time to the dealer in use1-az1.
And there we’ve it! We’re consuming from the closest duplicate.
Conclusion
With closest duplicate fetch, it can save you as a lot as two-thirds of your cross-Availability Zone visitors costs when consuming from Kafka subjects, as a result of your shoppers can learn from replicas in the identical Availability Zone as an alternative of getting to cross Availability Zone boundaries to learn from the chief. On this submit, we supplied a background on Apache Kafka rack consciousness and the way Amazon MSK mechanically units brokers to be rack conscious in line with Availability Zone deployment. Then we demonstrated learn how to configure your MSK cluster and client purchasers to make the most of rack consciousness and keep away from cross-Availability Zone community costs.
Assets
You need to use the next CloudFormation template to create the instance MSK cluster and EC2 occasion with Apache Kafka downloaded and extracted. Be aware that this template requires the described WorkshopMSKConfig customized MSK configuration to be pre-created earlier than working the template.
In regards to the writer
 Todd McGrath is a knowledge streaming specialist at Amazon Internet Providers the place he advises clients on their streaming methods, integration, structure, and options. On the private facet, he enjoys watching and supporting his 3 youngsters of their most popular actions in addition to following his personal pursuits reminiscent of fishing, pickleball, ice hockey, and completely satisfied hour with family and friends on pontoon boats. Join with him on LinkedIn.
Todd McGrath is a knowledge streaming specialist at Amazon Internet Providers the place he advises clients on their streaming methods, integration, structure, and options. On the private facet, he enjoys watching and supporting his 3 youngsters of their most popular actions in addition to following his personal pursuits reminiscent of fishing, pickleball, ice hockey, and completely satisfied hour with family and friends on pontoon boats. Join with him on LinkedIn.

{kind=link}