
Enterprise Leaders typically have to make choices which might be influenced by a
big selection of exercise all through the entire enterprise.
For instance a producer understanding gross sales
margins would possibly require details about the price of uncooked supplies,
working prices of producing services, gross sales ranges and costs.
The appropriate data, aggregated by area, market, or for the whole
group must be obtainable in a understandable type.
A Crucial Aggregator is a software program part that is aware of which methods to
“go to” to extract this data, which information/tables/APIs to examine,
tips on how to relate data from totally different sources, and the enterprise logic
wanted to mixture this knowledge.
It supplies this data to enterprise leaders by means of printed tables,
a dashboard with charts and tables, or a knowledge feed that goes into
shoppers’ spreadsheets.
By their very nature these stories contain pulling knowledge from many alternative
components of a enterprise, for instance monetary knowledge, gross sales knowledge, buyer knowledge
and so forth. When carried out utilizing good practices akin to encapsulation
and separation of issues this does not create any specific architectural
problem. Nonetheless we frequently see particular points when this requirement is
carried out on high of legacy methods, particularly monolithic mainframes or
knowledge warehouses.
Inside legacy the implementation of this sample nearly all the time takes benefit
of with the ability to attain immediately into sub-components to fetch the information it
wants throughout processing. This units up a very nasty coupling,
as upstream methods are then unable to evolve their knowledge constructions due
to the chance of breaking the now Invasive Crucial Aggregator .
The consequence of such a failure being significantly excessive,
and visual, as a consequence of its important position in supporting the enterprise and it is
leaders.
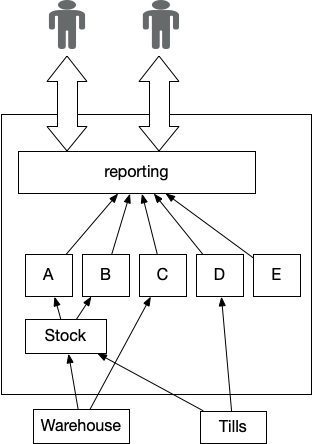
Determine 1: Reporting utilizing Pervasive Aggregator
How It Works
Firstly we outline what
enter knowledge is required to supply a output, akin to a report. Often the
supply knowledge is already current inside parts of the general structure.
We then create an implementation to “load” within the supply knowledge and course of
it to create our output. Key right here is to make sure we do not create
a good coupling to the construction of the supply knowledge, or break encapsulation
of an current part to achieve the information we’d like. At a database degree this
is perhaps achieved by way of ETL (Extract, Remodel, Load), or by way of an API at
the service degree. It’s value noting that ETL approaches typically turn into
coupled to both the supply or vacation spot format; long term this may
turn into a barrier to vary.
The processing could also be completed record-by-record, however for extra complicated eventualities
intermediate state is perhaps wanted, with the subsequent step in processing being
triggered as soon as this intermediate knowledge is prepared.
Thus many implementations use a Pipeline, a sequence of
Pipes and Filters,
with the output of 1 step changing into an enter for the subsequent step.
The timeliness of the information is a key consideration, we’d like to ensure
we use supply knowledge on the right occasions, for instance after the tip
of a buying and selling day. This could create timing dependencies between the aggregator
and the supply methods.
One method is to set off issues at particular occasions,
though this method is weak to delays in any supply system.
e.g. run the aggregator at 3am, nevertheless ought to there be a delay in any
supply methods the aggregated outcomes is perhaps based mostly on stale or corrupt knowledge.
One other
extra sturdy method is to have supply methods ship or publish the supply knowledge
as soon as it’s prepared, with the aggregator being triggered as soon as all knowledge is
obtainable. On this case the aggregated outcomes are delayed however ought to
at the very least be based mostly upon legitimate enter knowledge.
We will additionally guarantee supply knowledge is timestamped though this depends
on the supply methods already having the right time knowledge obtainable or being simple
to vary, which could not be the case for legacy methods. If timestamped
knowledge is out there we will apply extra superior processing to make sure
constant and legitimate outcomes, akin to
Versioned Worth.
When to Use It
This sample is used when we have now a real have to get an total
view throughout many alternative components or domains inside a enterprise, normally
when we have to correlate knowledge from totally different domains right into a abstract
view or set of metrics which might be used for resolution assist.
Legacy Manifestation
Given previous limitations on community bandwidth and I/O speeds it typically made
sense to co-locate knowledge processing on the identical machine as the information storage.
Excessive volumes of knowledge storage with cheap entry occasions typically
required specialised {hardware}, this led to centralized knowledge storage
options. These two forces collectively mixed to make many legacy
implementations of this sample tightly coupled to supply knowledge constructions,
depending on knowledge replace schedules and timings, with implementations typically
on the identical {hardware} as the information storage.
The ensuing Invasive Crucial Aggregator places its
roots into many alternative components of
the general system – thus making it very difficult to extract.
Broadly talking there are two approaches to displacement. The
first method is to create a brand new implementation of Crucial Aggregator,
which might be completed by Divert the Stream, mixed with different patterns
akin to Revert to Supply. The choice, extra frequent method, is to depart
the aggregator in place however use methods such a Legacy Mimic to offer
the required knowledge all through displacement. Clearly a brand new implementation
is required finally.
Challenges with Invasive Crucial Aggregator
Most legacy implementations of Crucial Aggregator are characterised
by the dearth of encapsulation across the supply
knowledge, with any processing immediately depending on the construction and
type of the assorted supply knowledge codecs. Additionally they have poor separation of
issues with Processing and Knowledge Entry code intermingled. Most implementations
are written in batch knowledge processing languages.
The anti-pattern is characterised by a excessive quantity of coupling
inside a system, particularly as implementations attain immediately into supply knowledge with none
encapsulation. Thus any change to the supply knowledge construction will instantly
impression the processing and outputs. A standard method to this drawback is
to freeze supply knowledge codecs or so as to add a change management course of on
all supply knowledge. This variation management course of can turn into extremely complicated particularly
when giant hierarchies of supply knowledge and methods are current.
Invasive Crucial Aggregator additionally tends to scale poorly as knowledge quantity grows for the reason that lack
of encapsulation makes introduction of any optimization or parallel processing
problematic, we see
execution time tending to develop with knowledge volumes. Because the processing and
knowledge entry mechanisms are coupled collectively this may result in a have to
vertically scale a whole system. This can be a very costly technique to scale
processing that in a greater encapsulated system may
be completed by commodity {hardware} separate from any knowledge storage.
Invasive Crucial Aggregator tends to be inclined to timing points. Late replace
of supply knowledge would possibly delay aggregation or trigger it to run on stale knowledge,
given the important nature of the aggregated stories this may trigger severe
points for a enterprise.
The direct entry to the supply knowledge throughout
processing means implementations normally have an outlined “secure time window”
the place supply knowledge should be up-to-date whereas remaining secure and unchanging.
These time home windows should not normally enforced by the system(s)
however as an alternative are sometimes a conference, documented elsewhere.
As processing length grows this may create timing constraints for the methods
that produce the supply knowledge. If we have now a hard and fast time the ultimate output
should be prepared then any improve in processing time in flip means any supply knowledge should
be up-to-date and secure earlier.
These numerous timing constraints make incorporating knowledge
from totally different time zones problematic as any in a single day “secure time window”
would possibly begin to overlap with regular working hours elsewhere on the earth.
Timing and triggering points are a quite common supply of error and bugs
with this sample, these might be difficult to diagnose.
Modification and testing can also be difficult because of the poor separation of
issues between processing and supply knowledge entry. Over time this code grows
to include workarounds for bugs, supply knowledge format adjustments, plus any new
options. We usually discover most legacy implementations of the Crucial Aggregator are in a “frozen” state as a consequence of these challenges alongside the enterprise
threat of the information being incorrect. As a result of tight coupling any change
freeze tends to unfold to the supply knowledge and therefore corresponding supply methods.
We additionally are likely to see ‘bloating’ outputs for the aggregator, since given the
above points it’s
typically less complicated to increase an current report so as to add a brand new piece of knowledge than
to create a model new report. This will increase the implementation dimension and
complexity, in addition to the enterprise important nature of every report.
It might probably additionally make alternative more durable as we first want to interrupt down every use
of the aggregator’s outputs to find if there are separate customers
cohorts whose wants might be met with less complicated extra focused outputs.
It’s common to see implementations of this (anti-)sample in COBOL and assembler
languages, this demonstrates each the problem in alternative however
additionally how important the outputs might be for a enterprise.

{kind=link}