

Constructing a knowledge platform entails varied approaches, every with its distinctive mix of complexities and options. A contemporary knowledge platform entails sustaining knowledge throughout a number of layers, focusing on various platform capabilities like excessive efficiency, ease of growth, cost-effectiveness, and DataOps options equivalent to CI/CD, lineage, and unit testing. On this publish, we delve right into a case examine for a retail use case, exploring how the Information Construct Instrument (dbt) was used successfully inside an AWS atmosphere to construct a high-performing, environment friendly, and trendy knowledge platform.
dbt is an open-source command line instrument that allows knowledge analysts and engineers to rework knowledge of their warehouses extra successfully. It does this by serving to groups deal with the T in ETL (extract, rework, and cargo) processes. It permits customers to put in writing knowledge transformation code, run it, and check the output, all inside the framework it gives. dbt allows you to write SQL choose statements, after which it manages turning these choose statements into tables or views in Amazon Redshift.
Use case
The Enterprise Information Analytics group of a giant jewellery retailer launched into their cloud journey with AWS in 2021. As a part of their cloud modernization initiative, they sought emigrate and modernize their legacy knowledge platform. The intention was to bolster their analytical capabilities and enhance knowledge accessibility whereas making certain a fast time to market and excessive knowledge high quality, all with low whole price of possession (TCO) and no want for added instruments or licenses.
dbt emerged as the proper alternative for this transformation inside their present AWS atmosphere. This fashionable open-source instrument for knowledge warehouse transformations gained out over different ETL instruments for a number of causes. dbt’s SQL-based framework made it simple to study and allowed the present growth crew to scale up rapidly. The instrument additionally provided fascinating out-of-the-box options like knowledge lineage, documentation, and unit testing. An important benefit of dbt over saved procedures was the separation of code from knowledge—not like saved procedures, dbt doesn’t retailer the code within the database itself. This separation additional simplifies knowledge administration and enhances the system’s general efficiency.
Let’s discover the structure and discover ways to construct this use case utilizing AWS Cloud companies.
Answer overview
The next structure demonstrates the info pipeline constructed on dbt to handle the Redshift knowledge warehouse ETL course of.
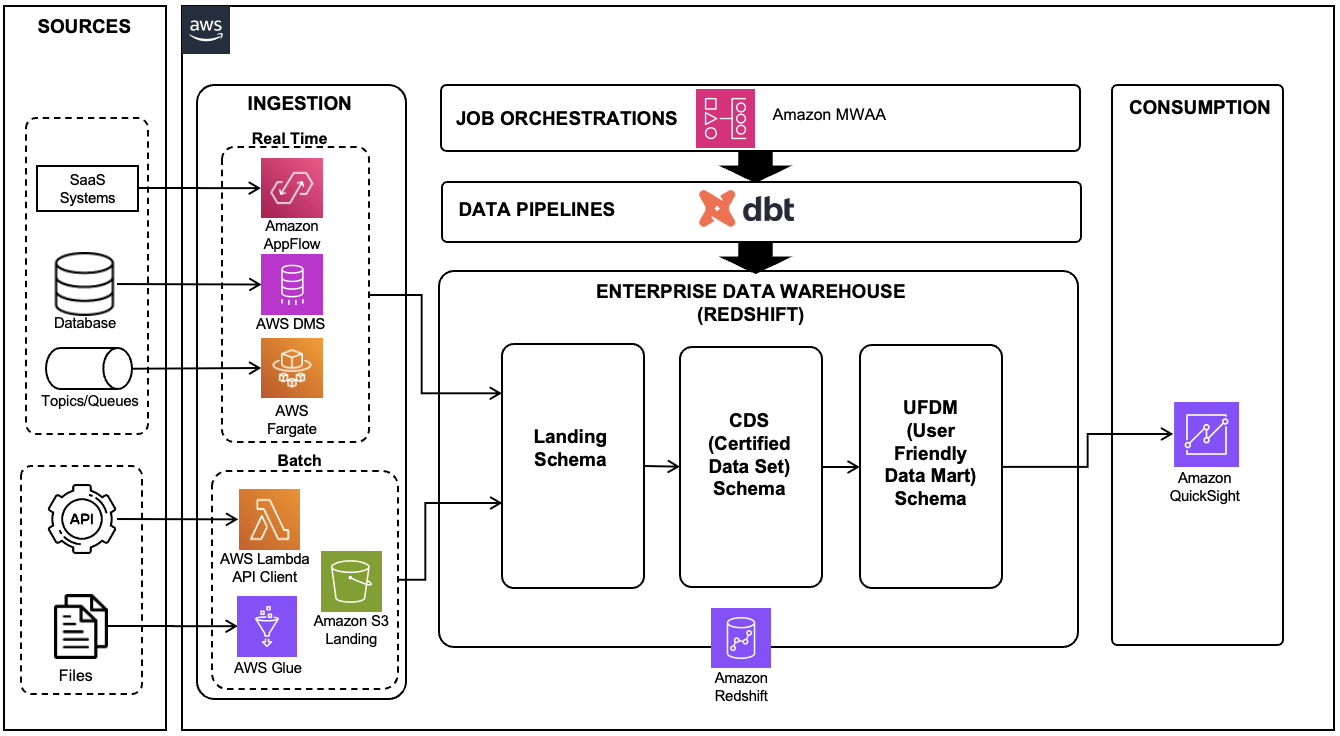
Determine 1 : Trendy knowledge platform utilizing AWS Information Providers and dbt
This structure consists of the next key companies and instruments:
- Amazon Redshift was utilized as the info warehouse for the info platform, storing and processing huge quantities of structured and semi-structured knowledge
- Amazon QuickSight served because the enterprise intelligence (BI) instrument, permitting the enterprise crew to create analytical reviews and dashboards for varied enterprise insights
- AWS Database Migration Service (AWS DMS) was employed to carry out change knowledge seize (CDC) replication from varied supply transactional databases
- AWS Glue was put to work, loading recordsdata from the SFTP location to the Amazon Easy Storage Service (Amazon S3) touchdown bucket and subsequently to the Redshift touchdown schema
- AWS Lambda functioned as a shopper program, calling third-party APIs and loading the info into Redshift tables
- AWS Fargate, a serverless container administration service, was used to deploy the buyer utility for supply queues and matters
- Amazon Managed Workflows for Apache Airflow (Amazon MWAA) was used to orchestrate totally different duties of dbt pipelines
- dbt, an open-source instrument, was employed to put in writing SQL-based knowledge pipelines for knowledge saved in Amazon Redshift, facilitating complicated transformations and enhancing knowledge modeling capabilities
Let’s take a better have a look at every part and the way they work together within the general structure to rework uncooked knowledge into insightful info.
Information sources
As a part of this knowledge platform, we’re ingesting knowledge from various and different knowledge sources, together with:
- Transactional databases – These are energetic databases that retailer real-time knowledge from varied functions. The information sometimes encompasses all transactions and operations that the enterprise engages in.
- Queues and matters – Queues and matters come from varied integration functions that generate knowledge in actual time. They signify an instantaneous stream of knowledge that can be utilized for real-time analytics and decision-making.
- Third-party APIs – These present analytics and survey knowledge associated to ecommerce web sites. This might embrace particulars like visitors metrics, consumer conduct, conversion charges, buyer suggestions, and extra.
- Flat recordsdata – Different programs provide knowledge within the type of flat recordsdata of various codecs. These recordsdata, saved in an SFTP location, may comprise data, reviews, logs, or other forms of uncooked knowledge that may be additional processed and analyzed.
Information ingestion
Information from varied sources are grouped into two main classes: real-time ingestion and batch ingestion.
Actual-time ingestion makes use of the next companies:
- AWS DMS – AWS DMS is used to create CDC replication pipelines from OLTP (On-line Transaction Processing) databases. The information is loaded into Amazon Redshift in near-real time to make sure that the newest info is on the market for evaluation. You too can use Amazon Aurora zero-ETL integration with Amazon Redshift to ingest knowledge immediately from OLTP databases to Amazon Redshift.
- Fargate –Fargate is used to deploy Java shopper functions that ingest knowledge from supply matters and queues in actual time. This real-time knowledge consumption can assist the enterprise make speedy and data-informed selections. You too can use Amazon Redshift Streaming Ingestion to ingest knowledge from streaming engines like Amazon Kinesis Information Streams or Amazon Managed Streaming for Apache Kafka (Amazon MSK) into Amazon Redshift.
Batch ingestion makes use of the next companies:
- Lambda – Lambda is used as a shopper for calling third-party APIs and loading the resultant knowledge into Redshift tables. This course of has been scheduled to run every day, making certain a constant batch of recent knowledge for evaluation.
- AWS Glue – AWS Glue is used to load recordsdata into Amazon Redshift by means of the S3 knowledge lake. You too can use options like auto-copy from Amazon S3 (function beneath preview) to ingest knowledge from Amazon S3 to Amazon Redshift. Nevertheless, the main target of this publish is extra on knowledge processing inside Amazon Redshift, somewhat than on the info loading course of. Information ingestion, whether or not actual time or batch, varieties the idea of any efficient knowledge evaluation, enabling organizations to collect info from various sources and use it for insightful decision-making.
Information warehousing utilizing Amazon Redshift
In Amazon Redshift, we’ve established three schemas, every serving as a special layer within the knowledge structure:
- Touchdown layer – That is the place all knowledge ingested by our companies initially lands. It’s uncooked, unprocessed knowledge straight from the supply.
- Licensed dataset (CDS) layer – That is the following stage, the place knowledge from the touchdown layer undergoes cleansing, normalization, and aggregation. The cleansed and processed knowledge is saved on this licensed dataset schema. It serves as a dependable, organized supply for downstream knowledge evaluation.
- Person-friendly knowledge mart (UFDM) layer – This remaining layer makes use of knowledge from the CDS layer to create knowledge mart tables. These are particularly tailor-made to assist BI reviews and dashboards as per the enterprise necessities. The aim of this layer is to current the info in a means that’s most helpful and accessible for end-users.
This layered strategy to knowledge administration permits for environment friendly and arranged knowledge processing, resulting in extra correct and significant insights.
Information pipeline
dbt, an open-source instrument, will be put in within the AWS atmosphere and set as much as work with Amazon MWAA. We retailer our code in an S3 bucket and orchestrate it utilizing Airflow’s Directed Acyclic Graphs (DAGs). This setup facilitates our knowledge transformation processes in Amazon Redshift after the info is ingested into the touchdown schema.
To take care of modularity and deal with particular domains, we create particular person dbt tasks. The character of the info reporting—real-time or batch—impacts how we outline our dbt materialization. For real-time reporting, we outline materialization as a view, loading knowledge into the touchdown schema utilizing AWS DMS from database updates or from subject or queue shoppers. For batch pipelines, we outline materialization as a desk, permitting knowledge to be loaded from varied varieties of sources.
In some cases, now we have needed to construct knowledge pipelines that reach from the supply system all the way in which to the UFDM layer. This may be completed utilizing Airflow DAGs, which we talk about additional within the subsequent part.
To wrap up, it’s value mentioning that we deploy a dbt webpage utilizing a Lambda operate and allow a URL for this operate. This webpage serves as a hub for documentation and knowledge lineage, additional bolstering the transparency and understanding of our knowledge processes.
ETL job orchestration
In our knowledge pipeline, we comply with these steps for job orchestration:
- Set up a brand new Amazon MWAA atmosphere. This atmosphere serves because the central hub for orchestrating our knowledge pipelines.
- Set up dbt within the new Airflow atmosphere by including the next dependency to your
necessities.txt: - Develop DAGs with particular duties that decision upon dbt instructions to hold out the required transformations. This step entails structuring our workflows in a means that captures dependencies amongst duties and ensures that duties run within the right order. The next code exhibits easy methods to outline the duties within the DAG:
- Create DAGs that solely deal with dbt transformation. These DAGs deal with the transformation course of inside our knowledge pipelines, harnessing the ability of dbt to transform uncooked knowledge into helpful insights.
The next picture exhibits how this workflow could be seen on the Airflow UI . 
- Create DAGs with AWS Glue for ingestion. These DAGs use AWS Glue for knowledge ingestion duties. AWS Glue is a completely managed ETL service that makes it simple to arrange and cargo knowledge for evaluation. We create DAGs that orchestrate AWS Glue jobs for extracting knowledge from varied sources, remodeling it, and loading it into our knowledge warehouse.
The next picture exhibits how this workflow could be seen on the Airflow UI.

- Create DAGs with Lambda for ingestion. Lambda lets us run code with out provisioning or managing servers. These DAGs use Lambda capabilities to name third-party APIs and cargo knowledge into our Redshift tables, which will be scheduled to run at sure intervals or in response to particular occasions.
The next picture exhibits how this workflow could be seen on the Airflow UI.

We now have a complete, well-orchestrated course of that makes use of a wide range of AWS companies to deal with totally different phases of our knowledge pipeline, from ingestion to transformation.
Conclusion
The mix of AWS companies and the dbt open-source undertaking gives a strong, versatile, and scalable resolution for constructing trendy knowledge platforms. It’s an ideal mix of manageability and performance, with its easy-to-use, SQL-based framework and options like knowledge high quality checks, configurable load varieties, and detailed documentation and lineage. Its ideas of “code separate from knowledge” and reusability make it a handy and environment friendly instrument for a variety of customers. This sensible use case of constructing a knowledge platform for a retail group demonstrates the immense potential of AWS and dbt for remodeling knowledge administration and analytics, paving the way in which for sooner insights and knowledgeable enterprise selections.
For extra details about utilizing dbt with Amazon Redshift, see Handle knowledge transformations with dbt in Amazon Redshift.
In regards to the Authors
 Prantik Gachhayat is an Enterprise Architect at Infosys having expertise in varied expertise fields and enterprise domains. He has a confirmed observe file serving to massive enterprises modernize digital platforms and delivering complicated transformation packages. Prantik focuses on architecting trendy knowledge and analytics platforms in AWS. Prantik loves exploring new tech tendencies and enjoys cooking.
Prantik Gachhayat is an Enterprise Architect at Infosys having expertise in varied expertise fields and enterprise domains. He has a confirmed observe file serving to massive enterprises modernize digital platforms and delivering complicated transformation packages. Prantik focuses on architecting trendy knowledge and analytics platforms in AWS. Prantik loves exploring new tech tendencies and enjoys cooking.
 Ashutosh Dubey is a Senior Associate Options Architect and World Tech chief at Amazon Internet Providers based mostly out of New Jersey, USA. He has in depth expertise specializing within the Information and Analytics and AIML subject together with generative AI, contributed to the group by writing varied tech contents, and has helped Fortune 500 corporations of their cloud journey to AWS.
Ashutosh Dubey is a Senior Associate Options Architect and World Tech chief at Amazon Internet Providers based mostly out of New Jersey, USA. He has in depth expertise specializing within the Information and Analytics and AIML subject together with generative AI, contributed to the group by writing varied tech contents, and has helped Fortune 500 corporations of their cloud journey to AWS.

{kind=link}