
Detection engineers and menace hunters perceive that focusing on adversary behaviors is a vital a part of an efficient detection technique (assume Pyramid of Ache). But, inherent in focusing analytics on adversary behaviors is that malicious habits will typically sufficient overlap with benign habits in your surroundings, particularly as adversaries attempt to mix in and more and more stay off the land. Think about you’re making ready to deploy a behavioral analytic to enhance your detection technique. Doing so might embody customized improvement, making an attempt out a brand new Sigma rule, or new behavioral detection content material out of your safety data and occasion administration (SIEM) vendor. Maybe you’re contemplating automating a earlier hunt, however sadly you discover that the goal habits is frequent in your surroundings.
Is that this a nasty detection alternative? Not essentially. What are you able to do to make the analytic outputs manageable and never overwhelm the alert queue? It’s typically mentioned that you have to tune the analytic in your surroundings to scale back the false optimistic price. However are you able to do it with out sacrificing analytic protection? On this put up, I focus on a course of for tuning and associated work you are able to do to make such analytics extra viable in your surroundings. I additionally briefly focus on correlation, an alternate and complementary means to handle noisy analytic outputs.
Tuning the Analytic
As you’re growing and testing the analytic, you’re inevitably assessing the next key questions, the solutions to which in the end dictate the necessity for tuning:
- Does the analytic accurately establish the goal habits and its variations?
- Does the analytic establish different habits completely different than the intention?
- How frequent is the habits in your surroundings?
Right here, let’s assume the analytic is correct and pretty strong in an effort to concentrate on the final query. Given these assumptions, let’s depart from the colloquial use of the time period false optimistic and as a substitute use benign optimistic. This time period refers to benign true optimistic occasions wherein the analytic accurately identifies the goal habits, however the habits displays benign exercise.
If the habits mainly by no means occurs, or occurs solely often, then the variety of outputs will sometimes be manageable. You may settle for these small numbers and proceed to documenting and deploying the analytic. Nonetheless, on this put up, the goal habits is frequent in your surroundings, which implies you have to tune the analytic to stop overwhelming the alert queue and to maximise the potential sign of its outputs. At this level, the fundamental goal of tuning is to scale back the variety of outcomes produced by the analytic. There are usually two methods to do that:
- Filter out the noise of benign positives (our focus right here).
- Alter the specificity of the analytic.
Whereas not the main target of this put up, let’s briefly focus on adjusting the specificity of the analytic. Adjusting specificity means narrowing the view of the analytic, which entails adjusting its telemetry supply, logical scope, and/or environmental scope. Nonetheless, there are protection tradeoffs related to doing this. Whereas there’s all the time a steadiness to be struck because of useful resource constraints, on the whole it’s higher (for detection robustness and sturdiness) to forged a large internet; that’s, select telemetry sources and assemble analytics that broadly establish the goal habits throughout the broadest swath of your surroundings. Primarily, you’re selecting to just accept a bigger variety of attainable outcomes in an effort to keep away from false negatives (i.e., fully lacking doubtlessly malicious cases of the goal habits). Subsequently, it’s preferable to first focus tuning efforts on filtering out benign positives over adjusting specificity, if possible.
Filtering Out Benign Positives
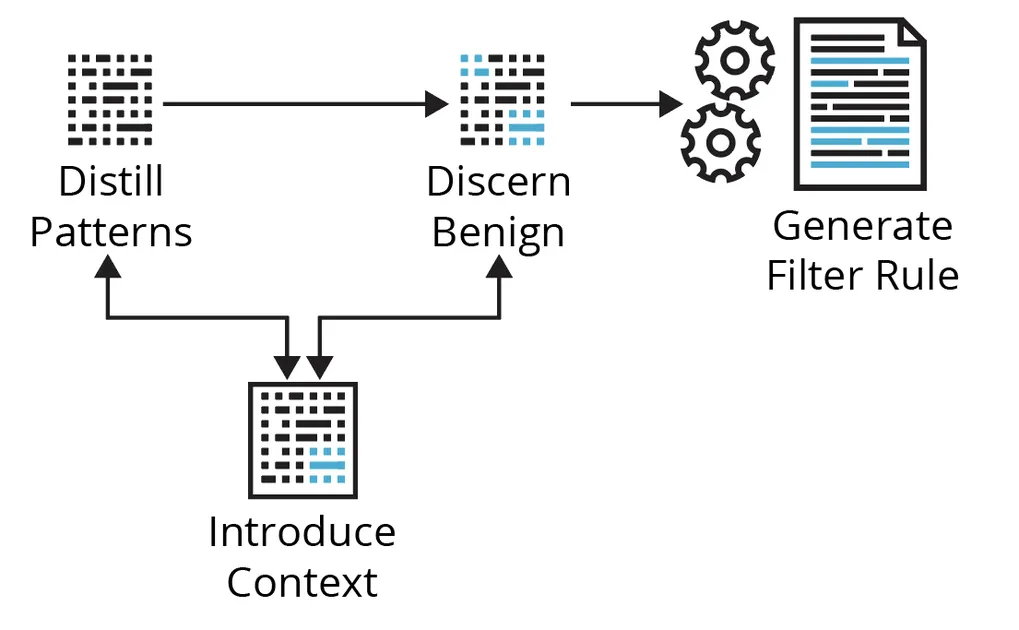
Operating the analytic during the last, say, week of manufacturing telemetry, you’re offered with a desk of quite a few outcomes. Now what? Determine 1 beneath exhibits the cyclical course of we’ll stroll via utilizing a few examples focusing on Kerberoasting and Non-Normal Port methods.
Determine 1: A Primary Course of for Filtering Out Benign Positives
Distill Patterns
Coping with quite a few analytic outcomes doesn’t essentially imply it’s a must to observe down each individually or have a filter for every outcome—the sheer quantity makes that impractical. Lots of of outcomes can doubtlessly be distilled to some filters—it depends upon the accessible context. Right here, you’re trying to discover the info to get a way of the highest entities concerned, the number of related contextual values (context cardinality), how typically these change (context velocity), and which related fields could also be summarized. Begin with entities or values related to essentially the most outcomes; that’s, attempt to deal with the most important chunks of associated occasions first.
Examples
- Kerberoasting—Say this Sigma rule returns outcomes with many various AccountNames and ClientAddresses (excessive context cardinality), however most outcomes are related to comparatively few ServiceNames (of sure legacy units; low context cardinality) and TicketOptions. You broaden the search to the final 30 days and discover the ServiceNames and TicketOptions are a lot the identical (low context velocity), however different related fields have extra and/or completely different values (excessive context velocity). You’d concentrate on these ServiceNames and/or TicketOptions, affirm it’s anticipated/identified exercise, then deal with a giant chunk of the outcomes with a single filter towards these ServiceNames.
- Non-Normal Port—On this instance, you discover there’s excessive cardinality and excessive velocity in nearly each occasion/community circulation area, apart from the service/software label, which signifies that solely SSL/TLS is getting used on non-standard ports. Once more, you broaden the search and spot plenty of completely different supply IPs that might be summarized by a single Classless Inter-Area Routing (CIDR) block, thus abstracting the supply IP into a chunk of low-cardinality, low-velocity context. You’d concentrate on this obvious subnet, making an attempt to grasp what it’s and any related controls round it, affirm its anticipated and/or identified exercise, then filter accordingly.
Happily, there are normally patterns within the knowledge which you can concentrate on. You usually need to goal context with low cardinality and low velocity as a result of it impacts the long-term effectiveness of your filters. You don’t need to consistently be updating your filter guidelines by counting on context that adjustments too typically when you may help it. Nonetheless, typically there are numerous high-cardinality, high-velocity fields, and nothing fairly stands out from primary stacking, counting, or summarizing. What when you can’t slender the outcomes as is? There are too many outcomes to analyze each individually. Is that this only a unhealthy detection alternative? Not but.
Discern Benign
The principle concern on this exercise is shortly gathering enough context to disposition analytic outputs with a suitable stage of confidence. Context is any knowledge or data that meaningfully contributes to understanding and/or deciphering the circumstances/circumstances wherein an occasion/alert happens, to discern habits as benign, malicious, or suspicious/unknown. Desk 1 beneath describes the most typical varieties of context that you’ll have or search to assemble.
Desk 1: Widespread Sorts of Context
|
Sort |
Description |
Typical Sources |
Instance(s) |
| Occasion | primary properties/parameters of the occasion that assist outline it | uncooked telemetry, log fields |
course of creation fields, community circulation fields, course of community connection fields, Kerberos service ticket request fields |
| Environmental | knowledge/details about the monitored surroundings or property within the monitored surroundings |
CMDB /ASM/IPAM, ticket system, documentation, the brains of different analysts, admins, engineers, system/community homeowners |
enterprise processes, community structure, routing, proxies, NAT, insurance policies, accepted change requests, providers used/uncovered, identified vulnerabilities, asset possession, {hardware}, software program, criticality, location, enclave, and so forth. |
| Entity | knowledge/details about the entities (e.g., id, supply/vacation spot host, course of, file) concerned within the occasion |
IdP /IAM, EDR, CMDB /ASM/IPAM, Third-party APIs |
• enriching a public IP deal with with geolocation, ASN information, passive DNS, open ports/protocols/providers, certificates data
• enriching an id with description, sort, position, privileges, division, location, and so forth. |
| Historic | • how typically the occasion occurs
• how typically the occasion occurs with sure traits or entities, and/or • how typically there’s a relationship between choose entities concerned within the occasion |
baselines | • profiling the final 90 days of DNS requests per top-level area (TLD)
• profiling the final 90 days of HTTP on non-standard ports •profiling course of lineage |
| Menace | • assault (sub-)method(s)
• instance process(s) • seemingly assault stage • particular and/or sort of menace actor/malware/software identified to exhibit the habits • popularity, scoring, and so forth. |
menace intelligence platform (TIP), MITRE ATT&CK, menace intelligence APIs, documentation |
popularity/detection scores, Sysmon-modular annotations; ADS instance |
| Analytic | • how and why this occasion was raised
• any related values produced/derived by the analytic itself • the analytic logic, identified/frequent benign instance(s) • really useful follow-on actions • scoring, and so forth. |
analytic processing,
documentation, runbooks |
“occasion”: { “processing”: { “time_since_flow_start”: “0:04:08.641718”, “period”: 0.97 }, “cause”: “SEEN_BUT_RARELY_OCCURRING”, “consistency_score”: 95 } |
| Correlation | knowledge/data from related occasions/alerts (mentioned beneath in Aggregating the Sign ) |
SIEM/SOAR, customized correlation layer |
risk-based alerting, correlation guidelines |
| Open-source | knowledge/data usually accessible through Web search engines like google and yahoo | Web | vendor documentation states what service names they use, what different individuals have seen concerning TCP/2323 |
Upon preliminary evaluate, you’ve gotten the occasion context, however you sometimes find yourself searching for environmental, entity, and/or historic context to ideally reply (1) which identities and software program triggered this exercise, and (2) is it authentic? That’s, you’re searching for details about the provenance, expectations, controls, property, and historical past concerning the noticed exercise. But, that context might or will not be accessible or too sluggish to amass. What when you can’t inform from the occasion context? How else may you inform these occasions are benign or not? Is that this only a unhealthy detection alternative? Not but. It depends upon your choices for gathering further context and the velocity of these choices.
Introduce Context
If there aren’t apparent patterns and/or the accessible context is inadequate, you may work to introduce patterns/context through automated enrichments and baselines. Enrichments could also be from inside or exterior knowledge sources and are normally automated lookups primarily based on some entity within the occasion (e.g., id, supply/vacation spot host, course of, file, and so forth.). Even when enrichment alternatives are scarce, you may all the time introduce historic context by constructing baselines utilizing the info you’re already gathering.
With the multitude of monitoring and detection suggestions utilizing phrases resembling new, uncommon, sudden, uncommon, unusual, irregular, anomalous, by no means been seen earlier than, sudden patterns and metadata, doesn’t usually happen, and so forth., you’ll have to be constructing and sustaining baselines anyway. Nobody else can do these for you—baselines will all the time be particular to your surroundings, which is each a problem and a bonus for defenders.
Kerberoasting
Except you’ve gotten programmatically accessible and up-to-date inside knowledge sources to counterpoint the AccountName (id), ServiceName/ServiceID (id), and/or ClientAddress (supply host; sometimes RFC1918), there’s not a lot enrichment to do besides, maybe, to translate TicketOptions, TicketEncryptionType, and FailureCode to pleasant names/values. Nonetheless, you may baseline these occasions. For instance, you may observe the next over a rolling 90-day interval:
- p.c days seen per ServiceName per AccountName → establish new/uncommon/frequent user-service relationships
- imply and mode of distinctive ServiceNames per AccountName per time interval → establish uncommon variety of providers for which a consumer makes service ticket requests
You might broaden the search (solely to develop a baseline metric) to all related TicketEncryption Sorts and moreover observe
- p.c days seen per TicketEncryptionType per ServiceName → establish new/uncommon/frequent service-encryption sort relationships
- p.c days seen per TicketOptions per AccountName → establish new/uncommon/frequent user-ticket choices relationships
- p.c days seen per TicketOptions per ServiceName → establish new/uncommon/frequent service-ticket choices relationships
Non-Normal Port
Enrichment of the vacation spot IP addresses (all public) is an efficient place to begin, as a result of there are numerous free and industrial knowledge sources (already codified and programmatically accessible through APIs) concerning Web-accessible property. You enrich analytic outcomes with geolocation, ASN, passive DNS, hosted ports, protocols, and providers, certificates data, major-cloud supplier data, and so forth. You now discover that the entire connections are going to some completely different netblocks owned by a single ASN, they usually all correspond to a single cloud supplier’s public IP ranges for a compute service in two completely different areas. Furthermore, passive DNS signifies quite a few development-related subdomains all on a well-known dad or mum area. Certificates data is constant over time (which signifies one thing about testing) and has acquainted organizational identifiers.
Newness is definitely derived—the connection is both traditionally there or it isn’t. Nonetheless, you’ll want to find out and set a threshold in an effort to say what is taken into account uncommon and what’s thought-about frequent. Having some codified and programmatically accessible inside knowledge sources accessible wouldn’t solely add doubtlessly beneficial context however broaden the choices for baseline relationships and metrics. The artwork and science of baselining includes figuring out thresholds and which baseline relationships/metrics will give you significant sign.
General, with some additional engineering and evaluation work, you’re in a a lot better place to distill patterns, discern which occasions are (in all probability) benign, and to make some filtering choices. Furthermore, whether or not you construct automated enrichments and/or baseline checks into the analytic pipeline, or construct runbooks to assemble this context on the level of triage, this work feeds immediately into supporting detection documentation and enhances the general velocity and high quality of triage.
Generate Filter Rule
You need to well apply filters with out having to handle too many guidelines, however you need to accomplish that with out creating guidelines which might be too broad (which dangers filtering out malicious occasions, too). With filter/permit checklist guidelines, somewhat than be overly broad, it’s higher to lean towards a extra exact description of the benign exercise and presumably must create/handle just a few extra guidelines.
Kerberoasting
The baseline data helps you perceive that these few ServiceNames do in actual fact have a standard and constant historical past of occurring with the opposite related entities/properties of the occasions proven within the outcomes. You establish these are OK to filter out, and also you accomplish that with a single, easy filter towards these ServiceNames.
Non-Normal Port
Enrichments have offered beneficial context to assist discern benign exercise and, importantly, additionally enabled the abstraction of the vacation spot IP, a high-cardinality, high-velocity area, from many various, altering values to some broader, extra static values described by ASN, cloud, and certificates data. Given this context, you identify these connections are in all probability benign and transfer to filter them out. See Desk 2 beneath for instance filter guidelines, the place app=443 signifies SSL/TLS and major_csp=true signifies the vacation spot IP of the occasion is in one of many printed public IP ranges of a serious cloud service supplier:
|
Sort |
Filter Rule |
Motive |
|---|---|---|
|
Too broad |
sip=10.2.16.0/22; app=443; asn=16509; major_csp=true |
You don’t need to permit all non-standard port encrypted connections from the subnet to all cloud supplier public IP ranges in your complete ASN. |
|
Nonetheless too broad |
sip=10.2.16.0/22; app=443; asn=16509; major_csp=true; cloud_provider=aws; cloud_service=EC2; cloud_region=us-west-1,us-west-2 |
You don’t know the character of the inner subnet. You don’t need to permit all non-standard port encrypted site visitors to have the ability to hit simply any EC2 IPs throughout two whole areas. Cloud IP utilization adjustments as completely different prospects spin up/down sources. |
|
Finest possibility |
sip=10.2.16.0/22; app=443; asn=16509; major_csp=true; cloud_provider=aws; cloud_service=EC2; cloud_region=us-west-1,us-west-2; cert_subject_dn=‘L=Earth|O=Your Org|OU=DevTest|CN=dev.your.org’ |
It is restricted to the noticed testing exercise in your org, however broad sufficient that it shouldn’t change a lot. You’ll nonetheless find out about another non-standard port site visitors that doesn’t match all of those traits. |
An essential corollary right here is that the filtering mechanism/permit checklist must be utilized in the suitable place and be versatile sufficient to deal with the context that sufficiently describes the benign exercise. A easy filter on ServiceNames depends solely on knowledge within the uncooked occasions and could be filtered out merely utilizing an additional situation within the analytic itself. Alternatively, the Non-Normal Port filter rule depends on knowledge from the uncooked occasions in addition to enrichments, wherein case these enrichments must have been carried out and accessible within the knowledge earlier than the filtering mechanism is utilized. It’s not all the time enough to filter out benign positives utilizing solely fields accessible within the uncooked occasions. There are numerous methods you possibly can account for these filtering situations. The capabilities of your detection and response pipeline, and the best way it’s engineered, will influence your capacity to successfully tune at scale.
Mixture the Sign
Thus far, I’ve talked a few course of for tuning a single analytic. Now, let’s briefly focus on a correlation layer, which operates throughout all analytic outputs. Generally an recognized habits simply isn’t a powerful sufficient sign in isolation; it could solely change into a powerful sign in relation to different behaviors, recognized by different analytics. Correlating the outputs from a number of analytics can tip the sign sufficient to meaningfully populate the alert queue in addition to present beneficial further context.
Correlation is usually entity-based, resembling aggregating analytic outputs primarily based on a shared entity like an id, host, or course of. These correlated alerts are sometimes prioritized through scoring, the place you assign a danger rating to every analytic output. In flip, correlated alerts can have an mixture rating that’s normally the sum, or some normalized worth, of the scores of the related analytic outputs. You’d type correlated alerts by the mixture rating, the place greater scores point out entities with essentially the most, or most extreme, analytic findings.
The outputs out of your analytic don’t essentially must go on to the principle alert queue. Not every analytic output wants be triaged. Maybe the efficacy of the analytic primarily exists in offering further sign/context in relation to different analytic outputs. As correlated alerts bubble as much as analysts solely when there’s robust sufficient sign between a number of related analytic outputs, correlation serves in its place and complementary means to make the variety of outputs from a loud analytic much less of a nuisance and general outputs extra manageable.
Bettering Availability and Velocity of Related Context
All of it activates context and the necessity to shortly collect enough context. Velocity issues. Previous to operational deployment, the extra shortly and confidently you may disposition analytic outputs, the extra outputs you may cope with, the quicker and higher the tuning, the upper the potential sign of future analytic outputs, and the earlier you’ll have a viable analytic in place working for you. After deployment, the extra shortly and confidently you may disposition analytic outputs, the quicker and higher the triage and the earlier acceptable responses could be pursued. In different phrases, the velocity of gathering enough context immediately impacts your imply time to detect and imply time to reply. Inversely, boundaries to shortly gathering enough context are boundaries to tuning/triage; are boundaries to viable, efficient, and scalable deployment of proactive/behavioral safety analytics; and are boundaries to early warning and danger discount. Consequently, something you are able to do to enhance the supply and/or velocity of gathering related context is a worthwhile effort in your detection program. These issues embody:
- constructing and sustaining related baselines
- constructing and sustaining a correlation layer
- investing in automation by getting extra contextual data—particularly inside entities and environmental context—that’s codified, made programmatically accessible, and built-in
- constructing relationships and tightening up safety reporting/suggestions loops with related stakeholders—a holistic individuals, course of, and expertise effort; contemplate one thing akin to these automated safety bot use circumstances
- constructing relationships with safety engineering and admins so they’re extra prepared to help in tweaking the sign
- supporting knowledge engineering, infrastructure, and processing for automated enrichments, baseline checks, and upkeep
- tweaking configurations for detection, e.g., deception engineering, this instance with ticket occasions, and so forth.
- tweaking enterprise processes for detection, e.g., hooks into sure accepted change requests, admins all the time do that little additional particular factor to let you already know it’s actually them, and so forth.
Abstract
Analytics focusing on adversary behaviors will typically sufficient require tuning in your surroundings because of the identification of each benign and malicious cases of that habits. Simply because a habits could also be frequent in your surroundings doesn’t essentially imply it’s a nasty detection alternative or not well worth the analytic effort. One of many major methods of coping with such analytic outputs, with out sacrificing protection, is by utilizing context (typically greater than is contained within the uncooked occasions) and versatile filtering to tune out benign positives. I advocate for detection engineers to carry out most of this work, basically conducting an information examine and a few pre-operational triage of their very own analytic outcomes. This work usually entails a cycle of evaluating analytic outcomes to distill patterns, discerning benign habits, introducing context as needed, and eventually filtering out benign occasions. We used a pair primary examples to indicate how that cycle may play out.
If the fast context is inadequate to distill patterns and/or discern benign habits, detection engineers can nearly all the time complement it with automated enrichments and/or baselines. Automated enrichments are extra frequent for exterior, Web-accessible property and could also be more durable to come back by for inside entities, however baselines can sometimes be constructed utilizing the info you’re already gathering. Plus, historic/entity-based context is a number of the most helpful context to have.
In looking for to provide viable, high quality analytics, detection engineers ought to exhaust, or at the very least attempt, these choices earlier than dismissing an analytic effort or sacrificing its protection. It’s additional work, however doing this work not solely improves pre-operational tuning however pays dividends on post-operational deployment as analysts triage alerts/leads utilizing the additional context and well-documented analysis. Analysts are then in a greater place to establish and escalate findings but additionally to offer tuning suggestions. Apart from, tuning is a steady course of and a two-pronged effort between detection engineers and analysts, if solely as a result of threats and environments usually are not static.
The opposite major means of coping with such analytic outputs, once more with out sacrificing protection, is by incorporating a correlation layer into your detection pipeline. Correlation can also be extra work as a result of it provides one other layer of processing, and it’s a must to rating analytic outputs. Scoring could be difficult as a result of there are numerous issues to contemplate, resembling how dangerous every analytic output is within the grand scheme of issues, if/how you must weight and/or increase scores to account for numerous circumstances (e.g., asset criticality, time), how you must normalize scores, whether or not you must calculate scores throughout a number of entities and which one takes priority, and so forth. Nonetheless, the advantages of correlation make it a worthwhile effort and an amazing possibility to assist prioritize throughout all analytic outputs. Additionally, it successfully diminishes the issue of noisier analytics since not each analytic output is supposed to be triaged.
In case you need assistance doing any of these items, or wish to focus on your detection engineering journey, please contact us.

{kind=link}
{kind=link}