
Retrieval-Augmented-Technology (RAG) has shortly emerged as a robust solution to incorporate proprietary, real-time information into Giant Language Mannequin (LLM) functions. At this time we’re excited to launch a collection of RAG instruments to assist Databricks customers construct high-quality, manufacturing LLM apps utilizing their enterprise information.
LLMs provided a significant breakthrough within the skill to quickly prototype new functions. However after working with hundreds of enterprises constructing RAG functions, we’ve discovered that their largest problem is getting these functions to manufacturing high quality. To fulfill the usual of high quality required for customer-facing functions, AI output have to be correct, present, conscious of your enterprise context, and secure.
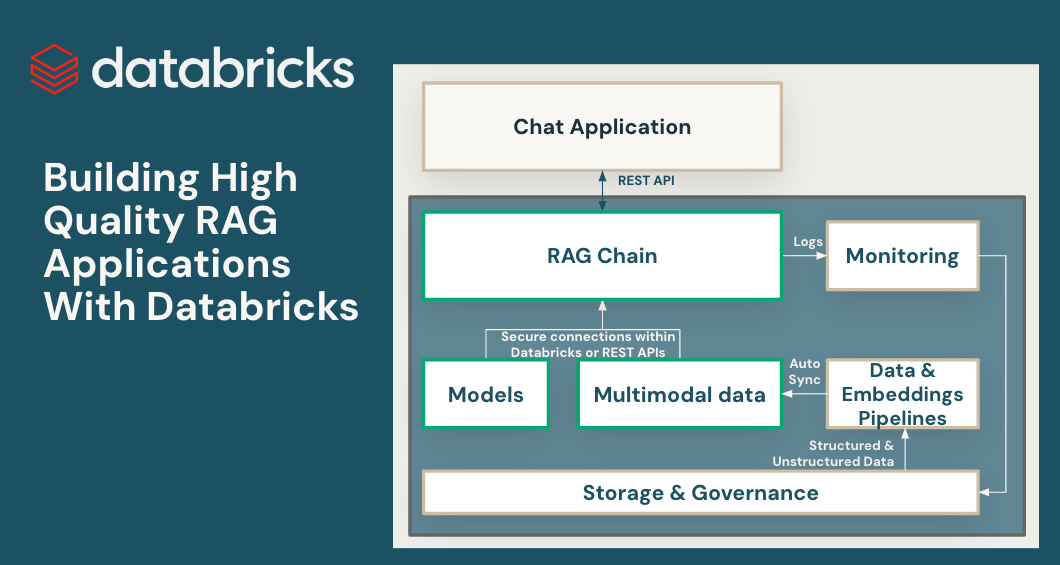
To realize top quality with RAG functions, builders want wealthy instruments for understanding the standard of their information and mannequin outputs, together with an underlying platform that lets them mix and optimize all points of the RAG course of. RAG includes many elements equivalent to information preparation, retrieval fashions, language fashions (both SaaS or open supply), rating and post-processing pipelines, immediate engineering, and coaching fashions on customized enterprise information. Databricks has all the time targeted on combining your information with innovative ML methods. With at present’s launch, we lengthen that philosophy to let clients leverage their information in creating top quality AI functions.
At this time’s launch contains Public Preview of:
These options are designed to handle the three main challenges we’ve seen in constructing manufacturing RAG functions:
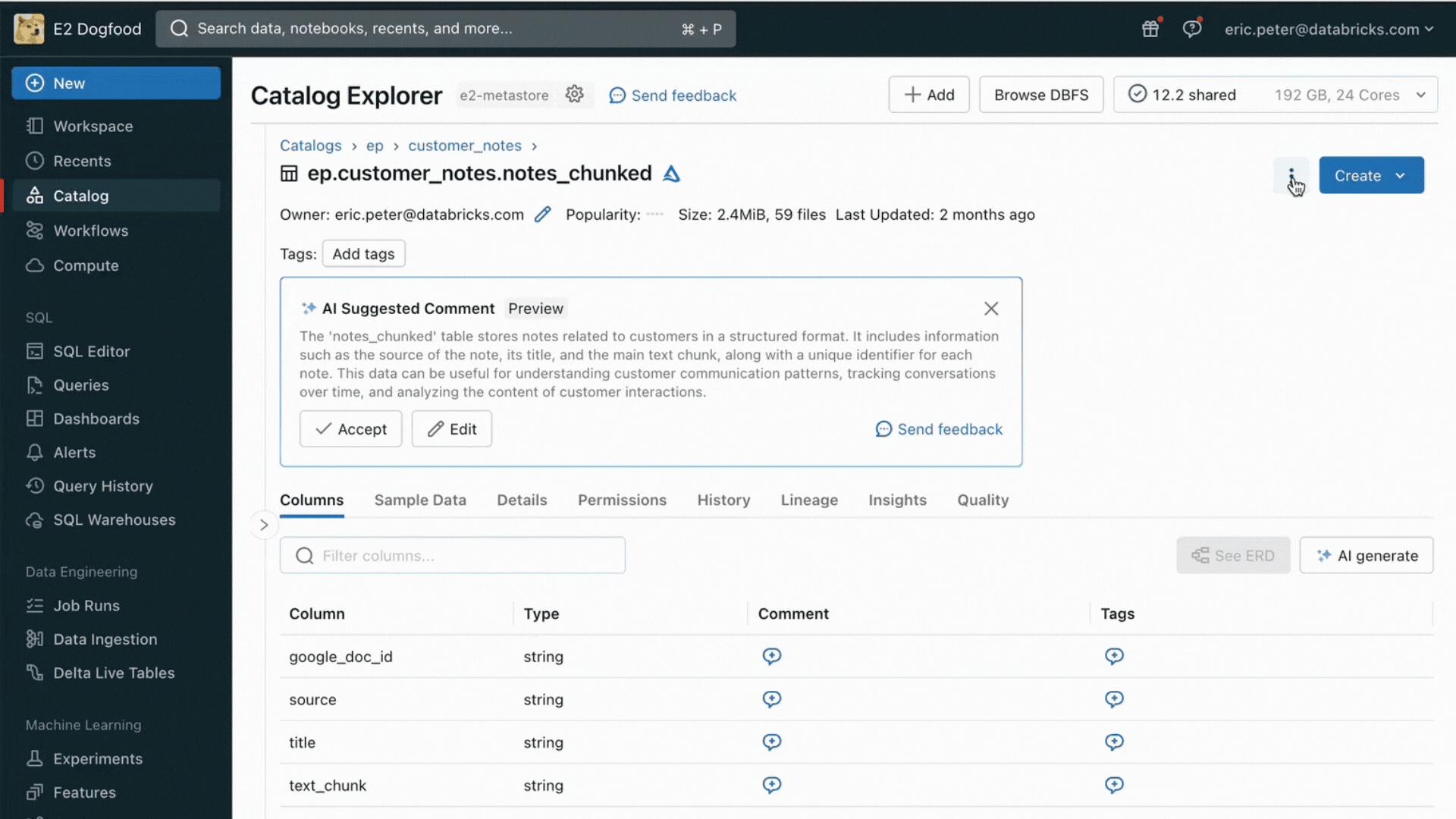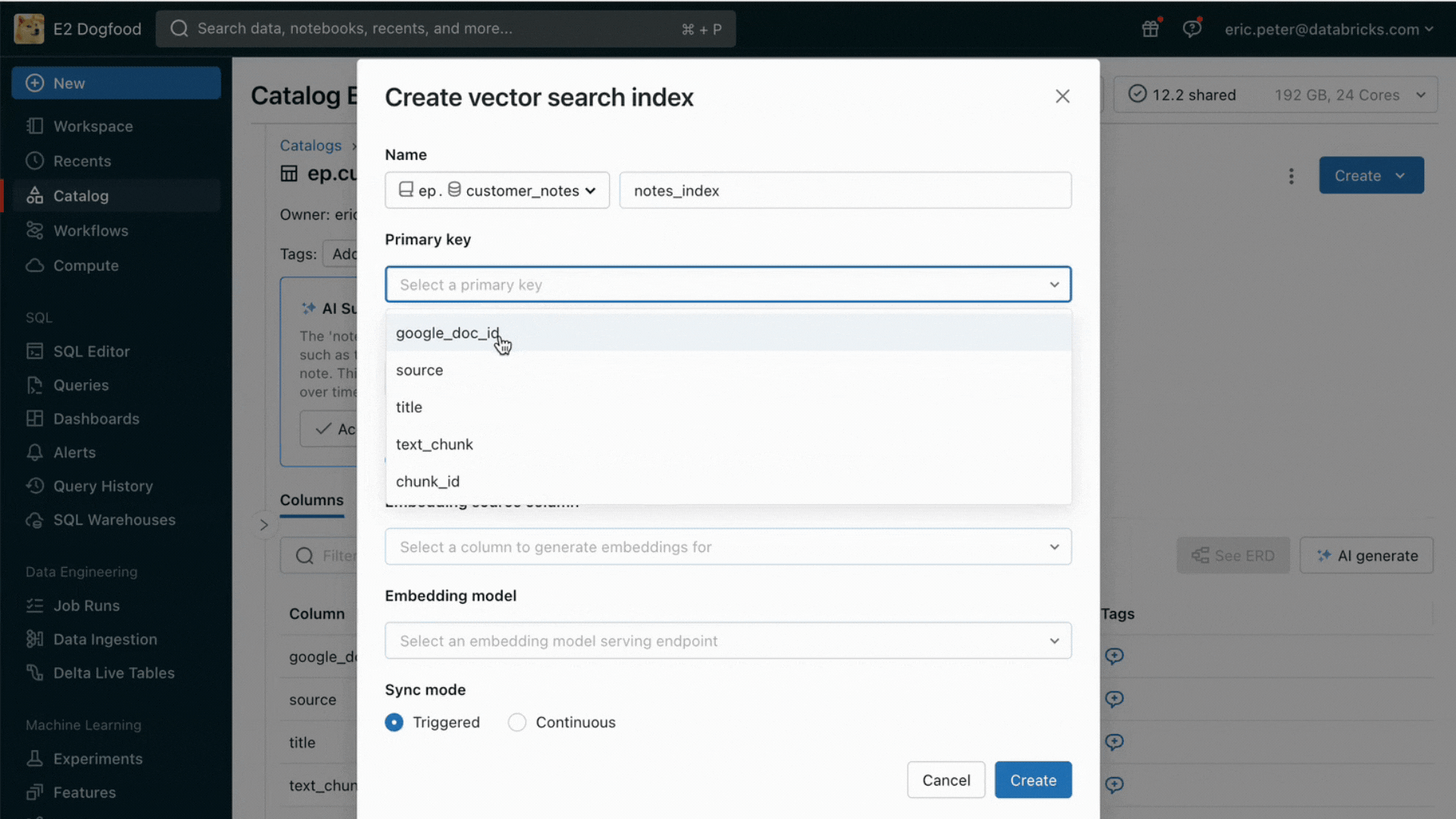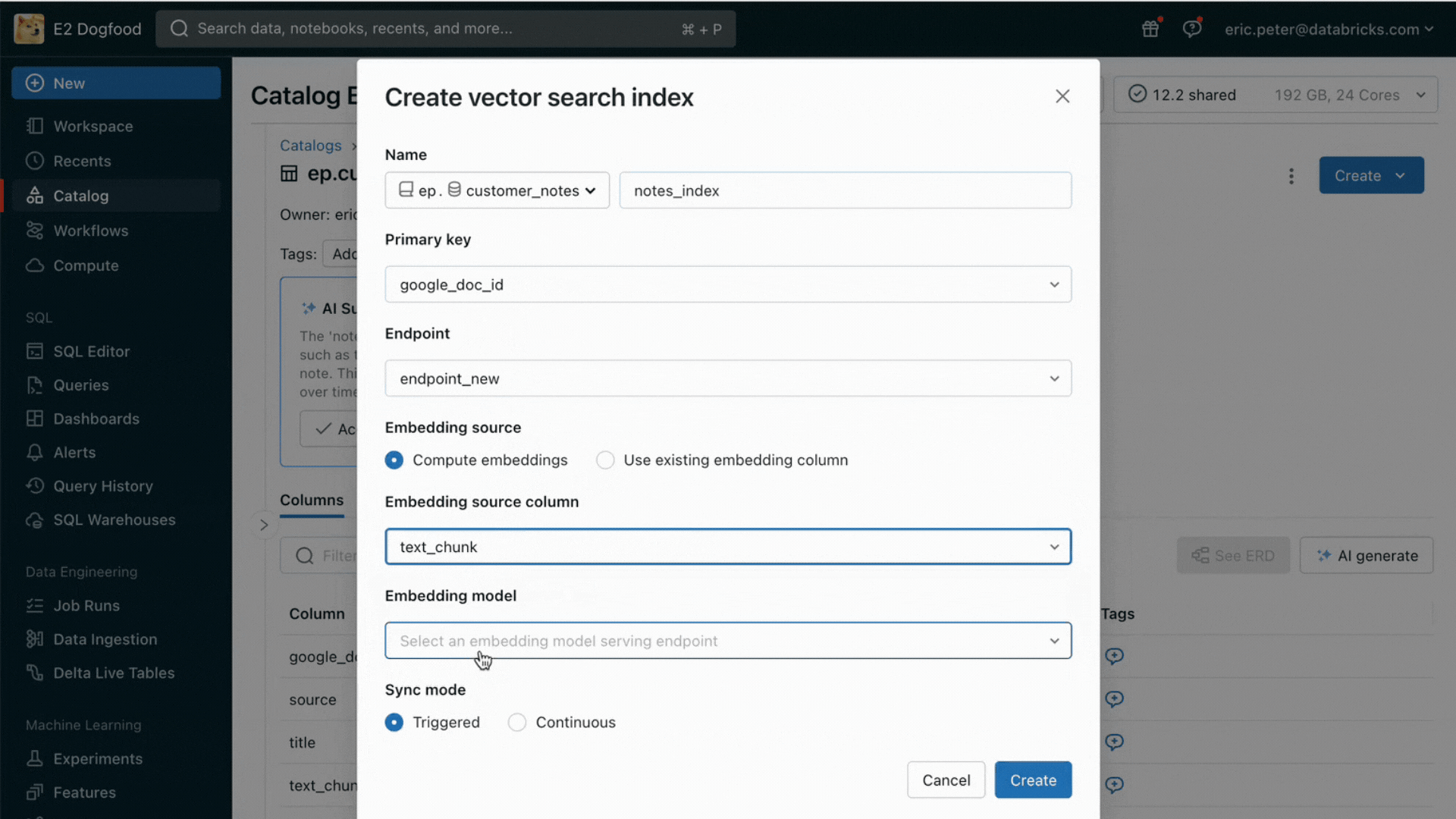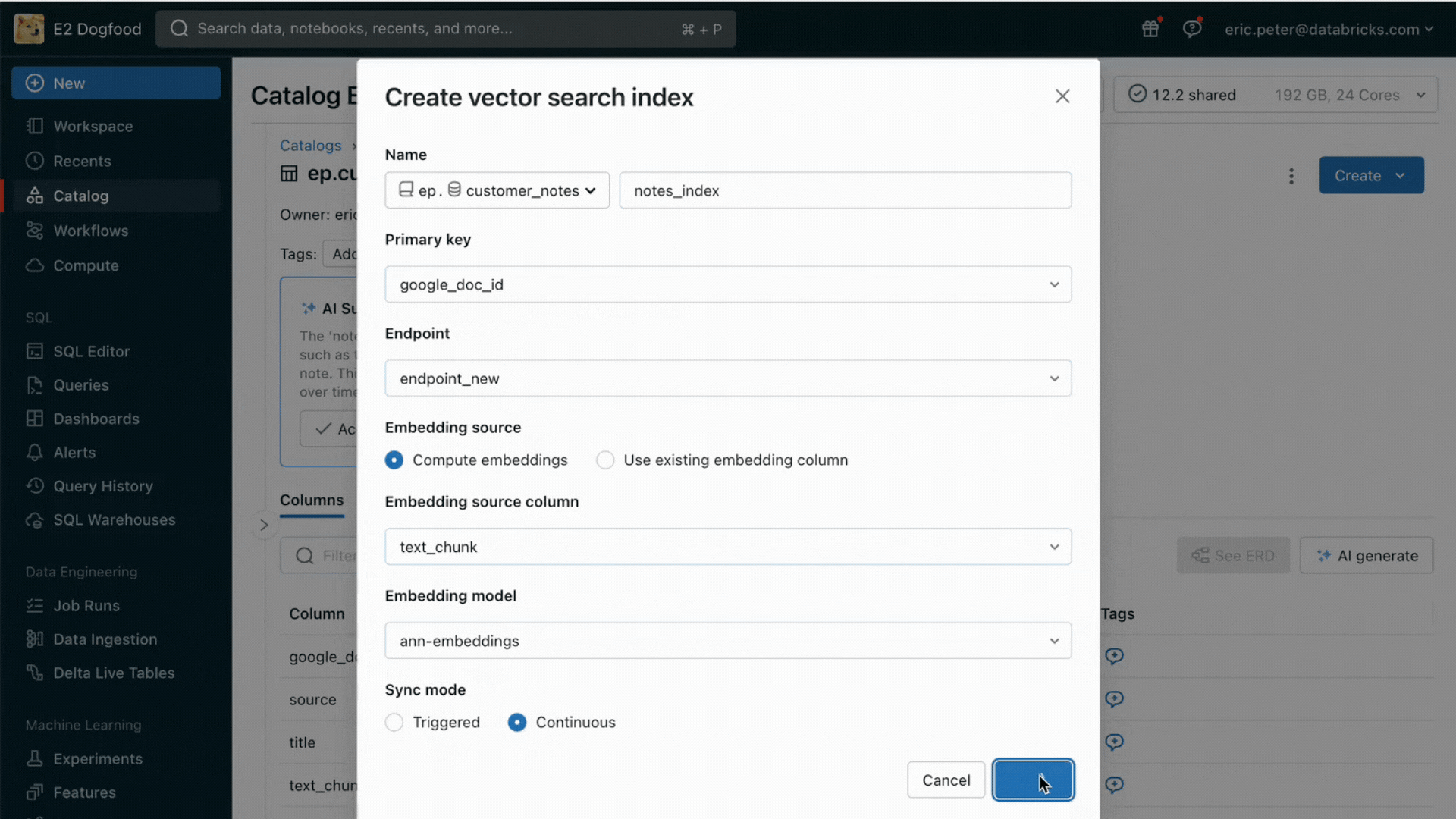
Problem #1 – Serving Actual-Time Information For Your RAG App
RAG functions mix your newest structured and unstructured information to supply the best high quality and most personalised responses. However sustaining on-line information serving infrastructure may be very troublesome, and firms have traditionally needed to sew collectively a number of programs and preserve complicated information pipelines to load information from central information lakes into bespoke serving layers. Securing vital datasets can be very troublesome when copies are striped throughout completely different infrastructure stacks.
With this launch, Databricks natively helps serving and indexing your information for on-line retrieval. For unstructured information (textual content, photos, and video), Vector Search will mechanically index and serve information from Delta tables, making them accessible by way of semantic similarity seek for RAG functions. Underneath the hood, Vector Search manages failures, handles retries, and optimizes batch sizes to offer you the very best efficiency, throughput, and value. For structured information, Characteristic and Perform Serving gives millisecond-scale queries of contextual information equivalent to consumer or account information, that enterprises usually need to inject into prompts so as to customise them based mostly on consumer data.
Unity Catalog mechanically tracks lineage between the offline and on-line copies of served datasets, making debugging information high quality points a lot simpler. It additionally persistently enforces entry controls settings between on-line and offline datasets, which means enterprises can higher audit and management who’s seeing delicate proprietary data.
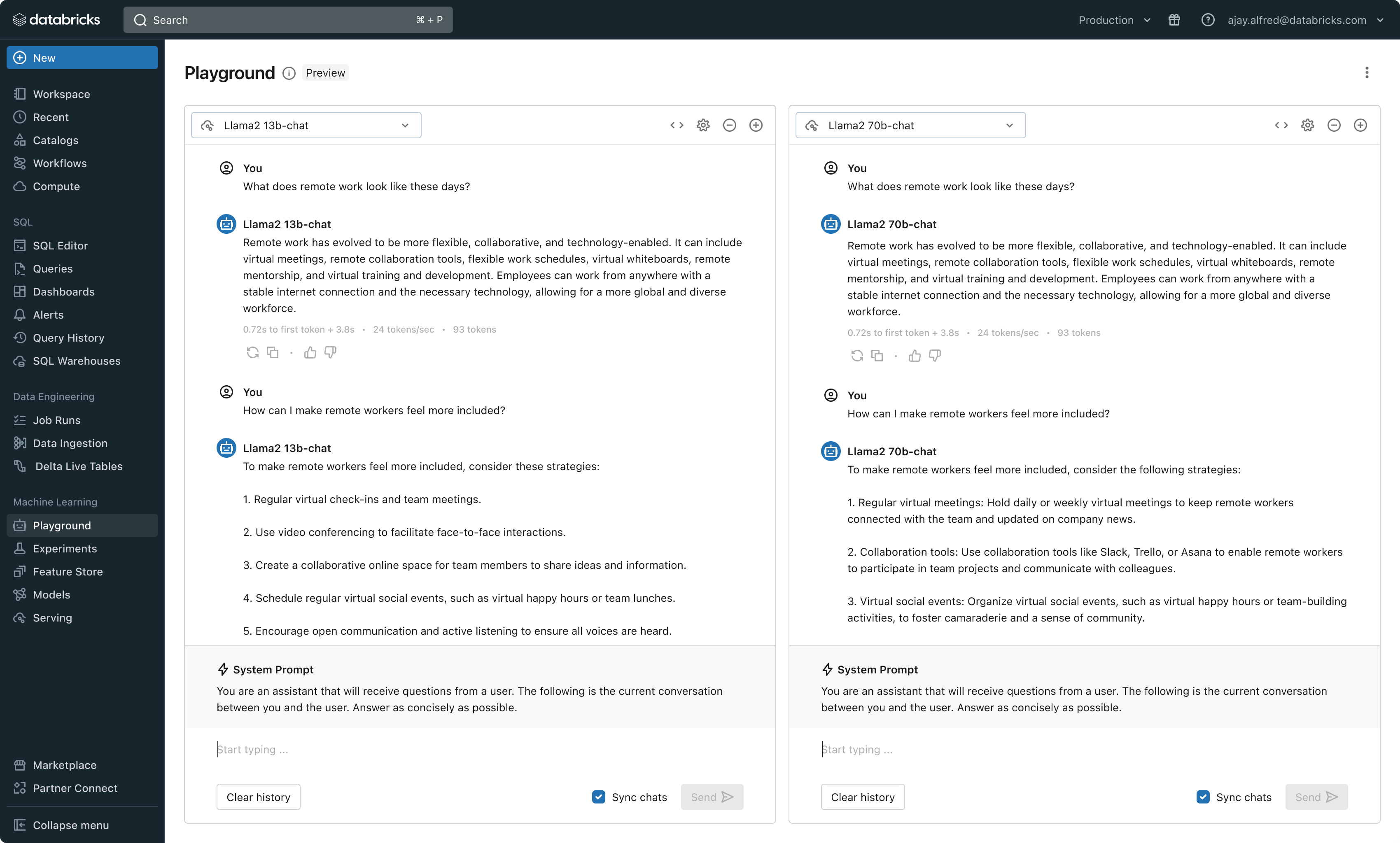
Problem #2 – Evaluating, Tuning, and Serving Basis Fashions
A serious determinant of high quality in a RAG utility is the selection of base LLM mannequin. Evaluating fashions may be troublesome as a result of fashions fluctuate throughout a number of dimensions, equivalent to reasoning skill, propensity to hallucinate, context window measurement, and serving value. Some fashions may also be wonderful tuned to particular functions, which may additional enhance efficiency and probably cut back prices. With new fashions being launched virtually weekly, evaluating base mannequin permutations to search out your best option for a selected utility may be extraordinarily burdensome. Additional complicating issues, mannequin suppliers usually have disparate API’s making speedy comparability or future-proofing of RAG functions very troublesome.
With this launch, Databricks now provides a unified atmosphere for LLM improvement and analysis–offering a constant set of instruments throughout mannequin households on a cloud-agnostic platform. Databricks customers can entry main fashions from Azure OpenAI Service, AWS Bedrock and Anthropic, open supply fashions equivalent to Llama 2 and MPT, or clients’ fine-tuned, totally customized fashions. The brand new interactive AI Playground permits straightforward chat with these fashions whereas our built-in toolchain with MLflow allows wealthy comparisons by monitoring key metrics like toxicity, latency, and token depend. Facet-by-side mannequin comparability within the Playground or MLflow permits clients to establish the very best mannequin candidate for every use case, even supporting analysis of the retriever part.
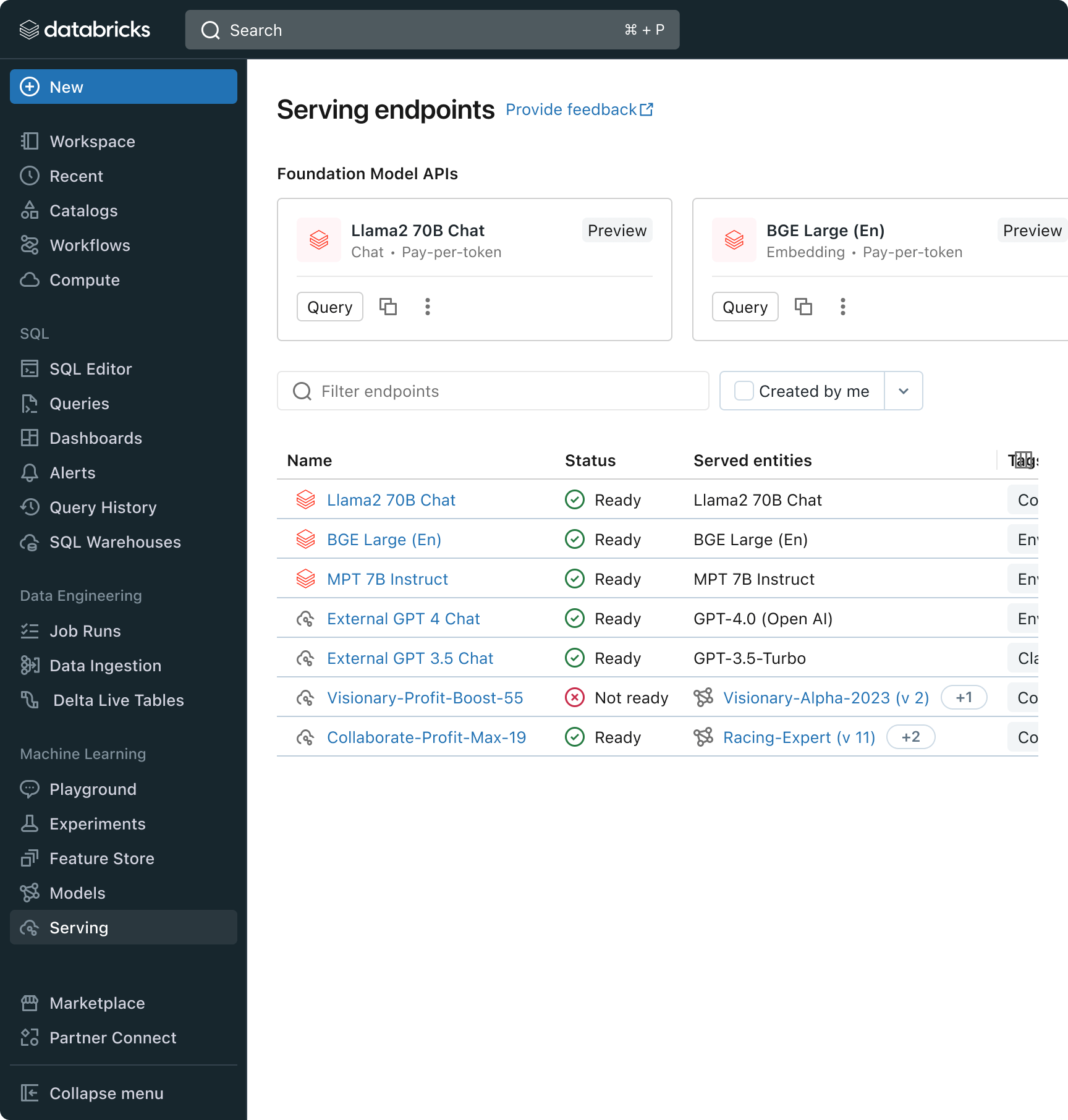
Databricks can be releasing Basis Mannequin API’s, a completely managed set of LLM fashions together with the favored Llama and MPT mannequin households. Basis Mannequin API’s can be utilized on a pay-per-token foundation, drastically decreasing value and growing flexibility. As a result of Basis Mannequin API’s are served from inside Databricks infrastructure, delicate information doesn’t must transit to 3rd social gathering companies.
In apply, attaining top quality usually means mixing-and-matching base fashions in accordance with the particular necessities of every utility. Databricks’ Mannequin Serving structure now gives a unified interface to deploy, govern, and question any sort of LLM, be it a completely customized mannequin, a Databricks-managed mannequin, or a 3rd social gathering basis mannequin. This flexibility lets clients select the fitting mannequin for the fitting job and be future proof within the face of future advances within the set of obtainable fashions.
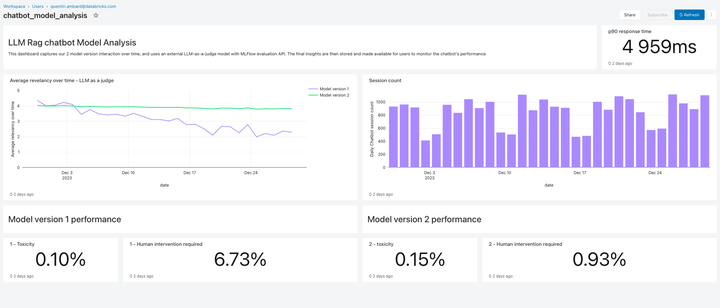
Problem #3 – Making certain High quality and Security In Manufacturing
As soon as an LLM utility is deployed, it may be troublesome to understand how nicely it’s working. Not like conventional software program, language-based functions don’t have a single appropriate reply or apparent “error” situations. This implies understanding high quality (how nicely is that this working?) or what constitutes anomalous, unsafe, or poisonous output (is that this factor secure?) is nontrivial. At Databricks, we’ve seen many purchasers hesitate to roll out RAG functions as a result of they’re uncertain whether or not noticed high quality in a small inner prototype will translate to their consumer base at scale.
Included on this launch, Lakehouse Monitoring gives a completely managed high quality monitoring resolution for RAG functions. Lakehouse Monitoring can mechanically scan utility outputs for poisonous, hallucinated, or in any other case unsafe content material. This information can then feed dashboards, alerts, or different downstream information pipelines for subsequent actioning. Since monitoring is built-in with the lineage of datasets and fashions, builders can shortly diagnose errors associated to e.g. stale information pipelines or fashions which have unexpectedly modified habits.
Monitoring will not be solely about security but in addition high quality. Lakehouse Monitoring can incorporate utility degree ideas like “thumbs up/thumbs down” type consumer suggestions, and even derived metrics equivalent to “consumer settle for price” (how usually an end-user accepts AI generated suggestions). In our expertise, measuring end-to-end consumer metrics considerably bolsters the arrogance of enterprises that RAG functions are working nicely within the wild. Monitoring pipelines are additionally totally managed by Databricks, so builders can spend time on their functions somewhat than managing observability infrastructure.
The monitoring options on this launch are just the start. Keep tuned for far more!
Subsequent Steps
We now have in-depth blogs all through this week and subsequent that undergo intimately on implementation finest practices. So come again to our Databricks weblog on daily basis, discover our merchandise by way of the brand new RAG demo, watch the Databricks Generative AI Webinar on-demand, and take a look at a fast video demo of the RAG suite of instruments in motion:

{kind=link}