

It’s evident from the quantity of reports protection, articles, blogs, and water cooler tales that synthetic intelligence (AI) and machine studying (ML) are altering our society in elementary methods—and that the {industry} is evolving rapidly to attempt to sustain with the explosive development.
Sadly, the community that we’ve used up to now for high-performance computing (HPC) can’t scale to satisfy the calls for of AI/ML. As an {industry}, we should evolve our considering and construct a scalable and sustainable community for AI/ML.
Right now, the {industry} is fragmented between AI/ML networks constructed round 4 distinctive architectures: InfiniBand, Ethernet, telemetry assisted Ethernet, and absolutely scheduled materials.
Every expertise has its execs and cons, and numerous tier 1 net scalers view the trade-offs in a different way. For this reason we see the {industry} transferring in lots of instructions concurrently to satisfy the speedy large-scale buildouts occurring now.
This actuality is on the coronary heart of the worth proposition of Cisco Silicon One.
Prospects can deploy Cisco Silicon One to energy their AI/ML networks and configure the community to make use of normal Ethernet, telemetry assisted Ethernet, or absolutely scheduled materials. As workloads evolve, they’ll proceed to evolve their considering with Cisco Silicon One’s programmable structure.
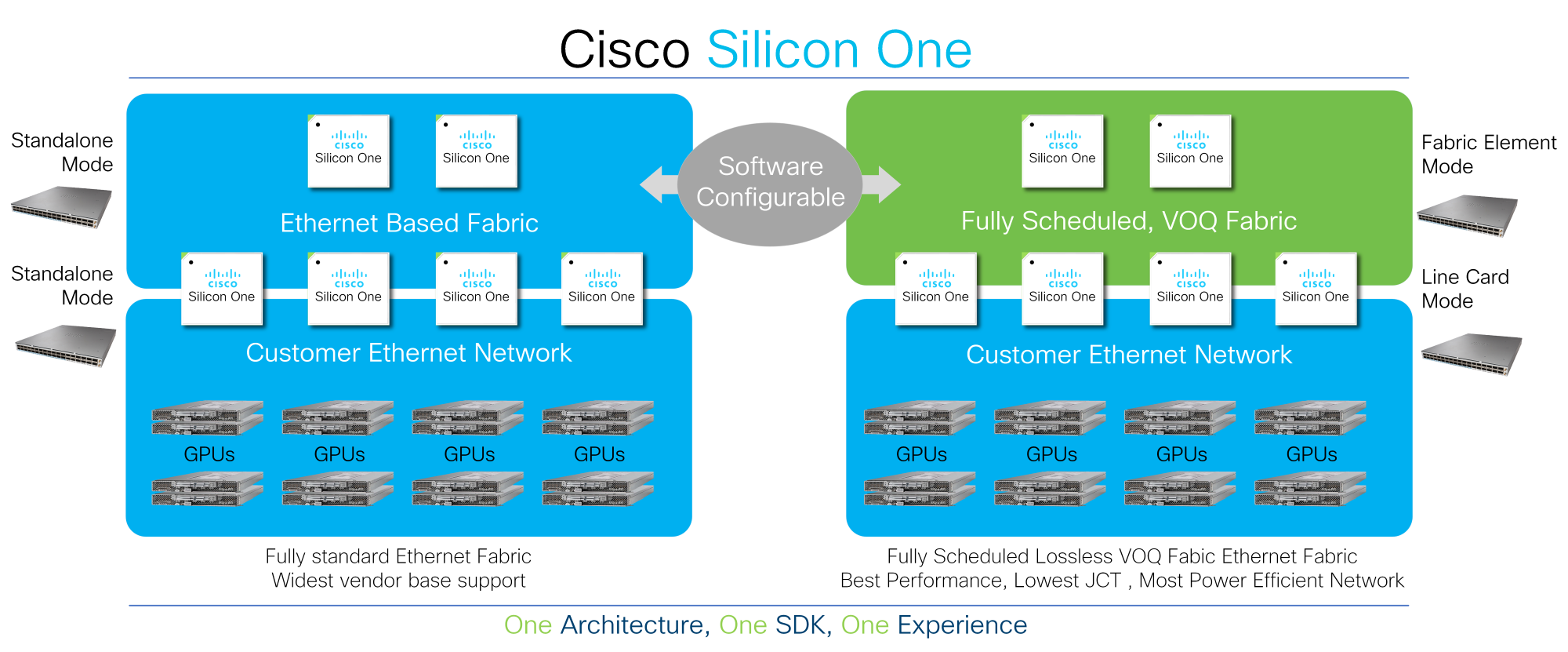
All different silicon architectures available on the market lock organizations right into a slender deployment mannequin, forcing clients to make early shopping for time choices and limiting their flexibility to evolve. Cisco Silicon One, nevertheless, provides clients the flexibleness to program their community into numerous operational modes and gives best-of-breed traits in every mode. As a result of Cisco Silicon One can allow a number of architectures, clients can concentrate on the fact of the info after which make data-driven choices in keeping with their very own standards.

To assist perceive the relative deserves of every of those applied sciences, it’s necessary to grasp the basics of AI/ML. Like many buzzwords, AI/ML is an oversimplification of many distinctive applied sciences, use circumstances, visitors patterns, and necessities. To simplify the dialogue, we’ll concentrate on two elements: coaching clusters and inference clusters.
Coaching clusters are designed to create a mannequin utilizing recognized knowledge. These clusters practice the mannequin. That is an extremely complicated iterative algorithm that’s run throughout a large variety of GPUs and might run for a lot of months to generate a brand new mannequin.
Inference clusters, in the meantime, take a educated mannequin to investigate unknown knowledge and infer the reply. Merely put, these clusters infer what the unknown knowledge is with an already educated mannequin. Inference clusters are a lot smaller computational fashions. Once we work together with OpenAI’s ChatGPT, or Google Bard, we’re interacting with the inference fashions. These fashions are a results of a really important coaching of the mannequin with billions and even trillions of parameters over an extended time frame.
On this weblog, we’ll concentrate on coaching clusters and analyze how the efficiency of Ethernet, telemetry assisted Ethernet, and absolutely scheduled materials behave. I shared additional particulars about this matter in my OCP International Summit, October 2022 presentation.
AI/ML coaching networks are constructed as self-contained, large back-end networks and have considerably totally different visitors patterns than conventional front-end networks. These back-end networks are used to hold specialised visitors between specialised endpoints. Prior to now, they had been used for storage interconnect, nevertheless, with the arrival of distant direct reminiscence entry (RDMA) and RDMA over Converged Ethernet (RoCE), a good portion of storage networks are actually constructed over generic Ethernet.
Right now, these back-end networks are getting used for HPC and big AI/ML coaching clusters. As we noticed with storage, we’re witnessing a migration away from legacy protocols.
The AI/ML coaching clusters have distinctive visitors patterns in comparison with conventional front-end networks. The GPUs can absolutely saturate high-bandwidth hyperlinks as they ship the outcomes of their computations to their friends in an information switch referred to as the all-to-all collective. On the finish of this switch, a barrier operation ensures that each one GPUs are updated. This creates a synchronization occasion within the community that causes GPUs to be idled, ready for the slowest path by the community to finish. The job completion time (JCT) measures the efficiency of the community to make sure all paths are performing nicely.

This visitors is non-blocking and ends in synchronous, high-bandwidth, long-lived flows. It’s vastly totally different from the info patterns within the front-end community, that are primarily constructed out of many asynchronous, small-bandwidth, and short-lived flows, with some bigger asynchronous long-lived flows for storage. These variations together with the significance of the JCT imply community efficiency is vital.
To investigate how these networks carry out, we created a mannequin of a small coaching cluster with 256 GPUs, eight high of rack (TOR) switches, and 4 backbone switches. We then used an all-to-all collective to switch a 64 MB collective dimension and differ the variety of simultaneous jobs operating on the community, in addition to the quantity of community within the speedup.
The outcomes of the examine are dramatic.
Not like HPC, which was designed for a single job, giant AI/ML coaching clusters are designed to run a number of simultaneous jobs, equally to what occurs in net scale knowledge facilities immediately. Because the variety of jobs will increase, the consequences of the load balancing scheme used within the community turn into extra obvious. With 16 jobs operating throughout the 256 GPUs, a completely scheduled material ends in a 1.9x faster JCT.

Learning the info one other manner, if we monitor the quantity of precedence stream management (PFC) despatched from the community to the GPU, we see that 5% of the GPUs decelerate the remaining 95% of the GPUs. As compared, a completely scheduled material gives absolutely non-blocking efficiency, and the community by no means pauses the GPU.

Which means for a similar community, you’ll be able to join twice as many GPUs for a similar dimension community with absolutely scheduled material. The purpose of telemetry assisted Ethernet is to enhance the efficiency of normal Ethernet by signaling congestion and bettering load balancing choices.
As I discussed earlier, the relative deserves of varied applied sciences differ by every buyer and are possible not fixed over time. I consider Ethernet, or telemetry assisted Ethernet, though decrease efficiency than absolutely scheduled materials, are an extremely beneficial expertise and shall be deployed extensively in AI/ML networks.
So why would clients select one expertise over the opposite?
Prospects who need to benefit from the heavy funding, open requirements, and favorable cost-bandwidth dynamics of Ethernet ought to deploy Ethernet for AI/ML networks. They’ll enhance the efficiency by investing in telemetry and minimizing community load by cautious placement of AI jobs on the infrastructure.
Prospects who need to benefit from the full non-blocking efficiency of an ingress digital output queue (VOQ), absolutely scheduled, spray and re-order material, leading to a powerful 1.9x higher job completion time, ought to deploy absolutely scheduled materials for AI/ML networks. Absolutely scheduled materials are additionally nice for purchasers who need to save price and energy by eradicating community parts, but nonetheless obtain the identical efficiency as Ethernet, with 2x extra compute for a similar community.
Cisco Silicon One is uniquely positioned to supply an answer for both of those clients with a converged structure and industry-leading efficiency.

Be taught extra:
Learn: AI/ML white paper
Go to: Cisco Silicon One
Share:

{kind=link}