
Introduction
After a yr of embracing ChatGPT, the AI panorama welcomes Google’s extremely anticipated Gemini—a formidable competitor. The Gemini collection contains three highly effective language fashions: Gemini Professional, Gemini Nano, and the top-tier Gemini Extremely, which has demonstrated distinctive efficiency throughout varied benchmarks, although it’s but to be unleashed into the wild. Presently, Gemini Professional fashions provide efficiency akin to gpt-3.5-turbo, offering an accessible and cost-effective resolution for pure language understanding and imaginative and prescient duties. These fashions will be utilized to various real-world eventualities, together with video narration, visible question-answering (QA), RAG (Retrieval-Augmented Era), and extra. On this article, we’ll look into the capabilities of Gemini Professional fashions and information you thru constructing a multi-modal QA bot utilizing Gemini and Gradio.

Studying Goals
- Discover Gemini fashions.
- Authenticate VertexAI to entry Gemini fashions.
- Discover Gemini API and GCP Python SDK.
- Find out about Gradio and its Parts.
- Construct a practical multi-modal QA bot utilizing Gemini and Gradio.
This text was printed as part of the Knowledge Science Blogathon.
Earlier than we begin constructing our QA Bot utilizing Gemini and Gradio, let’s perceive the options of Gemini.
What’s Google Gemini?
Much like GPT, the Gemini household of fashions makes use of transformer decoders optimized for scale coaching and inferencing on Google’s Tensor Processing Items. These fashions endure joint coaching throughout varied information modalities, together with textual content, picture, audio, and video, to develop Massive Language Fashions (LLMs) with versatile capabilities and a complete understanding of a number of modes. The Gemini contains three mannequin lessons—Gemini Professional, Nano, and Extremely—every fine-tuned for particular use instances.
- Gemini Extremely: Probably the most performant from Google has proven state-of-the-art efficiency throughout duties like math, reasoning, multi-modal capabilities, and many others. As per the technical report from Google, Gemini Extremely has carried out higher than GPT-4 on many benchmarks.
- Gemini Professional: The professional mannequin is optimized for efficiency, scalability, and low-latency inferencing. It’s a succesful mannequin rivaling gpt-3.5-turbo with multi-modal capabilities.
- Gemini Nano: Nano has two smaller LLMs with 1.8B and 3B parameters. It’s educated by distilling from bigger Gemini fashions optimized for operating on low and high-memory gadgets.
You possibly can entry the fashions via GCP Vertex AI or Google AI Studio. Whereas Vertex AI is appropriate for manufacturing purposes, it mandates a GCP account. Nevertheless, with AI Studio, builders can create an API key to entry Gemini fashions and not using a GCP account. We are going to discover each strategies on this article however implement the VertexAI methodology. You possibly can implement the latter with just a few tweaks within the code.
Now, let’s start with constructing QA bot utilizing Gemini!
Accessing Gemini utilizing VertexAI
The Gemini fashions will be accessed from VertexAI on GCP. So, to start out constructing with these fashions, we have to configure Google Cloud CLI and authenticate with Vertex AI. First, set up the GCP CLI and initialize with gcloud init.
Create an authentication credential to your account with the command gcloud auth application-default login. This can open a portal to signal right into a Google and comply with the directions. As soon as carried out, you possibly can work with Google Cloud from an area setting.
Now, create a digital setting and set up the Python library. That is the Python SDK for GCP for accessing Gemini fashions.
pip set up --upgrade google-cloud-aiplatformNow that the environment is prepared. Let’s perceive the Gemini API.
Request Physique to Gemini API
Google has launched solely the Professional and Professional imaginative and prescient fashions for public use. The Gemini Professional is a text-only LLM appropriate for textual content technology use instances, like summarizing, Paraphrasing, Translation, and many others. It has a context dimension of 32k. Nevertheless, the imaginative and prescient mannequin can course of pictures and movies. It has a context dimension of 16k. We will ship 16 picture recordsdata or a video at a time.
Beneath is a request physique to Gemini API:
{
"contents": [
{
"role": string,
"parts": [
{
// Union field data can be only one of the following:
"text": string,
"inlineData": {
"mimeType": string,
"data": string
},
"fileData": {
"mimeType": string,
"fileUri": string
},
// End of list of possible types for union field data.
"videoMetadata": {
"startOffset": {
"seconds": integer,
"nanos": integer
},
"endOffset": {
"seconds": integer,
"nanos": integer
}
}
}
]
}
],
"instruments": [
{
"functionDeclarations": [
{
"name": string,
"description": string,
"parameters": {
object (OpenAPI Object Schema)
}
}
]
}
],
"safetySettings": [
{
"category": enum (HarmCategory),
"threshold": enum (HarmBlockThreshold)
}
],
"generationConfig": {
"temperature": quantity,
"topP": quantity,
"topK": quantity,
"candidateCount": integer,
"maxOutputTokens": integer,
"stopSequences": [
string
]
}
}Within the above JSON schema, we’ve roles(consumer, system, or perform), the textual content, file information for pictures or movies, and technology config for extra mannequin parameters and security settings for altering the sensitivity tolerance of the mannequin.
That is the JSON response from the API.
{
"candidates": [
{
"content": {
"parts": [
{
"text": string
}
]
},
"finishReason": enum (FinishReason),
"safetyRatings": [
{
"category": enum (HarmCategory),
"probability": enum (HarmProbability),
"blocked": boolean
}
],
"citationMetadata": {
"citations": [
{
"startIndex": integer,
"endIndex": integer,
"uri": string,
"title": string,
"license": string,
"publicationDate": {
"year": integer,
"month": integer,
"day": integer
}
}
]
}
}
],
"usageMetadata": {
"promptTokenCount": integer,
"candidatesTokenCount": integer,
"totalTokenCount": integer
}
}Because the response, we get a JSON with the solutions, citations, security rankings, and utilization information. So, these are the JSON schemas of requests and responses to Gemini API. For extra data, seek advice from this official documentation for Gemini.
You possibly can instantly talk with API with JSON. Generally, it’s higher to speak with API endpoints instantly reasonably than relying on SDKs, because the latter usually endure breaking adjustments.
For simplicity, we’ll use the Python SDK we put in earlier to speak with the fashions.
from vertexai.preview.generative_models import GenerativeModel, Picture, Half, GenerationConfig
mannequin = GenerativeModel("gemini-pro-vision", generation_config= GenerationConfig())
response = mannequin.generate_content(
[
"Explain this image step-by-step, using bullet marks in detail",
Part.from_image(Image.load_from_file("whisper_arch.png"))
],
)
print(response)This can output a Era object.
candidates {
content material {
position: "mannequin"
elements {
textual content: " * response
}
finish_reason: STOP
safety_ratings {
class: HARM_CATEGORY_HARASSMENT
likelihood: NEGLIGIBLE
}
safety_ratings {
class: HARM_CATEGORY_HATE_SPEECH
likelihood: NEGLIGIBLE
}
safety_ratings {
class: HARM_CATEGORY_SEXUALLY_EXPLICIT
likelihood: NEGLIGIBLE
}
safety_ratings {
class: HARM_CATEGORY_DANGEROUS_CONTENT
likelihood: NEGLIGIBLE
}
}
usage_metadata {
prompt_token_count: 271
candidates_token_count: 125
total_token_count: 396
}We will retrieve the texts with the next code.
print(response.candidates[0].content material.elements[0].textual content)Output
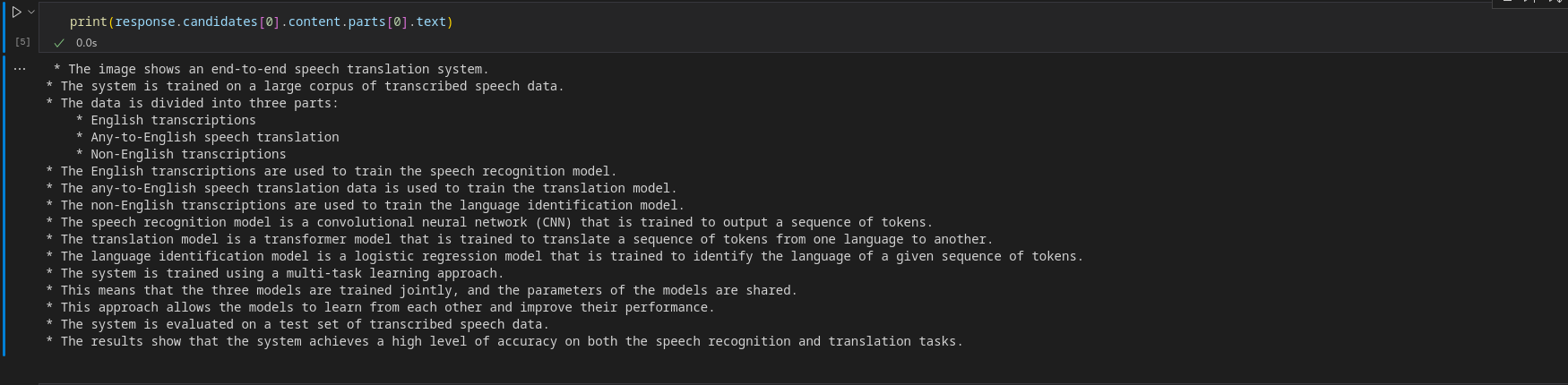
To obtain a streaming object, flip streaming to True.
response = mannequin.generate_content(
[
"Explain this image step-by-step, using bullet marks in detail?",
Part.from_image(Image.load_from_file("whisper_arch.png"))
], stream=True
)To retrieve chunks, iterate over the StreamingGeneration object.
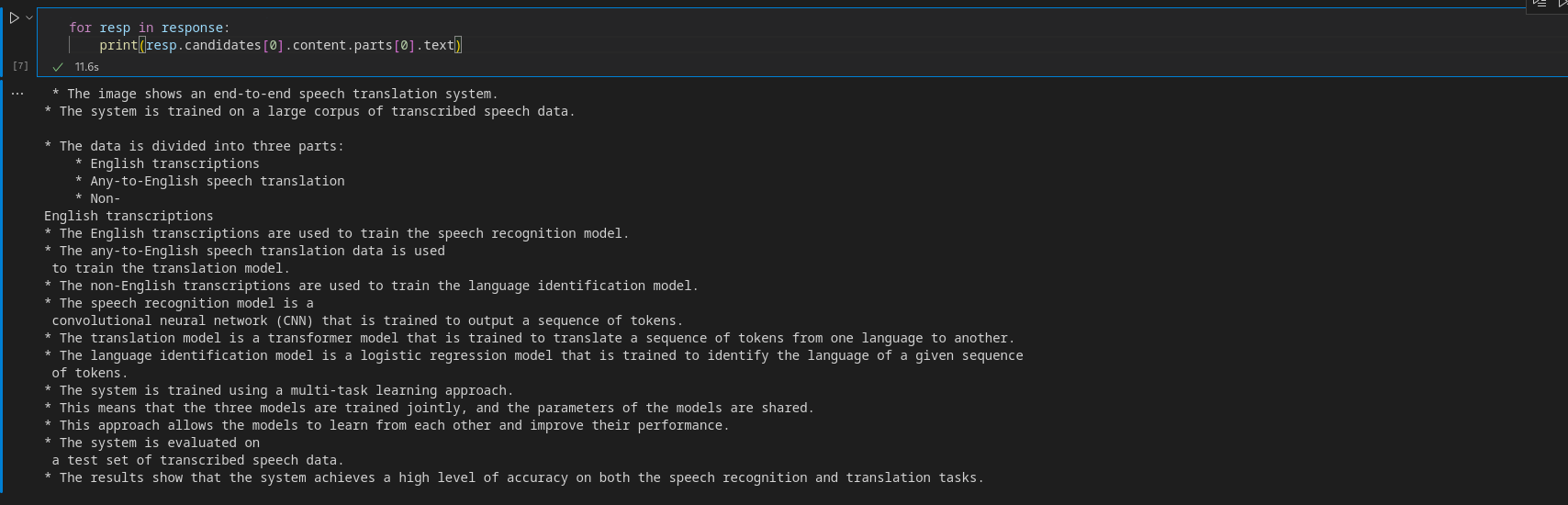
for resp in response:
print(resp.candidates[0].content material.elements[0].textual content)Output
Earlier than constructing the app, let’s have a quick primer on Gradio.
Accessing Gemini utilizing AI Studio
Google AI Studio enables you to entry Gemini fashions via an API. So, head over to the official web page and create an API key. Now, set up the next library.
pip set up google-generativeaiConfigure the API key by setting it as an setting variable:
import google.generativeai as genai
api_key = "api-key"
genai.configure(api_key=api_key)Now, inference from fashions.
mannequin = genai.GenerativeModel('gemini-pro')
response = mannequin.generate_content("What's the that means of life?",)The response construction is much like the earlier methodology.
print(response.candidates[0].content material.elements[0].textual content)Output

Equally, you may as well infer from the imaginative and prescient mannequin.
import PIL.Picture
img = "whisper_arch.png"
img = PIL.Picture.open(img)
mannequin = genai.GenerativeModel('gemini-pro-vision')
response = mannequin.generate_content(["Explain the architecture step by step in detail", img],
stream=True)
response.resolve()
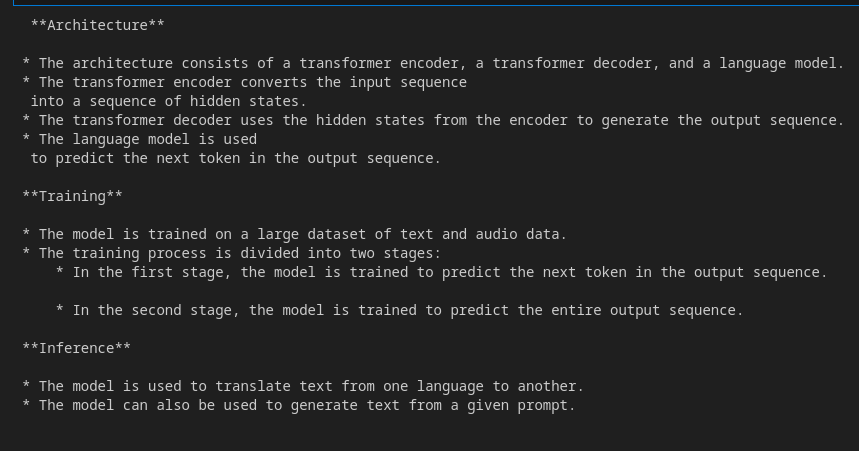
for resp in response:
print(resp.textual content)
Output
Ai Studio is a superb place to entry these fashions if you do not need to make use of GCP. As we’ll use VertexAI, it’s possible you’ll use this as an alternative with just a few modifications.
Let’s Begin Constructing QA Bot utilizing Gradio
Gradio is an open-source device to construct internet apps in Python to share Machine Studying fashions. It has modular parts that may be put collectively to create an internet app with out involving JavaScript or HTML codes. Gradio has Blocks API that permits you to create internet UIs with extra customization. The backend of Gradio is constructed with Fastapi, and the entrance finish is constructed with Svelte. The Python library abstracts away the underlying complexities and lets us shortly make an internet UI. On this article, we’ll use Gradio to construct our QA bot UI.
Discuss with this text for an in depth walk-through information for constructing a Gradio chatbot: Let’s Construct Your GPT Chatbot with Gradio
Entrance Finish with Gradio
We are going to use Gradio’s Blocks API and different parts to construct our entrance finish. So, set up Gradio with pip if you happen to haven’t already and import the library.
For the entrance finish, we want a chat UI for Q&A, a textual content field for sending consumer queries, a file field for importing Pictures/Movies and parts like a slider, and a radio button for customizing mannequin parameters, like temperature, top-k, top-p, and many others.
That is how we will do it with Gradio.
# Importing crucial libraries or modules
import gradio as gr
with gr.Blocks() as demo:
with gr.Row():
with gr.Column(scale=3):
gr.Markdown("Chatbot")
# Including a Chatbot with a peak of 650 and a duplicate button
chatbot = gr.Chatbot(show_copy_button=True, peak=650)
with gr.Row():
# Making a column with a scale of 6
with gr.Column(scale=6):
# Including a Textbox with a placeholder "write immediate"
immediate = gr.Textbox(placeholder="write your queries")
# Making a column with a scale of two
with gr.Column(scale=2):
# Including a File
file = gr.File()
# Making a column with a scale of two
with gr.Column(scale=2):
# Including a Button
button = gr.Button()
# Creating one other column with a scale of 1
with gr.Column(scale=1):
with gr.Row():
gr.Markdown("Mannequin Parameters")
# Including a Button with the worth "Reset"
reset_params = gr.Button(worth="Reset")
gr.Markdown("Normal")
# Including a Dropdown for mannequin choice
mannequin = gr.Dropdown(worth="gemini-pro", selections=["gemini-pro", "gemini-pro-vision"],
label="Mannequin", data="Select a mannequin", interactive=True)
# Including a Radio for streaming possibility
stream = gr.Radio(label="Streaming", selections=[True, False], worth=True,
interactive=True, data="Stream whereas responses are generated")
# Including a Slider for temperature
temparature = gr.Slider(worth=0.6, most=1.0, label="Temperature", interactive=True)
# Including a Textbox for cease sequence
stop_sequence = gr.Textbox(label="Cease Sequence",
data="Stops technology when the string is encountered.")
# Including a Markdown with the textual content "Superior"
gr.Markdown(worth="Superior")
# Including a Slider for top-k parameter
top_p = gr.Slider(
worth=0.4,
label="Prime-k",
interactive=True,
data="""Prime-k adjustments how the mannequin selects tokens for output:
decrease = much less random, increased = extra various. Defaults to 40."""
)
# Including a Slider for top-p parameter
top_k = gr.Slider(
worth=8,
label="Prime-p",
interactive=True,
data="""Prime-p adjustments how the mannequin selects tokens for output.
Tokens are chosen from most possible to least till
the sum of their possibilities equals the top-p worth"""
)
demo.queue()
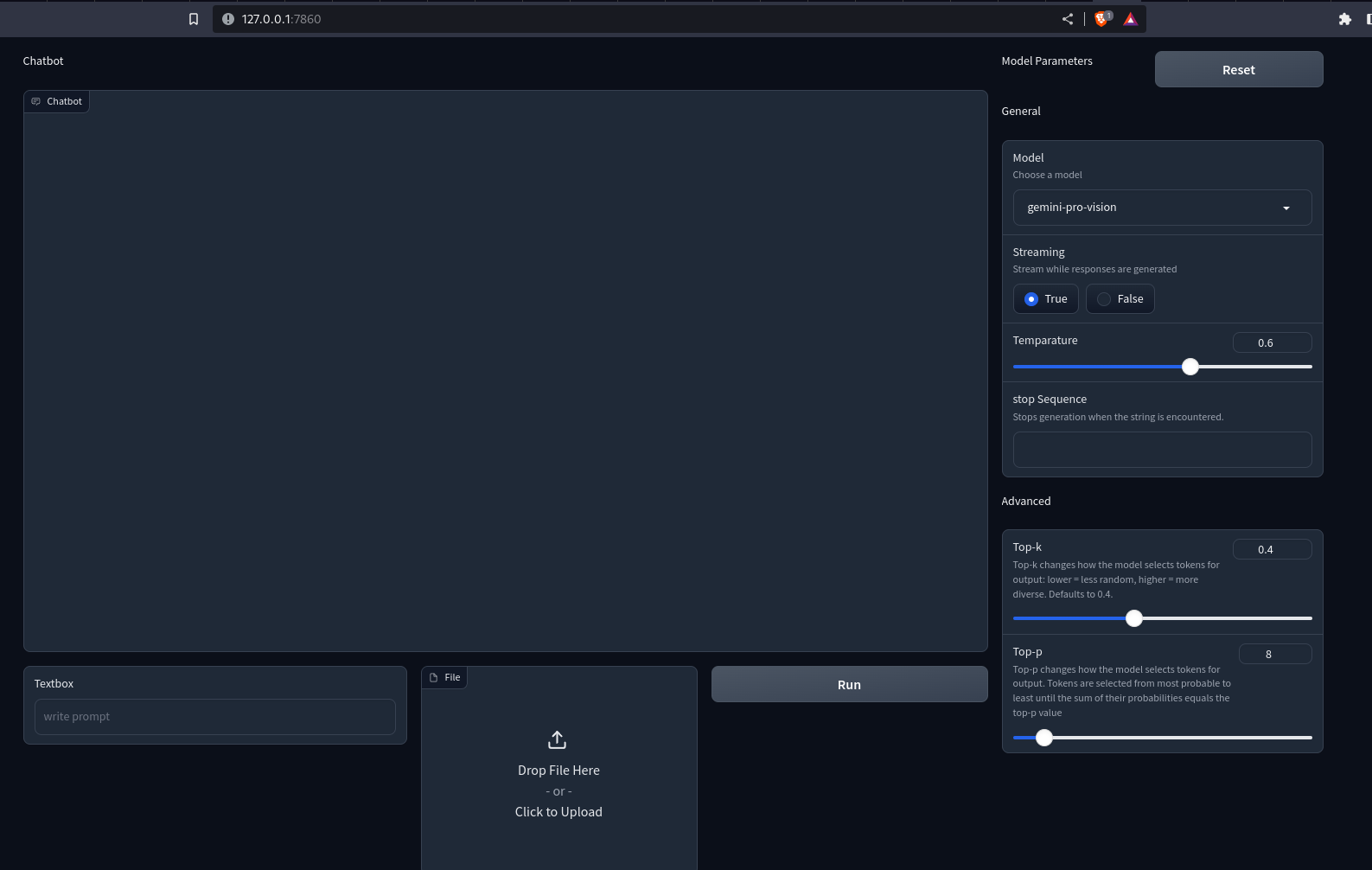
demo.launch()We’ve used Gradio’s Row and Column API for customizing the net interface. Now, run the Python file with the gradio app.py. This will open up a Uvicorn server at localhost:7860. That is what our app will appear like.
Output
You discover nothing occurs when urgent the buttons. To make it interactive, we have to outline occasion handlers. Right here, we want handlers for the Run and Reset buttons. That is how we will do it.
button.click on(fn=add_content, inputs=[prompt, chatbot, file], outputs=[chatbot])
.success(fn = gemini_generator.run, inputs=[chatbot, prompt, file, model, stream,
temparature, stop_sequence,
top_k, top_p], outputs=[prompt,file,chatbot]
)
reset_params.click on(fn=reset, outputs=[model, stream, temparature,
stop_sequence, top_p, top_k])When the clicking button is pressed, the perform within the fn parameter is known as with all of the inputs. The returned values of the perform are despatched to parts in outputs. The success occasion is how we will chain collectively a number of occasions. However you discover that we haven’t outlined the features. We have to outline these features to make them interactive.
Constructing the Again Finish
The primary perform we’ll outline right here is add_content. This can render consumer and API messages on the chat interface. That is how we will do that.
def add_content(textual content:str, chatbot:Chatbot, file: str)->Chatbot:
# Verify if each file and textual content are offered
if file and textual content:
# Concatenate the prevailing chatbot content material with new textual content and file content material
chatbot = chatbot + [(text, None), ((file,), None)]
# Verify if solely textual content is offered
elif textual content and never file:
# Concatenate the prevailing chatbot content material with a brand new textual content
chatbot += [(text, None)]
# Verify if solely the file is offered
elif file and never textual content:
# Concatenate the prevailing chatbot content material with a brand new file content material
chatbot += [((file,), None)]
else:
# Increase an error if neither textual content nor file is offered
increase gr.Error("Enter a legitimate textual content or a file")
# Return the up to date chatbot content material
return chatbot
The perform receives the textual content, chatbot, and file path. The chatbot is a listing of lists of tuples. The primary member of the tuple is the consumer question, and the second is the response from the chatbot. To ship multi-media recordsdata, we exchange the string with one other tuple. The primary member of this tuple is the file path or URL, and the second is the alt textual content. That is the conference for displaying media within the chat UI in Gradio.
Now, we’ll create a category with strategies for dealing with Gemini API responses.
from typing import Union, ByteString
from gradio import Half, GenerationConfig, GenerativeModel
class GeminiGenerator:
"""Multi-modal generator class for Gemini fashions"""
def _convert_part(self, half: Union[str, ByteString, Part]) -> Half:
# Convert various kinds of elements (str, ByteString, Half) to Half objects
if isinstance(half, str):
return Half.from_text(half)
elif isinstance(half, ByteString):
return Half.from_data(half.information, half.mime_type)
elif isinstance(half, Half):
return half
else:
msg = f"Unsupported sort {sort(half)} for half {half}"
increase ValueError(msg)
def _check_file(self, file):
# Verify if file is offered
if file:
return True
return False
def run(self, historical past, textual content: str, file: str, mannequin: str, stream: bool, temperature: float,
stop_sequence: str, top_k: int, top_p: float):
# Configure technology parameters
generation_config = GenerationConfig(
temperature=temperature,
top_k=top_k,
top_p=top_p,
stop_sequences=stop_sequence
)
self.shopper = GenerativeModel(model_name=mannequin, generation_config=generation_config,)
# Generate content material primarily based on enter parameters
if textual content and self._check_file(file):
# Convert textual content and file to Half objects and generate content material
contents = [self._convert_part(part) for part in [text, file]]
response = self.shopper.generate_content(contents=contents, stream=stream)
elif textual content:
# Convert textual content to a Half object and generate content material
content material = self._convert_part(textual content))
response = self.shopper.generate_content(contents=content material, stream=stream)
elif self._check_file(file):
# Convert file to a Half object and generate content material
content material = self._convert_part(file)
response = self.shopper.generate_content(contents=content material, stream=stream)
# Verify if streaming is True
if stream:
# Replace historical past and yield responses for streaming
historical past[-1][-1] = ""
for resp in response:
historical past[-1][-1] += resp.candidates[0].content material.elements[0].textual content
yield "", gr.File(worth=None), historical past
else:
# Append the generated content material to the chatbot historical past
historical past.append((None, response.candidates[0].content material.elements[0].textual content))
return " ", gr.File(worth=None), historical past
Within the above code snippet, We’ve outlined a category GeminiGenerator. The run() initiates a shopper with a mannequin identify and technology config. Then, we fetch responses from Gemini fashions primarily based on the offered information. The _convert_part() converts the info right into a Half object. The generate_content() requires information to be a string, Picture, or Half. Right here, we’re changing every information to Half to keep up homogeneity.
Now, provoke an object with the category.
gemini-generator = GeminiGenerator()We have to outline the reset_parameter perform. This resets the parameters to the default values.
def reset() -> Record[Component]:
return [
gr.Dropdown(value = "gemini-pro",choices=["gemini-pro", "gemini-pro-vision"],
label="Mannequin",
data="Select a mannequin", interactive=True),
gr.Radio(label="Streaming", selections=[True, False], worth=True, interactive=True,
data="Stream whereas responses are generated"),
gr.Slider(worth= 0.6,most=1.0, label="Temparature", interactive=True),
gr.Textbox(label="Token restrict", worth=2048),
gr.Textbox(label="cease Sequence",
data="Stops technology when the string is encountered."),
gr.Slider(
worth=40,
label="Prime-k",
interactive=True,
data="""Prime-k adjustments how the mannequin selects tokens for output: decrease = much less
random, increased = extra various. Defaults to 40."""
),
gr.Slider(
worth=8,
label="Prime-p",
interactive=True,
data="""Prime-p adjustments how the mannequin selects tokens for output.
Tokens are chosen from most possible to least till
the sum of their possibilities equals the top-p worth"""
)
]Right here, we’re simply returning the defaults. This resets the parameters.
Now reload the app on localhost. Now you can ship textual content queries and pictures/movies to Gemini fashions. The responses might be rendered on the chatbot. If the stream is about to True, the response chunks might be rendered progressively one chunk at a time.
Output
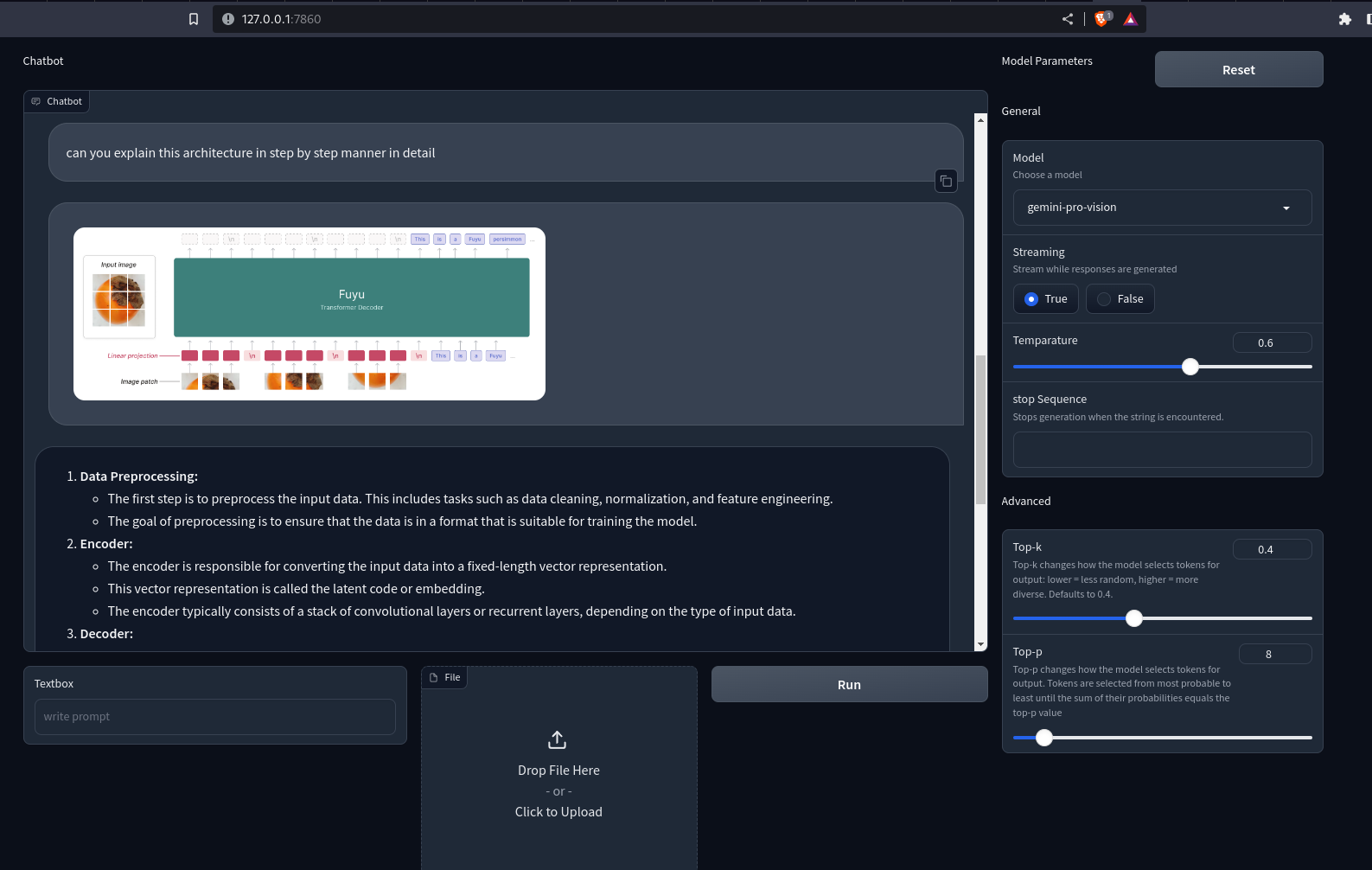
Right here is the GitHub repo for the Gradio app: sunilkumardash9/multimodal-chatbot
Conclusion
I hope you loved constructing QA bot utilizing Gemini and Gradio!
Google’s multi-modal mannequin will be useful for a number of use instances. A customized chatbot powered by it’s one such use case. We will lengthen the applying to incorporate totally different options, like including different fashions like GPT-4 and different open-source fashions. So, as an alternative of hopping from web site to web site, you possibly can have your individual LLM aggregator. Equally, we will lengthen the applying to help multi-modal RAG, video narration, visible entity extraction, and many others.
Key Takeaways
- Gemini is a household of fashions with three lessons of fashions. Extremely, Professional, and Nano.
- The fashions have been educated collectively over a number of modalities to realize state-of-the-art multi-modal understanding.
- Whereas the Extremely is essentially the most succesful mannequin, Google has solely made the Professional fashions public.
- The Gemini Professional and imaginative and prescient fashions will be accessed from Google Cloud VertexAI or Google AI Studio.
- Gradio is an open-source Python device for constructing fast internet demos of ML apps.
- We used Gradio’s Blocks API and different options to construct an interactive QA bot utilizing Gemini fashions.
Continuously Requested Questions
A. Whereas Google claims Gemini Extremely to be a greater mannequin, it has not been public but. The publicly obtainable fashions of Gemini are extra much like gpt-3.5-turbo in uncooked efficiency than GPT-4.
A. The Gemini Professional and Gemini Professional Imaginative and prescient fashions will be accessed at no cost on Google AI Studio for builders with 60 requests per minute.
A. A chatbot that may course of and perceive totally different modalities of knowledge, comparable to texts, pictures, audio, movies, and many others.
A. It’s an open-source Python device that permits you to shortly share machine-learning fashions with anybody.
A. The Gradio Interface is a robust, high-level class that permits the swift creation of a web-based graphical consumer interface (GUI) with just some strains of code.
The media proven on this article just isn’t owned by Analytics Vidhya and is used on the Writer’s discretion.

{kind=link}