

Put up by Angela Wang and Tanner McRae, Senior Engineers on the AWS Options Structure R&D and Innovation crew
This publish is the third in a sequence on easy methods to construct and deploy a {custom} object detection mannequin to the sting utilizing Amazon SageMaker and AWS IoT Greengrass. Within the earlier 2 elements of the sequence, we walked you thru making ready coaching information and coaching a {custom} object detection mannequin utilizing the built-in SSD algorithm of Amazon SageMaker. You additionally transformed the mannequin output file right into a deployable format. On this publish, we take the output file and present you easy methods to run the inference on an edge gadget utilizing AWS IoT Greengrass.
Right here’s a reminder of the structure that you’re constructing as a complete:
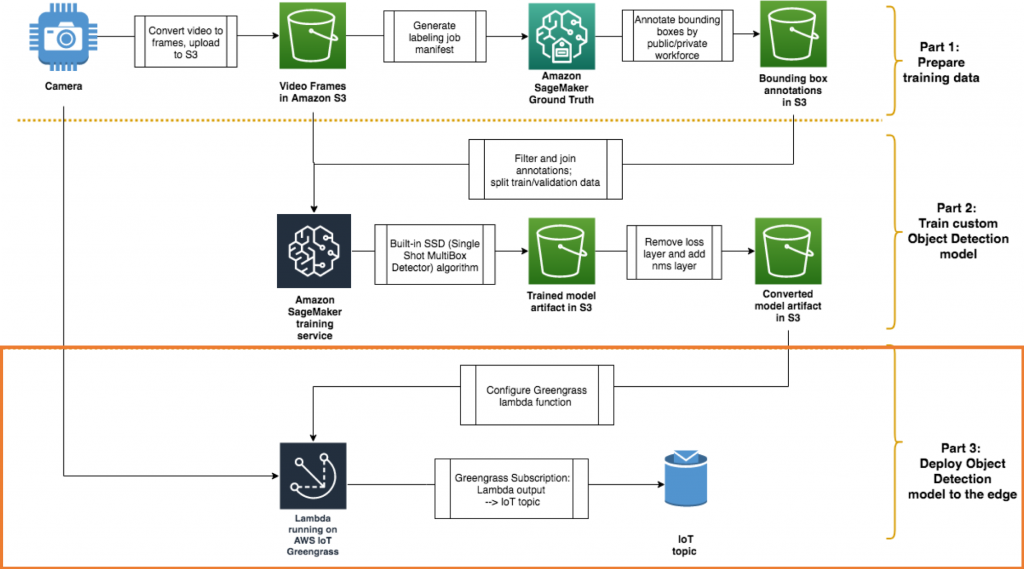
Following the steps in your AWS account
You’re welcome to comply with the upcoming steps in your personal AWS account and in your edge gadget. Components 1 and half 2 will not be stipulations for following this part. You should utilize both a {custom} mannequin that you’ve skilled or the instance mannequin that we supplied (underneath the CDLA Permissive license).
Arrange setting and AWS IoT Greengrass Core on an edge gadget
Earlier than you get began putting in AWS IoT Greengrass core in your edge gadget, be sure you examine the {hardware} and OS necessities. For this publish, we used an Amazon EC2 occasion with the Ubuntu 18.04 AMI. Though it’s not an actual edge gadget, we regularly discover it useful to make use of an EC2 occasion as a testing and growth setting for AWS IoT use instances.
Machine setup
For GPU-enabled units, be sure you have the GPU drivers, akin to CUDA, put in. In case your gadget solely has CPUs, you may nonetheless run the inference however with slower efficiency.
Additionally make sure that to put in MXNet and OpenCV, which is required to run the mannequin inference code, in your edge gadget. For steerage, see documentation right here.
Subsequent, configure your gadget, and set up the AWS IoT Greengrass core software program following the steps in Arrange setting and set up AWS IoT Greengrass software program.
Alternately, launch a take a look at EC2 occasion with the previous setup accomplished by launching this AWS CloudFormation stack:
![]()
Create an AWS IoT Greengrass group
Now you’re able to create an AWS IoT Greengrass group within the AWS Cloud. There are few other ways to do that and configure AWS Lambda capabilities to run your mannequin on the edge:
On this publish, we stroll you thru establishing this object detection mannequin utilizing Greengo. Our crew prefers the Greengo mission to handle AWS IoT Greengrass deployment, particularly to be used in a speedy prototyping and growth setting. We advocate utilizing AWS CloudFormation for managing manufacturing environments.
On a macOS or Linux pc, use git clone to obtain the pattern code that we supplied in the event you haven’t carried out so already. The instructions proven right here haven’t been examined on Home windows.
Within the greengrass/ folder, you see a greengo.yaml file, which defines configurations and Lambda capabilities for an AWS IoT Greengrass group. The highest portion of the file defines the identify of the AWS IoT Greengrass group and AWS IoT Greengrass cores:
Group:
identify: GG_Object_Detection
Cores:
- identify: GG_Object_Detection_Core
key_path: ./certs
config_path: ./config
SyncShadow: TrueFor the preliminary setup of the AWS IoT Greengrass group assets in AWS IoT, run the next command within the folder through which you discovered greengo.yaml.
pip set up greengo
greengo createThis creates all AWS IoT Greengrass group artifacts in AWS and locations the certificates and config.json for AWS IoT Greengrass Core in ./certs/ and ./config/.
It additionally generates a state file in .gg/gg_state.json that references all the fitting assets throughout deployment:
Copy the certs and config folder to the sting gadget (or take a look at EC2 occasion) utilizing scp, after which copy them to the /greengrass/certs/ and /greengrass/config/ directories on the gadget.
sudo cp certs/* /greengrass/certs/
sudo cp config/* /greengrass/config/In your gadget, additionally obtain the root CA certificates suitable with the certificates Greengo generated to the /greengrass/certs/ folder:
cd /greengrass/certs/
sudo wget -O root.ca.pem https://www.symantec.com/content material/en/us/enterprise/verisign/roots/VeriSign-Classpercent203-Public-Major-Certification-Authority-G5.pemBegin AWS IoT Greengrass core
Now you’re prepared to begin the AWS IoT Greengrass core daemon on the sting gadget.
$ sudo /greengrass/ggc/core/greengrassd begin
Organising greengrass daemon
Validating hardlink/softlink safety
Ready for as much as 1m10s for Daemon to begin
...
Greengrass efficiently began with PID: 4722Preliminary AWS IoT Greengrass group deployment
When the AWS IoT Greengrass daemon is up and working, return to the place you could have downloaded the code repo from GitHub in your laptop computer or workstation. Then, go to the greengrass/ folder (the place greengo.yaml resides) and run the next command:
greengo deployThis deploys the configurations you outline in greengo.yaml to the AWS IoT Greengrass core on the sting gadget. To date, you haven’t outlined any Lambda capabilities but within the Greengo configuration, so this deployment simply initializes the AWS IoT Greengrass core. You add a Lambda perform to the AWS IoT Greengrass setup after you do a fast sanity take a look at within the subsequent step.
MXNet inference code
On the finish of the final publish, you used the next inference code on a Jupyter pocket book. Within the run_model/ folder, evaluation how you set this right into a single Python class MLModel inside model_loader.py:
class MLModel(object):
"""
Masses the pre-trained mannequin, which will be present in /ml/od when working on greengrass core or
from a special path for testing regionally.
"""
def __init__(self, param_path, label_names=[], input_shapes=[('data', (1, 3, DEFAULT_INPUT_SHAPE, DEFAULT_INPUT_SHAPE))]):
# use the primary GPU gadget accessible for inference. If GPU not accessible, CPU is used
context = get_ctx()[0]
# Load the community parameters from default epoch 0
logging.information('Load community parameters from default epoch 0 with prefix: {}'.format(param_path))
sym, arg_params, aux_params = mx.mannequin.load_checkpoint(param_path, 0)
# Load the community into an MXNet module and bind the corresponding parameters
logging.information('Loading community into mxnet module and binding corresponding parameters: {}'.format(arg_params))
self.mod = mx.mod.Module(image=sym, label_names=label_names, context=context)
self.mod.bind(for_training=False, data_shapes=input_shapes)
self.mod.set_params(arg_params, aux_params)
"""
Takes in a picture, reshapes it, and runs it via the loaded MXNet graph for inference returning the highest label from the softmax
"""
def predict_from_file(self, filepath, reshape=(DEFAULT_INPUT_SHAPE, DEFAULT_INPUT_SHAPE)):
# Swap RGB to BGR format (which ImageNet networks take)
img = cv2.cvtColor(cv2.imread(filepath), cv2.COLOR_BGR2RGB)
if img is None:
return []
# Resize picture to suit community enter
img = cv2.resize(img, reshape)
img = np.swapaxes(img, 0, 2)
img = np.swapaxes(img, 1, 2)
img = img[np.newaxis, :]
self.mod.ahead(Batch([mx.nd.array(img)]))
prob = self.mod.get_outputs()[0].asnumpy()
prob = np.squeeze(prob)
# Seize prime outcome, convert to python listing of lists and return
outcomes = [prob[0].tolist()]
return outcomesCheck inference code on gadget immediately (elective)
Though elective, it’s all the time useful to run a fast take a look at on the sting gadget to confirm that the opposite dependencies (MXNet and others) have been arrange correctly.
We’ve written a unit take a look at test_model_loader.py that assessments the previous MLModel class. Assessment the code on this GitHub repository.
To run the unit take a look at, obtain the code and machine studying (ML) mannequin artifacts to the sting gadget and kick off the unit take a look at:
git clone https://github.com/aws-samples/amazon-sagemaker-aws-greengrass-custom-object-detection-model.git
cd amazon-sagemaker-aws-greengrass-custom-object-detection-model/greengrass/run_model/assets/ml/od
wget https://greengrass-object-detection-blog.s3.amazonaws.com/deployable-model/deploy_model_algo_1-0000.params
cd ../../..
python -m unittest take a look at.test_model_loader.TestModelLoaderAfter the unit assessments go, now you can evaluation how this code can be utilized within an AWS IoT Greengrass Lambda perform.
Creating your inference pipeline in AWS IoT Greengrass core
Now that you’ve began AWS IoT Greengrass and examined the inference code on the sting gadget, you’re able to put all of it collectively: create an AWS IoT Greengrass Lambda perform that runs the inference code contained in the AWS IoT Greengrass core.
To check the AWS IoT Greengrass Lambda perform for inference, create the next pipeline:

- A Lambda perform that comprises the item detection inference code is working in AWS IoT Greengrass core BlogInfer.
- The AWS IoT subject weblog/infer/enter supplies enter to the BlogInfer Lambda perform for the situation of the picture file on the sting gadget to do inference on.
- The IoT subject weblog/infer/output publishes the prediction output of the BlogInfer Lambda perform to the AWS IoT message dealer within the cloud.
Select lifecycle configuration for AWS IoT Greengrass Lambda perform
There are two kinds of AWS IoT Greengrass Lambda capabilities: on-demand or long-lived. For doing ML inference, it’s essential to run the mannequin in a long-lived perform as a result of loading an ML mannequin into reminiscence can typically take 300 ms or longer.
Working ML inference code in a long-lived AWS IoT Greengrass Lambda perform means that you can incur the initialization latency just one time. When the AWS IoT Greengrass core begins up, a single container for a long-running Lambda perform is created and stays working. Each invocation of the Lambda perform reuses the identical container and makes use of the identical ML mannequin that has already been loaded into reminiscence.
Create Lambda perform code
To show the previous inference code right into a Lambda perform, you created a essential.py because the entry level for Lambda perform. As a result of it is a long-lived perform, initialize the MLModel object exterior of the lambda_handler. Code contained in the lambda_handler perform will get referred to as every time new enter is out there on your perform to course of.
import greengrasssdk
from model_loader import MLModel
import logging
import os
import time
import json
ML_MODEL_BASE_PATH = '/ml/od/'
ML_MODEL_PREFIX = 'deploy_model_algo_1'
# Making a Greengrass Core sdk shopper
shopper = greengrasssdk.shopper('iot-data')
mannequin = None
# Load the mannequin at startup
def initialize(param_path=os.path.be a part of(ML_MODEL_BASE_PATH, ML_MODEL_PREFIX)):
international mannequin
mannequin = MLModel(param_path)
def lambda_handler(occasion, context):
"""
Will get referred to as every time the perform will get invoked.
"""
if 'filepath' not in occasion:
logging.information('filepath will not be in enter occasion. nothing to do. returning.')
return None
filepath = occasion['filepath']
logging.information('predicting on picture at filepath: {}'.format(filepath))
begin = int(spherical(time.time() * 1000))
prediction = mannequin.predict_from_file(filepath)
finish = int(spherical(time.time() * 1000))
logging.information('Prediction: {} for file: {} in: {}'.format(prediction, filepath, finish - begin))
response = {
'prediction': prediction,
'timestamp': time.time(),
'filepath': filepath
}
shopper.publish(subject="weblog/infer/output", payload=json.dumps(response))
return response
# If this path exists, then this code is working on the greengrass core and has the ML assets to initialize.
if os.path.exists(ML_MODEL_BASE_PATH):
initialize()
else:
logging.information('{} doesn't exist and you can't initialize this Lambda perform.'.format(ML_MODEL_BASE_PATH))
Configure ML useful resource in AWS IoT Greengrass utilizing Greengo
For those who adopted the step to run the unit take a look at on the sting gadget, you needed to copy the ML mannequin parameter information manually to the sting gadget. This isn’t a scalable manner of managing the deployment of the ML mannequin artifacts.
What in the event you commonly retrain your ML mannequin and proceed to deploy newer variations of your ML mannequin? What you probably have a number of edge units that every one ought to obtain the brand new ML mannequin? To simplify the method of deploying a brand new ML mannequin artifact to the sting, AWS IoT Greengrass helps the administration of machine studying assets.
If you outline an ML useful resource in AWS IoT Greengrass, you add the assets to an AWS IoT Greengrass group. You outline how Lambda capabilities within the group can entry them. As a part of AWS IoT Greengrass group deployment, AWS IoT Greengrass downloads the ML artifacts from Amazon S3 and extracts them to directories contained in the Lambda runtime namespace.
Then your AWS IoT Greengrass Lambda perform can use the regionally deployed fashions to carry out inference. When your ML mannequin artifacts have a brand new model to be deployed, it’s essential to redeploy the AWS IoT Greengrass group. The AWS IoT Greengrass service routinely checks if the supply file has modified and solely obtain the brand new model if there may be an replace.
To outline the machine studying useful resource in your AWS IoT Greengrass group, uncomment this part in your greengo.yaml file. (To make use of your personal mannequin, substitute the S3Uri with your personal values.)
Sources:
- Identify: MyObjectDetectionModel
Id: MyObjectDetectionModel
S3MachineLearningModelResourceData:
DestinationPath: /ml/od/
S3Uri: s3://greengrass-object-detection-blog/deployable-model/deploy_model.tar.gzUse the next command to deploy the configuration change:
greengo replace && greengo deployWithin the AWS IoT Greengrass console, it is best to now see an ML useful resource created. The next screenshot exhibits the standing of the mannequin as Unaffiliated. That is anticipated, since you haven’t hooked up it to a Lambda perform but.

To troubleshoot an ML useful resource deployment, it’s useful to keep in mind that AWS IoT Greengrass has a containerized structure. It makes use of filesystem overlay when it deploys assets akin to ML mannequin artifacts.
Within the previous instance, despite the fact that you configured the ML mannequin artifacts to be extracted to /ml/od/, AWS IoT Greengrass really downloads it to one thing like /greengrass/ggc/deployment/mlmodel/<uuid>/. To your AWS IoT Greengrass native Lambda perform that you just declare to make use of this artifact, the extracted information look like saved in/ml/od/ because of the filesystem overlay.
Configure the Lambda perform with Greengo
To configure your Lambda perform and provides it entry to the machine studying useful resource beforehand outlined, uncomment your greengo.yaml file:
Lambdas:
- identify: BlogInfer
handler: essential.lambda_handler
package deal: ./run_model/src
alias: dev
greengrassConfig:
MemorySize: 900000 # Kb
Timeout: 10 # seconds
Pinned: True # True for long-lived capabilities
Surroundings:
AccessSysfs: True
ResourceAccessPolicies:
- ResourceId: MyObjectDetectionModel
Permission: 'rw'You didn’t specify the language runtime for the Lambda perform. It is because, in the intervening time, the Greengo mission solely helps Lambda capabilities working python2.7.
Additionally, in case your edge gadget doesn’t have already got greengrasssdk put in, you may set up greengrasssdk to the ./run_model/src/ listing and have it included within the Lambda deployment package deal:
cd run_model/src/
pip set up greengrasssdk -t .Utilizing GPU-enabled units
In case you are utilizing a CPU-only gadget, you may skip to the following part.
In case you are utilizing an edge gadget or occasion with GPU, it’s essential to allow the Lambda perform to entry the GPU units, utilizing the native assets characteristic of AWS IoT Greengrass.
To outline the gadget useful resource in greengo.yaml, uncomment the part underneath Sources:
- Identify: Nvidia0
Id: Nvidia0
LocalDeviceResourceData:
SourcePath: /dev/nvidia0
GroupOwnerSetting:
AutoAddGroupOwner: True
- Identify: Nvidiactl
Id: Nvidiactl
LocalDeviceResourceData:
SourcePath: /dev/nvidiactl
GroupOwnerSetting:
AutoAddGroupOwner: True
- Identify: NvidiaUVM
Id: NvidiaUVM
LocalDeviceResourceData:
SourcePath: /dev/nvidia-uvm
GroupOwnerSetting:
AutoAddGroupOwner: True
- Identify: NvidiaUVMTools
Id: NvidiaUVMTools
LocalDeviceResourceData:
SourcePath: /dev/nvidia-uvm-tools
GroupOwnerSetting:
AutoAddGroupOwner: TrueTo allow the inference Lambda perform to entry the gadget assets, uncomment the next part contained in the ResourceAccessPolicies of the Lambda perform.
- ResourceId: Nvidia0
Permission: 'rw'
- ResourceId: Nvidiactl
Permission: 'rw'
- ResourceId: NvidiaUVM
Permission: 'rw'
- ResourceId: NvidiaUVMTools
Permission: 'rw'Configure subject subscriptions with Greengo
Lastly, to check invoking the inference Lambda perform and receiving its outputs, create subscriptions for inputs and outputs for the inference Lambda perform. Uncomment this part in your greengo.yaml file:
Subscriptions:
# Check Subscriptions from the cloud
- Supply: cloud
Topic: weblog/infer/enter
Goal: Lambda::BlogInfer
- Supply: Lambda::BlogInfer
Topic: weblog/infer/output
Goal: cloudTo deploy these configurations to AWS IoT Greengrass, run the next command.
greengo replace && greengo deployWhen the deployment is completed, you may also evaluation the subscription configuration within the AWS IoT Greengrass console:

And in the event you examine the Lambda perform that was deployed, you may see that the ML useful resource is now affiliated with it:

Check AWS IoT Greengrass Lambda perform
Now you may take a look at invoking the Lambda perform. Be sure that you obtain a picture (instance) to your edge gadget, as a way to use it to check the inference.
Within the AWS IoT Greengrass console, select Check, and subscribe to the weblog/infer/output subject. Then, publish a message weblog/infer/enter specifying the trail of the picture to do inference on the sting gadget:

You need to have gotten again bounding field prediction outcomes.
Take it to real-time video inference
To date, the implementation creates a Lambda perform that may do inference on a picture file on the sting gadget. To have it carry out real-time inference on a video supply, you may lengthen the structure. Add one other long-lived Lambda perform that captures video from a digital camera, extracts frames from video (much like what we did in half 1), and passes the reference of the picture to the ML inference perform:

Useful resource cleanup
Remember that you’re charged for assets working on AWS, so bear in mind to scrub up the assets you probably have been following alongside:
- Delete the AWS IoT Greengrass group by working
greengo take away. - Shut down the Amazon SageMaker pocket book occasion.
- Delete the AWS CloudFormation stack in the event you used a take a look at EC2 occasion to run AWS IoT Greengrass.
- Clear up S3 buckets used.
Conclusion
On this publish sequence, we walked via the method of coaching and deploying an object detection mannequin to the sting from finish to finish. We began from capturing coaching information and shared greatest practices in deciding on coaching information and getting high-quality labels. We then mentioned suggestions for utilizing the Amazon SageMaker built-in object detection mannequin to coach your {custom} mannequin and convert the output to a deployable format. Lastly, we walked via establishing the sting gadget and utilizing AWS IoT Greengrass to simplify code deployment to the sting and sending the prediction output to the cloud.
We see a lot potential for working object detection fashions on the edge to enhance processes in manufacturing, provide chain, and retail. We’re excited to see what you construct with this highly effective mixture of ML and IoT.
You could find all of the code that we lined at this GitHub repository.
Different posts on this three-part sequence:

{kind=link}
{kind=link}