Whether or not in retail, finance, cyber safety, or every other business, recognizing anomalous habits as quickly because it occurs is an absolute precedence. The dearth of capabilities to take action may imply misplaced income, fines from regulators, and violation of buyer privateness and belief as a consequence of safety breaches within the case of cyber safety. Thus, discovering that handful of fairly uncommon bank card transactions, recognizing that one person performing suspiciously or figuring out unusual patterns in request quantity to an internet service, could possibly be the distinction between a terrific day at work and an entire catastrophe.
The Problem in Detecting Anomalies
Anomaly detection poses a number of challenges. The primary is the info science query of what an ‘anomaly’ appears to be like like. Happily, machine studying has highly effective instruments to learn to distinguish ordinary from anomalous patterns from knowledge. Within the case of anomaly detection, it’s not possible to know what all anomalies appear like, so it’s not possible to label an information set for coaching a machine studying mannequin, even when assets for doing so can be found. Thus, unsupervised studying needs to be used to detect anomalies, the place patterns are realized from unlabelled knowledge.
Even with the right unsupervised machine studying mannequin for anomaly detection found out, in some ways, the actual issues have solely begun. What’s one of the simplest ways to place this mannequin into manufacturing such that every remark is ingested, reworked and eventually scored with the mannequin, as quickly as the info arrives from the supply system? That too, in a close to real-time method or at quick intervals, e.g. each 5-10 minutes? This includes constructing a classy extract, load, and rework (ELT) pipeline and integrating it with an unsupervised machine studying mannequin that may accurately establish anomalous information. Additionally, this end-to-end pipeline needs to be production-grade, at all times working whereas guaranteeing knowledge high quality from ingestion to mannequin inference, and the underlying infrastructure needs to be maintained.
Fixing the Problem with the Databricks Lakehouse Platform
With Databricks, this course of isn’t difficult. One may construct a near-real-time anomaly detection pipeline solely in SQL, with Python solely getting used to coach the machine studying mannequin. The information ingestion, transformations, and mannequin inference may all be performed with SQL.
Particularly, this weblog outlines coaching an isolation forest algorithm, which is especially suited to detecting anomalous information, and integrating the skilled mannequin right into a streaming knowledge pipeline created utilizing Delta Dwell Tables (DLT). DLT is an ETL framework that automates the info engineering course of. DLT makes use of a easy declarative method for creating dependable knowledge pipelines and totally manages the underlying infrastructure at scale for batch and streaming knowledge. The result’s a near-real-time anomaly detection system. Particularly, the info used on this weblog is a pattern of artificial knowledge generated with the purpose of simulating bank card transactions from Kaggle, and the anomalies thus detected are fraudulent transactions.
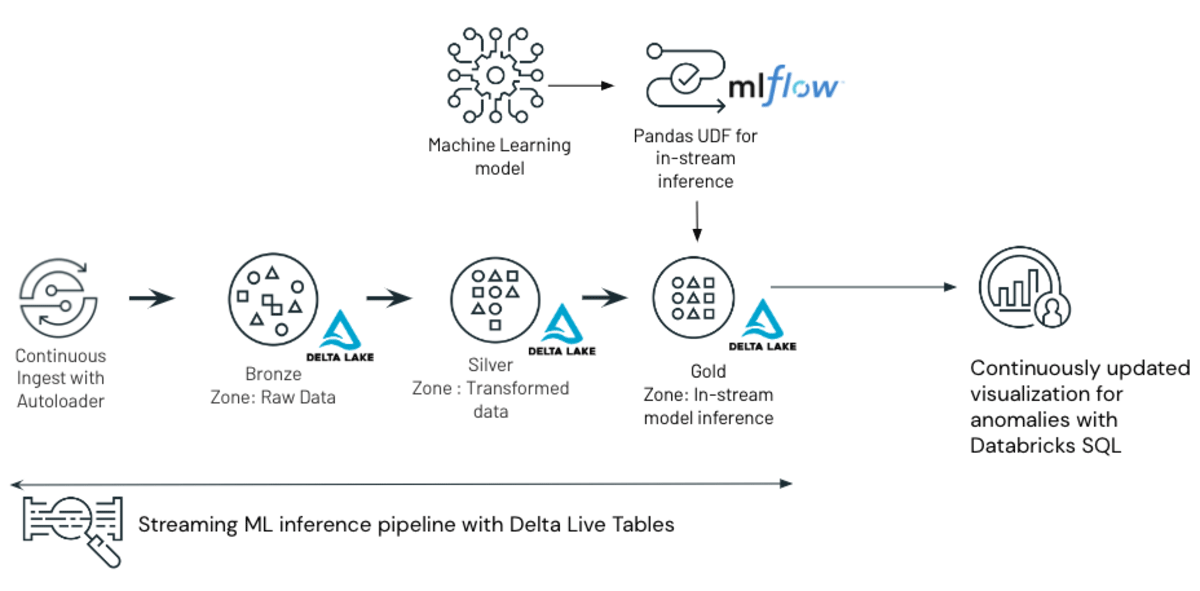
Structure of the ML and Delta Dwell Tables primarily based anomaly detection answer outlined within the weblog
The scikit-learn isolation forest algorithm implementation is offered by default within the Databricks Machine Studying runtime and can use the MLflow framework to trace and log the anomaly detection mannequin as it’s skilled. The ETL pipeline shall be developed solely in SQL utilizing Delta Dwell Tables.
Isolation Forests For Anomaly Detection on Unlabelled Knowledge
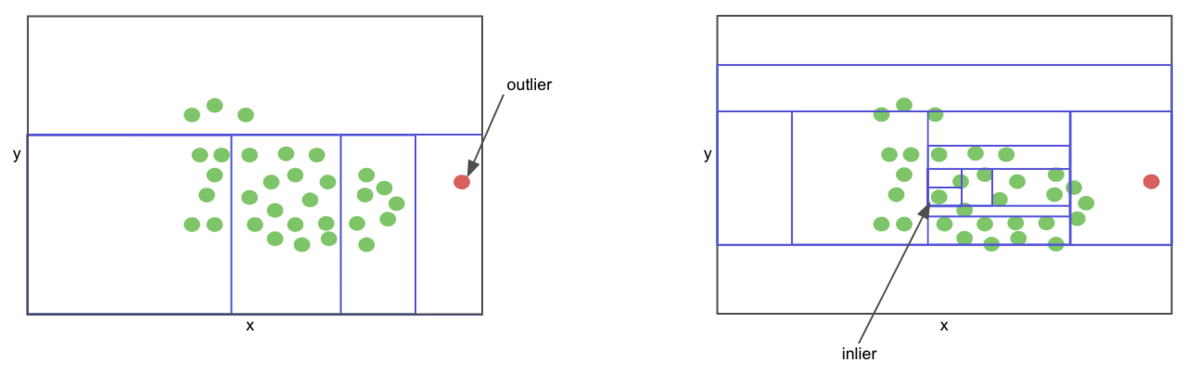
Isolation forests are a sort of tree-based ensemble algorithms just like random forests. The algorithm is designed to imagine that inliers in a given set of observations are more durable to isolate than outliers (anomalous observations). At a excessive stage, a non-anomalous level, that may be a common bank card transaction, would stay deeper in a choice tree as they’re more durable to isolate, and the inverse is true for an anomalous level. This algorithm might be skilled on a label-less set of observations and subsequently used to foretell anomalous information in beforehand unseen knowledge.
Isolating an outlier is simpler than isolating an inlier
How can Databricks Assist in mannequin coaching and monitoring?
When doing something machine studying associated on Databricks, utilizing clusters with the Machine Studying (ML) runtime is a should. Many open supply libraries generally used for knowledge science and machine studying associated duties can be found by default within the ML runtime. Scikit-learn is amongst these libraries, and it comes with a wonderful implementation of the isolation forest algorithm.
How the mannequin is outlined might be seen beneath.
from sklearn.ensemble import IsolationForest
isolation_forest = IsolationForest(n_jobs=-1, warm_start=True, random_state=42)
This runtime, amongst different issues, allows tight integration of the pocket book surroundings with MLflow for machine studying experiment monitoring, mannequin staging, and deployment.
Any mannequin coaching or hyperparameter optimization performed within the pocket book surroundings tied to a ML cluster is routinely logged with MLflow autologging, a performance enabled by default.
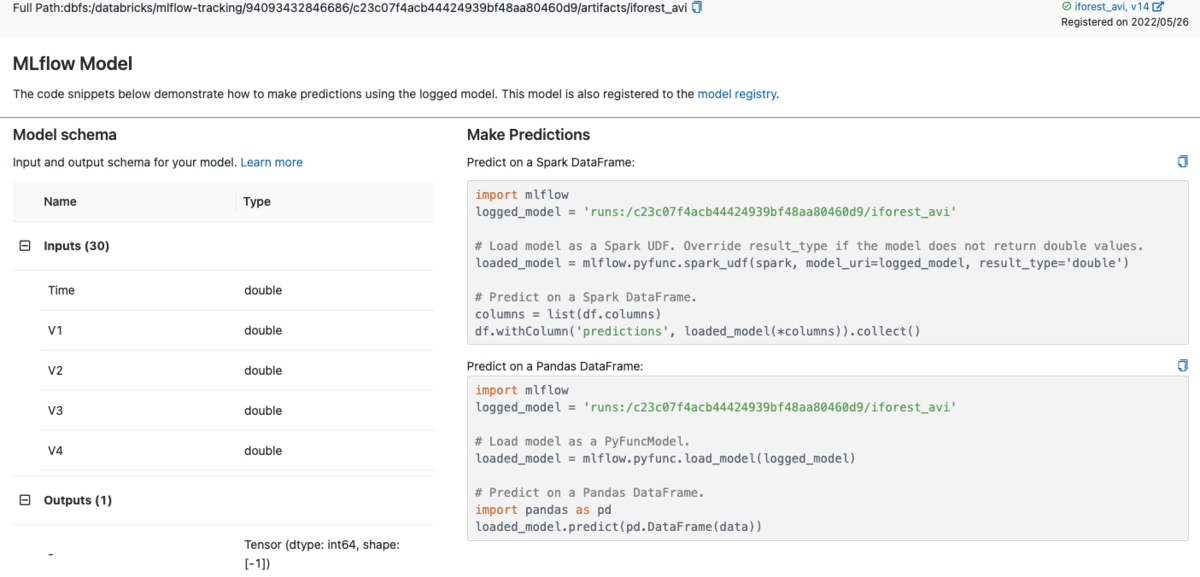
As soon as the mannequin is logged, it’s potential to register and deploy the mannequin inside MLflow in various methods. Particularly, to deploy this mannequin as a vectorized Person Outlined Perform (UDF) for distributed in-stream or batch inference with Apache Spark™, MLflow generates the code for creating and registering the UDF throughout the person interface (UI) itself, as might be seen within the picture beneath.
MLflow generates code for creating and registering the Apache Spark UDF for mannequin inference
Along with this, the MLflow REST API permits the prevailing mannequin in manufacturing to be archived and the newly skilled mannequin to be put into manufacturing with just a few traces of code that may be neatly packed right into a operate as follows.
def train_model(mlFlowClient, loaded_model, model_name, run_name)->str:
"""
Trains, logs, registers and promotes the mannequin to manufacturing. Returns the URI of the mannequin in prod
"""
with mlflow.start_run(run_name=run_name) as run:
# 0. Match the mannequin
loaded_model.match(X_train)
# 1. Get predictions
y_train_predict = loaded_model.predict(X_train)
# 2. Create mannequin signature
signature = infer_signature(X_train, y_train_predict)
runID = run.information.run_id
# 3. Log the mannequin alongside the mannequin signature
mlflow.sklearn.log_model(loaded_model, model_name, signature=signature, registered_model_name= model_name)
# 4. Get the most recent model of the mannequin
model_version = mlFlowClient.get_latest_versions(model_name,phases=['None'])[0].model
# 5. Transition the most recent model of the mannequin to manufacturing and archive the prevailing variations
consumer.transition_model_version_stage(title= model_name, model = model_version, stage="Manufacturing", archive_existing_versions= True)
return mlFlowClient.get_latest_versions(model_name, phases=["Production"])[0].supply
In a manufacturing situation, you’d desire a single document solely to be scored by the mannequin as soon as. In Databricks, you should use the Auto Loader to ensure this “precisely as soon as” habits. Auto Loader works with Delta Dwell Tables, Structured Streaming functions, both utilizing Python or SQL.
One other essential issue to contemplate is that the character of anomalous occurrences, whether or not environmental or behavioral, modifications with time. Therefore, the mannequin must be retrained on new knowledge because it arrives.
The pocket book with the mannequin coaching logic might be productionized as a scheduled job in Databricks Workflows, which successfully retrains and places into manufacturing the most recent mannequin every time the job is executed.
Reaching close to real-time anomaly detection with Delta Dwell Tables
The machine studying side of this solely presents a fraction of the problem. Arguably, what’s tougher is constructing a production-grade close to real-time knowledge pipeline that mixes knowledge ingestion, transformations and mannequin inference. This course of could possibly be complicated, time-consuming, and error-prone.
Constructing and sustaining the infrastructure to do that in an always-on capability and error dealing with includes extra software program engineering know-how than knowledge engineering. Additionally, knowledge high quality needs to be ensured via your complete pipeline. Relying on the particular utility, there could possibly be added dimensions of complexity.
That is the place Delta Dwell Tables (DLT) comes into the image.
In DLT parlance, a pocket book library is actually a pocket book that incorporates some or the entire code for the DLT pipeline. DLT pipelines might have multiple pocket book’s related to them, and every pocket book might use both SQL or Python syntax. The primary pocket book library will include the logic carried out in Python to fetch the mannequin from the MLflow Mannequin Registry and register the UDF in order that the mannequin inference operate can be utilized as soon as ingested information are featurized downstream within the pipeline. A useful tip: in DLT Python notebooks, new packages have to be put in with the %pip magic command within the first cell.
The second DLT library pocket book might be composed of both Python or SQL syntax. To show the flexibility of DLT, we used SQL to carry out the info ingestion, transformation and mannequin inference. This pocket book incorporates the precise knowledge transformation logic which constitutes the pipeline.
The ingestion is completed with Auto Loader, which might load knowledge streamed into object storage incrementally. That is learn into the bronze (uncooked knowledge) desk within the medallion structure. Additionally, within the syntax given beneath, please notice that the streaming stay desk is the place knowledge is repeatedly ingested from object storage. Auto Loader is configured to detect schema as the info is ingested. Auto Loader may deal with evolving schema, which is able to apply to many real-world anomaly detection situations.
CREATE OR REFRESH STREAMING LIVE TABLE transaction_readings_raw
COMMENT "The uncooked transaction readings, ingested from touchdown listing"
TBLPROPERTIES ("high quality" = "bronze")
AS SELECT * FROM cloud_files("/FileStore/tables/transaction_landing_dir", "json", map("cloudFiles.inferColumnTypes", "true"))
DLT additionally means that you can outline knowledge high quality constraints and gives the developer or analyst the power to remediate any errors. If a given document doesn’t meet a given constraint, DLT can retain the document, drop it or halt the pipeline solely. Within the instance beneath, constraints are outlined in one of many transformation steps that drop information if the transaction time or quantity isn’t given.
CREATE OR REFRESH STREAMING LIVE TABLE transaction_readings_cleaned(
CONSTRAINT valid_transaction_reading EXPECT (AMOUNT IS NOT NULL OR TIME IS NOT NULL) ON VIOLATION DROP ROW
)
TBLPROPERTIES ("high quality" = "silver")
COMMENT "Drop all rows with nulls for Time and retailer these information in a silver delta desk"
AS SELECT * FROM STREAM(stay.transaction_readings_raw)
Delta Dwell Tables additionally helps Person Outlined Features (UDFs). UDFs could also be used for to allow mannequin inference in a streaming DLT pipeline utilizing SQL. Within the beneath instance, we areusing the beforehand registered Apache Spark™ Vectorized UDF that encapsulates the skilled isolation forest mannequin.
CREATE OR REFRESH STREAMING LIVE TABLE predictions
COMMENT "Use the isolation forest vectorized udf registered within the earlier step to foretell anomalous transaction readings"
TBLPROPERTIES ("high quality" = "gold")
AS SELECT cust_id, detect_anomaly() as
anomalous from STREAM(stay.transaction_readings_cleaned)
That is thrilling for SQL analysts and Knowledge Engineers preferring SQL as they’ll use a machine studying mannequin skilled by an information scientist in Python e.g. utilizing scikit-learn, xgboost or every other machine studying library, for inference in a completely SQL knowledge pipeline!
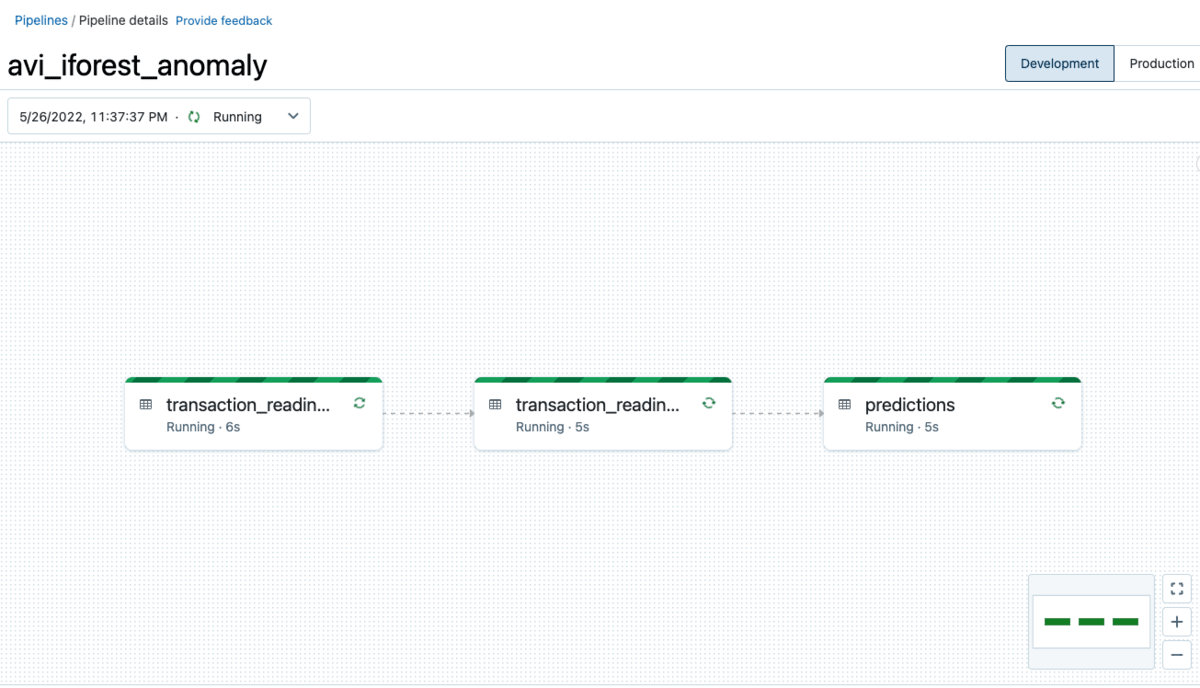
These notebooks are used to create a DLT pipeline (detailed within the Configuration Particulars part beneath ). After a quick interval of establishing assets, tables and determining dependencies (and all the opposite complicated operations DLT abstracts away from the tip person), a DLT pipeline shall be rendered within the UI, via which knowledge is repeatedly processed and anomalous information are detected in close to actual time with a skilled machine studying mannequin.
Finish to Finish Delta Dwell Tables pipeline as seen within the DLT Person Interface
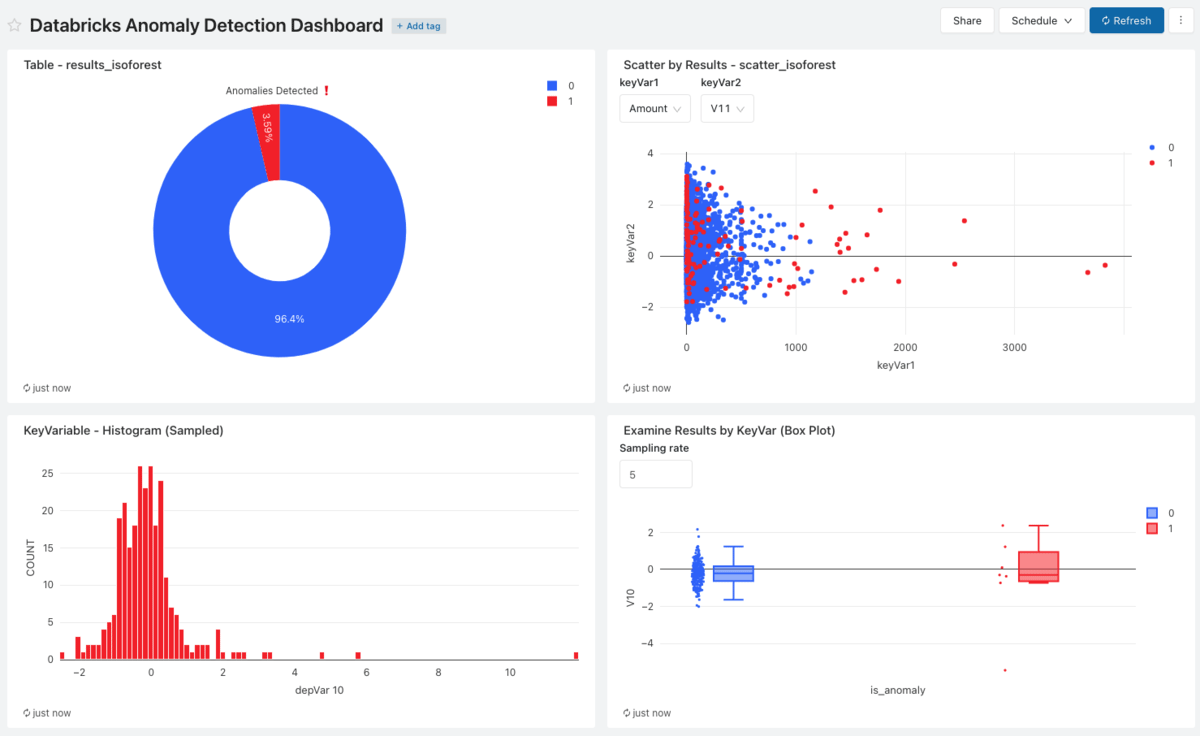
Whereas this pipeline is executing, Databricks SQL can be utilized to visualise the anomalous information thus recognized, with steady updates enabled by the Databricks SQL Dashboard refresh performance. Such a dashboard constructed with visualized primarily based on queries executed in opposition to the ‘Predictions’ desk might be seen beneath.
Databricks SQL Dashboard constructed to interactively show predicted anomalous information
In abstract, this weblog particulars the capabilities out there within the Databricks Machine Studying and Workflows used to coach an isolation forest algorithm for anomaly detection and the method of defining a Delta Dwell Desk pipeline which is able to performing this feat in a close to real-time method. Delta Dwell Tables abstracts the complexity of the method from the tip person and automates it.
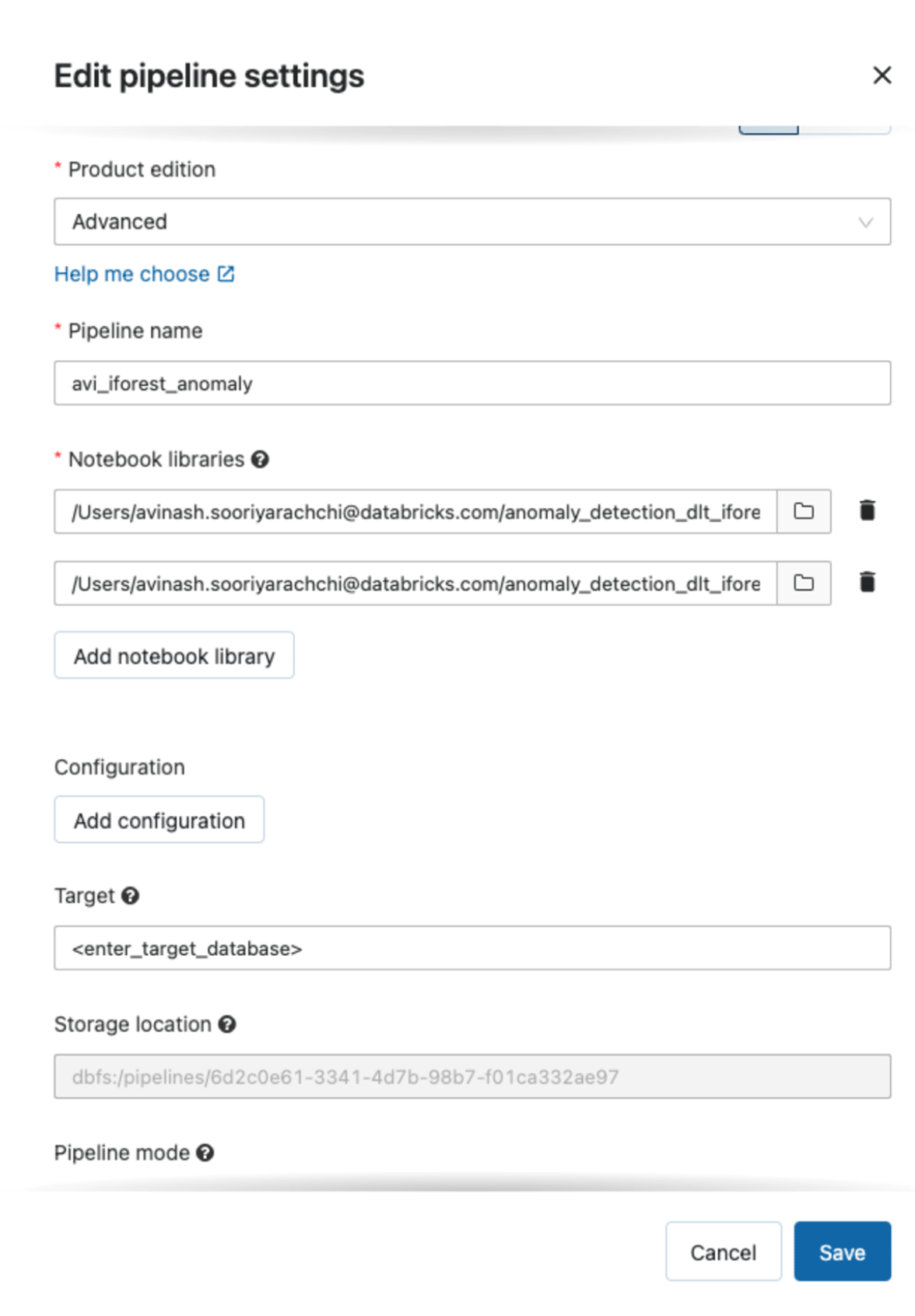
A Delta Dwell Tables pipeline might be created utilizing the Databricks Workflows person interface
To carry out anomaly detection in a close to actual time method, a DLT pipeline needs to be executed in Steady Mode. The method described within the official quickstart (https://docs.databricks.com/data-engineering/delta-live-tables/delta-live-tables-quickstart.html ) might be adopted to create, with the beforehand described Python and SQL notebooks which can be found within the repository for this weblog. Different configurations might be crammed in as desired.
In use instances the place intermittent pipeline runs are acceptable, for instance, anomaly detection on information collected by a supply system in batch, the pipeline might be executed in Triggered mode, with intervals as little as 10 minutes. Then a schedule might be specified for this triggered pipeline to run and in every execution, the info shall be processed via the pipeline in an incremental method.
Subsequently, the pipeline configuration with cluster autoscaling enabled (to deal with various load of information being handed via the pipeline with out processing bottlenecks) might be saved and the pipeline began. Alternatively, all these configurations might be neatly described in JSON format and entered in the identical enter type.
Delta Dwell Tables figures out cluster configurations, underlying desk optimizations and various different essential particulars for the tip person. For working the pipeline, Growth mode might be chosen, which is conducive for iterative growth or Manufacturing mode, which is geared in the direction of manufacturing. Within the latter, DLT routinely performs retries and cluster restarts.
It is very important emphasize that each one that’s described above might be performed by way of the Delta Dwell Tables REST API. That is notably helpful for manufacturing situations the place the DLT pipeline executing in steady mode might be edited on the fly with no downtime, for instance every time the isolation forest is retrained by way of a scheduled job as talked about earlier on this weblog.
Configurations for the Delta Dwell Tables pipelines on this instance. Enter a goal database title to retailer the Delta tables created
Please ensure that to make use of clusters with the Databricks Machine Studying runtime for mannequin coaching duties. Though the instance given right here is fairly simplistic, the identical rules maintain for extra difficult transformations and Delta Dwell Tables was constructed to scale back the complexity inherent in constructing such pipelines. We welcome you to adapt the concepts on this weblog to your use case.




{kind=link}