

Azure empowers clever companies like Microsoft Copilot, Bing, and Azure OpenAI Service which have captured our creativeness in current days. These companies, facilitating varied functions like Microsoft Workplace 365, chatbots, and serps with generative AI, owe their magic to giant language fashions (LLMs). Whereas the most recent LLMs are transcendental, bringing a generational change in how we apply synthetic intelligence in our each day lives and motive about its evolution, we’ve got merely scratched the floor. Creating extra succesful, honest, foundational LLMs that devour and current info extra precisely is important.
How Microsoft maximizes the facility of LLMs
Nonetheless, creating new LLMs or bettering the accuracy of current ones is not any straightforward feat. To create and prepare improved variations of LLMs, supercomputers with huge computational capabilities are required. It’s paramount that each the {hardware} and software program in these supercomputers are utilized effectively at scale, not leaving efficiency on the desk. That is the place the sheer scale of the supercomputing infrastructure in Azure cloud shines and setting a brand new scale report in LLM coaching issues.
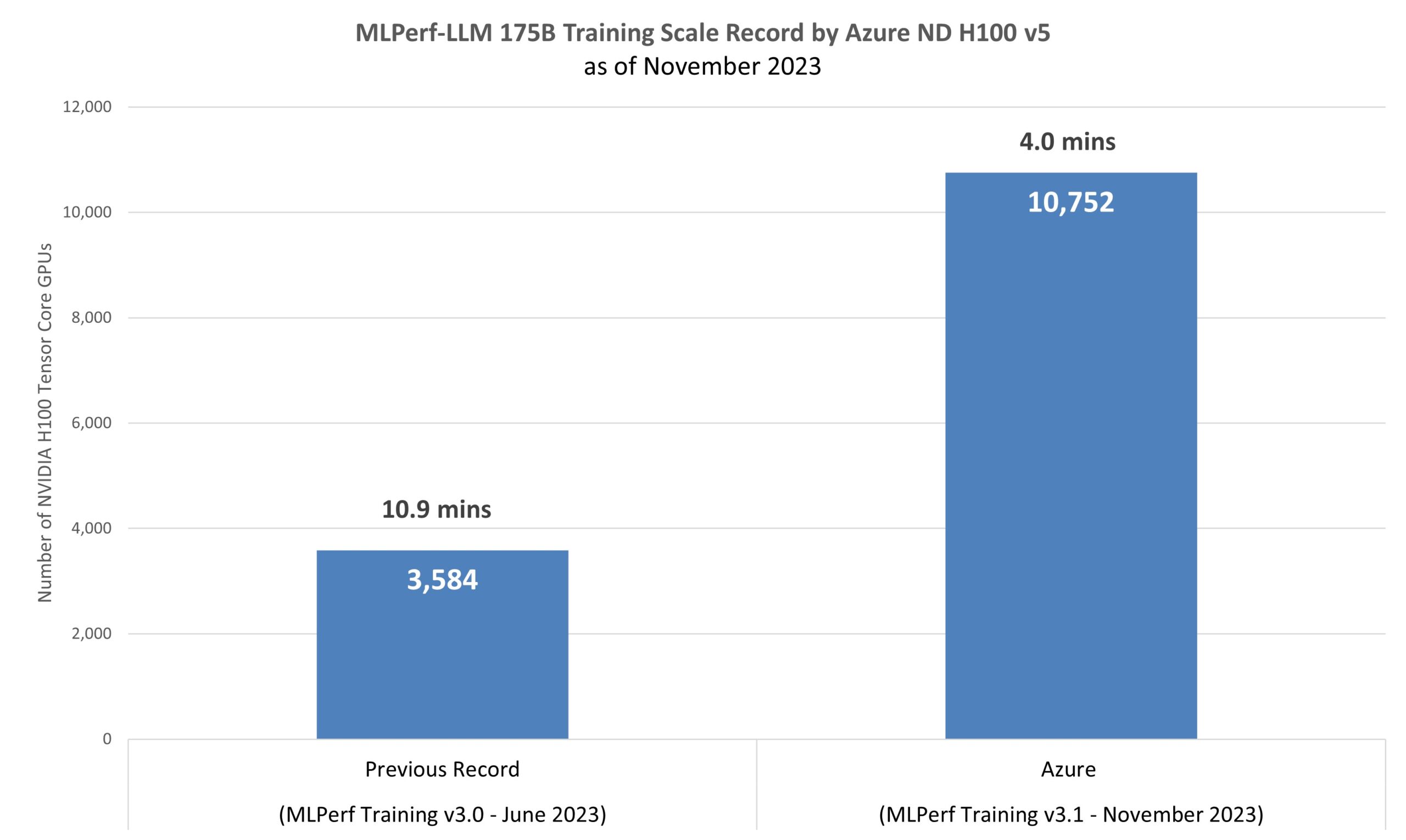
Prospects want dependable and performant infrastructure to deliver probably the most refined AI use instances to market in report time. Our goal is to construct state-of-the-art infrastructure and meet these calls for. The newest MLPerf™ 3.1 Coaching outcomes1 are a testomony to our unwavering dedication to constructing high-quality and high-performance programs within the cloud to attain unparalleled effectivity in coaching LLMs at scale. The thought right here is to make use of huge workloads to emphasize each part of the system and speed up our construct course of to attain top quality.
The GPT-3 LLM mannequin and its 175 billion parameters have been educated to completion in 4 minutes on 1,344 ND H100 v5 digital machines (VMs), which characterize 10,752 NVIDIA H100 Tensor Core GPUs, linked by the NVIDIA Quantum-2 InfiniBand networking platform (as proven in Determine 1). This coaching workload makes use of near real-world datasets and restarts from 2.4 terabytes of checkpoints performing intently a manufacturing LLM coaching situation. The workload stresses the H100 GPUs Tensor Cores, direct-attached Non-Risky Reminiscence Specific disks, and the NVLink interconnect that gives quick communication to the high-bandwidth reminiscence within the GPUs and cross-node 400Gb/s InfiniBand material.
“Azure’s submission, the most important within the historical past of MLPerf Coaching, demonstrates the extraordinary progress we’ve got made in optimizing the dimensions of coaching. MLCommons’ benchmarks showcase the prowess of recent AI infrastructure and software program, underlining the continual developments which were achieved, finally propelling us towards much more highly effective and environment friendly AI programs.”—David Kanter, Government Director of MLCommons
Microsoft’s commitment to efficiency
In March 2023, Microsoft launched the ND H100 v5-series which accomplished coaching a 350 million parameter Bidirectional Encoder Representations from Transformers (BERT) language mannequin in 5.4 minutes, beating our current report. This resulted in a 4 occasions enchancment in time to coach BERT inside simply 18 months, highlighting our steady endeavor to deliver one of the best efficiency to our customers.
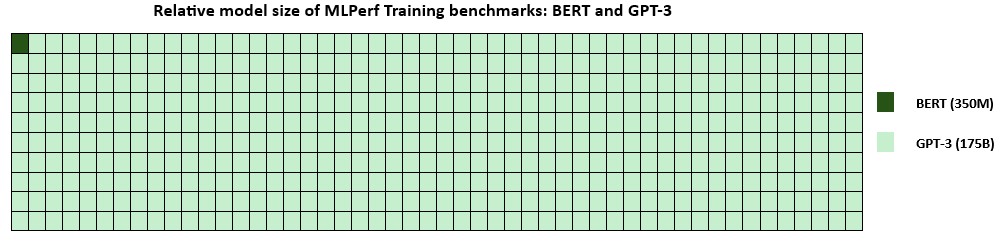
At present’s outcomes are with GPT-3, a big language mannequin within the MLPerf Coaching benchmarking suite, that includes 175 billion parameters, a exceptional 500 occasions bigger than the beforehand benchmarked BERT mannequin (determine 2). The newest coaching time from Azure reached a 2.7x enchancment in comparison with the earlier report from MLPerf Coaching v3.0. The v3.1 submission underscores the power to lower coaching time and price by optimizing a mannequin that precisely represents present AI workloads.
The facility of virtualization
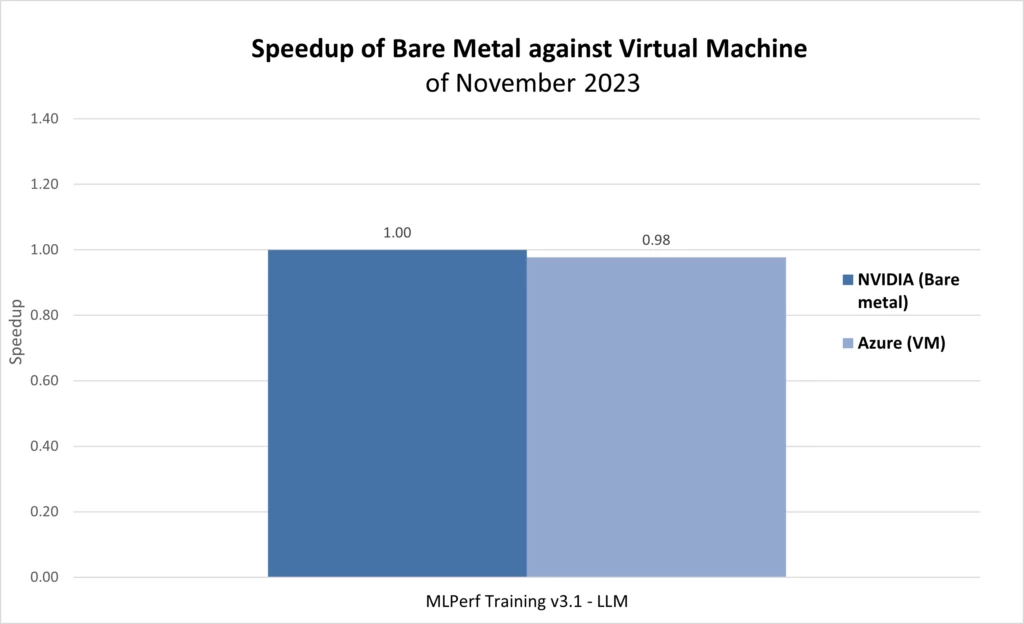
NVIDIA’s submission to the MLPerf Coaching v3.1 LLM benchmark on 10,752 NVIDIA H100 Tensor Core GPUs achieved a coaching time of three.92 minutes. This quantities to only a 2 % improve within the coaching time in Azure VMs in comparison with the NVIDIA bare-metal submission, which has the best-in-class efficiency of digital machines throughout all choices of HPC situations within the cloud (determine 3).
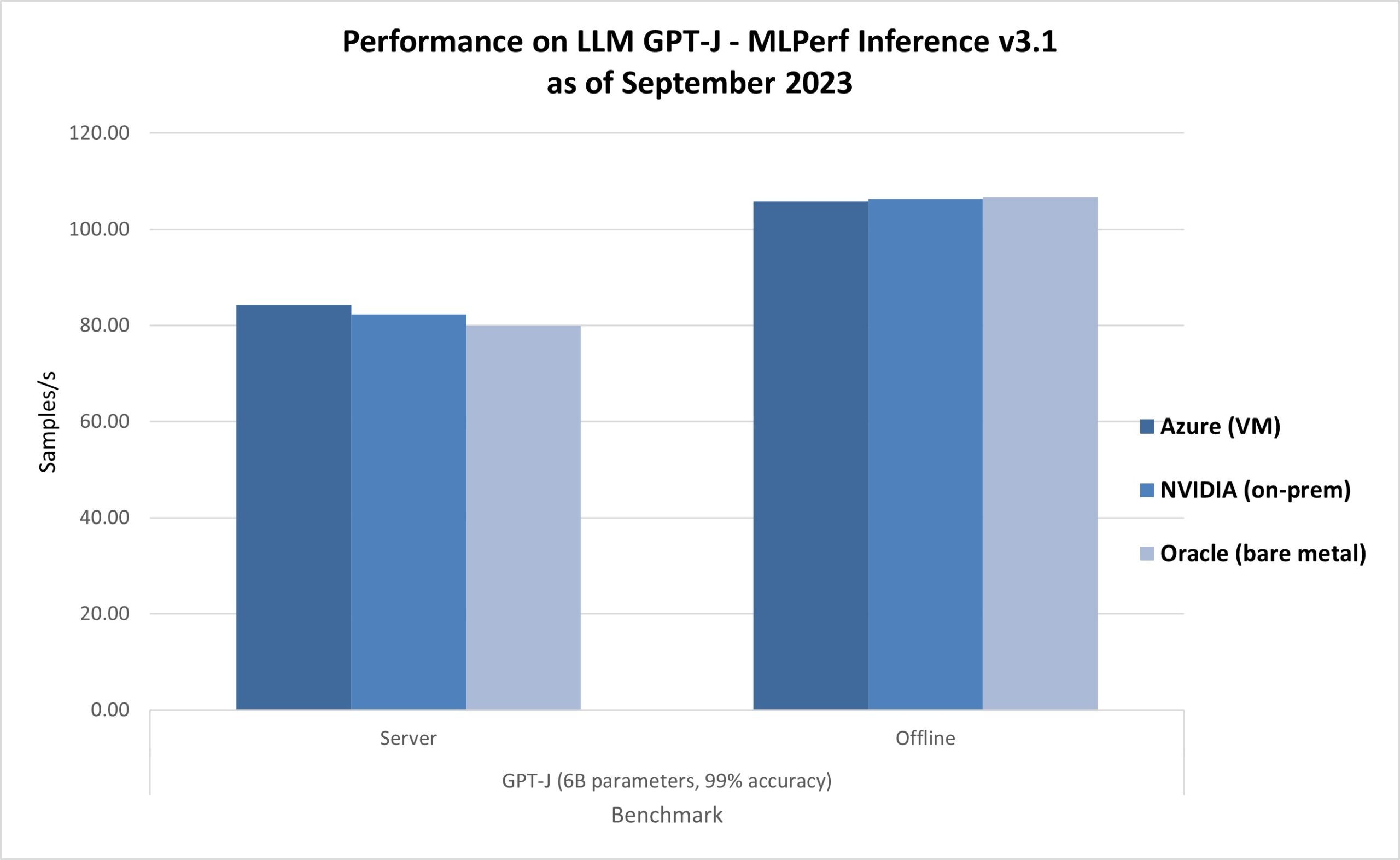
The newest ends in AI Inferencing on Azure ND H100 v5 VMs present management outcomes as nicely, as proven in MLPerf Inference v3.1. The ND H100 v5-series delivered 0.99x-1.05x relative efficiency in comparison with the bare-metal submissions on the identical NVIDIA H100 Tensor Core GPUs (determine 4), echoing the effectivity of digital machines.
In conclusion, created for efficiency, scalability, and flexibility, the Azure ND H100 v5-series gives distinctive throughput and minimal latency for each coaching and inferencing duties within the cloud and gives the very best high quality infrastructure for AI.
Be taught extra about Azure AI Infrastructure
References
- MLCommons® is an open engineering consortium of AI leaders from academia, analysis labs, and business. They construct honest and helpful benchmarks that present unbiased evaluations of coaching and inference efficiency for {hardware}, software program, and companies—all performed beneath prescribed situations. MLPerf™ Coaching benchmarks include real-world compute-intensive AI workloads to finest simulate buyer’s wants. Checks are clear and goal, so expertise decision-makers can depend on the outcomes to make knowledgeable shopping for choices.

{kind=link}