

Amazon Kinesis Information Analytics is the best technique to remodel and analyze streaming information in actual time utilizing Apache Flink. Prospects are already utilizing Kinesis Information Analytics to carry out real-time analytics on fast-moving information generated from information sources like IoT sensors, change information seize (CDC) occasions, gaming, social media, and lots of others. Apache Flink is a well-liked open-source framework and distributed processing engine for stateful computations over unbounded and bounded information streams.
Though constructing Apache Flink functions is usually the accountability of a knowledge engineering crew, automating the deployment and provisioning infrastructure as code (IaC) is often owned by the platform (or DevOps) crew.
The next are typical obligations of the info engineering position:
- Write code for real-time analytics Apache Flink functions
- Roll out new software variations or roll them again (for instance, within the case of a important bug)
The next are typical obligations of the platform position:
- Write code for IaC
- Provision the required assets within the cloud and handle their entry
On this put up, we present how one can automate deployment and model updates for Kinesis Information Analytics functions and permit each Platform and engineering groups to successfully collaborate and co-own the ultimate resolution utilizing AWS CodePipeline with the AWS Cloud Improvement Package (AWS CDK).
Resolution overview
To display the automated deployment and model replace of a Kinesis Information Analytics software, we use the next instance real-time information analytics structure for this put up.

The workflow contains the next steps:
- An AWS Lambda perform (performing as information supply) is the occasion producer pushing occasions on demand to Amazon Kinesis Information Streams when invoked.
- The Kinesis information stream receives and shops real-time occasions.
- The Kinesis Information Analytics software reads occasions from the info stream and performs real-time analytics on it.
Generic structure
You’ll be able to discuss with the next generic structure to adapt this instance to your most popular CI/CD software (for instance, Jenkins). The general deployment course of is split into three high-level elements:
- Infrastructure CI/CD – This portion is highlighted in orange. The infrastructure CI/CD pipeline is liable for deploying all of the real-time streaming structure parts, together with the Kinesis Information Analytics software and any linked assets sometimes deployed utilizing AWS CloudFormation.
- ApplicationStack – This portion is highlighted in grey. The applying stack is deployed by the infrastructure CI/CD element utilizing AWS CloudFormation.
- Utility CI/CD – This portion is highlighted in inexperienced. The applying CI/CD pipeline updates the Kinesis Information Analytics software in three steps:
- The pipeline builds the Java or Python supply code of the Kinesis Information Analytics software and produces the appliance as a binary file.
- The pipeline pushes the most recent binary file to the Amazon Easy Storage Service (Amazon S3) artifact bucket after a profitable construct as Kinesis Information Analytics software binary recordsdata are referenced from S3.
- The S3 bucket file put occasion triggers a Lambda perform, which updates the model of the Kinesis Information Analytics software by deploying the most recent binary.
The next diagram illustrates this workflow.

CI/CD structure with CodePipeline
On this put up, we implement the generic structure utilizing CodePipeline. The next diagram illustrates our up to date structure.
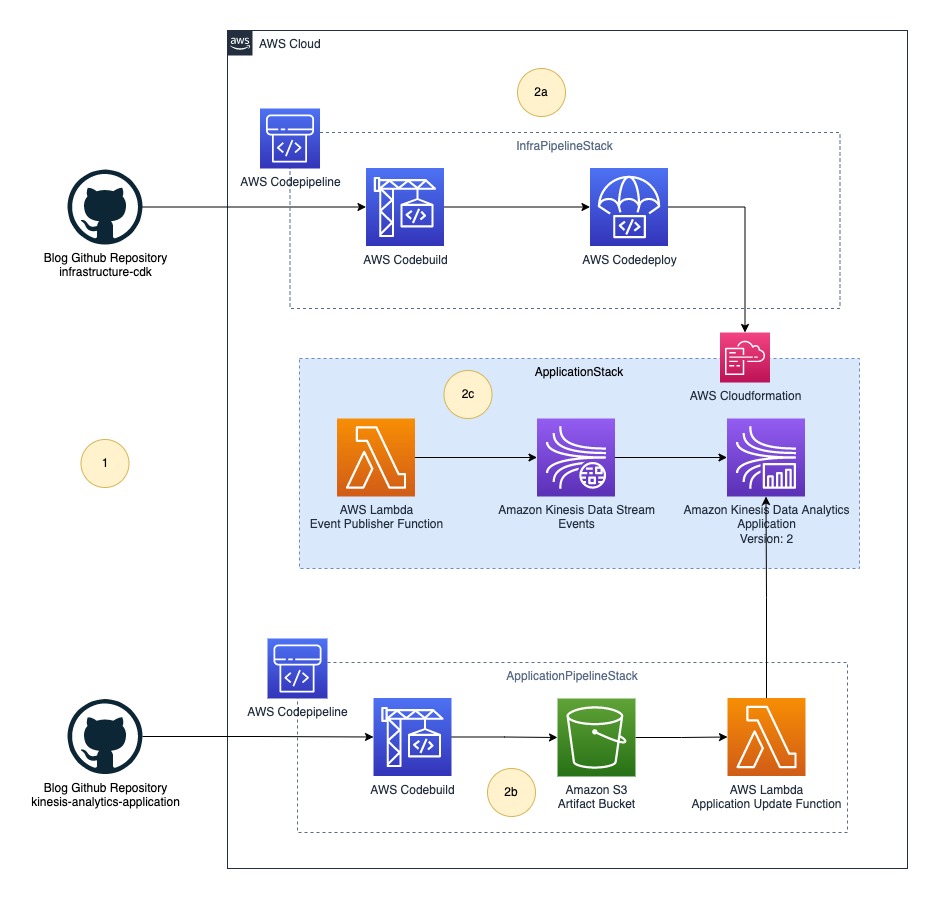
The ultimate resolution contains the next steps:
- The platform (DevOps) crew and information engineering crew push their supply code to their respective code repositories.
- CodePipeline deploys the entire infrastructure as three stacks:
- InfraPipelineStack – Comprises a pipeline to deploy the general infrastructure.
- ApplicationPipelineStack – Comprises a pipeline to construct and deploy Kinesis Information Analytics software binaries. On this put up, we construct a Java supply utilizing the JavaBuildPipeline AWS CDK assemble. You should use the PythonBuildPipeline AWS CDK assemble to construct a Python supply.
- ApplicationStack – Comprises real-time information analytics pipeline assets together with Lambda (information supply), Kinesis Information Streams (storage), and Kinesis Information Analytics (Apache Flink software).
Deploy assets utilizing AWS CDK
The next GitHub repository accommodates the AWS CDK code to create all the mandatory assets for the info pipeline. This removes alternatives for guide error, will increase effectivity, and ensures constant configurations over time. To deploy the assets, full the next steps:
- Clone the GitHub repository to your native pc utilizing the next command:
- Obtain and set up the most recent Node.js.
- Run the next command to put in the most recent model of AWS CDK:
- Run
cdk bootstrapto initialize the AWS CDK atmosphere in your AWS account. Substitute your AWS account ID and Area earlier than operating the next command.
To be taught extra concerning the bootstrapping course of, discuss with Bootstrapping.
Half 1: Information engineering and platform groups push supply code to their code repositories
The info engineering and platform groups start work of their respective code repositories, as illustrated within the following determine.
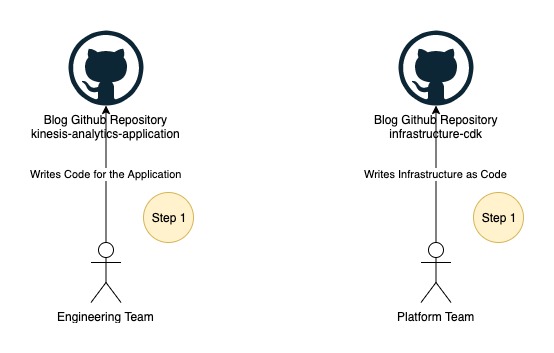
On this put up, we use two folders as an alternative of two GitHub repositories, which you’ll find beneath the foundation folder of the cloned repository:
- kinesis-analytics-application – This folder accommodates instance supply code of the Kinesis Information Analytics software. This represents your Kinesis Information Analytics software supply code developed by your information engineering crew.
- infrastructure-cdk – This folder accommodates instance AWS CDK supply code of the ultimate resolution used for provisioning all of the required assets and CodePipeline. You’ll be able to reuse this code on your Kinesis Information Analytics software deployment.
Utility growth groups often shops the appliance supply code in git repositories. For the demonstration goal, we’ll use supply code as zip file downloaded from Github as an alternative of connecting CodePipeline to the Github repository. Chances are you’ll wish to instantly join supply repository with CodePipeline. To be taught extra about join, discuss with Create a connection to GitHub.
Half 2: The platform crew deploys the appliance pipeline
The next determine illustrates the following step within the workflow.

On this step, you deploy the primary pipeline to construct the Java supply code from kinesis-analytics-application. Full the next steps to deploy ApplicationPipelineStack:
- Open your terminal, bash, or command window relying in your OS.
- Swap the present path to the folder
infrastructure-cdk. - Run
npm set upto obtain all dependencies. - Run
cdk deploy ApplicationPipelineStackto deploy the appliance pipeline.
This course of ought to take about 5 minutes to finish and deploys the next assets to your AWS account, highlighted in inexperienced within the previous diagram:
- CodePipeline, containing phases for AWS CodeBuild and AWS CodeDeploy
- An S3 bucket to retailer binaries
- A Lambda perform to replace the Kinesis Information Analytics software JAR after guide approval
Set off an computerized construct for the appliance pipeline
After the cdk deploy command is profitable, full the next steps to routinely run the pipeline:
- Obtain the supply code .zip file.
- On the AWS CloudFormation console, select Stacks within the navigation pane.
- Select the stack
ApplicationPipelineStack.
- On the Outputs tab, select the hyperlink for the important thing
ArtifactBucketLink.
You’re redirected to the S3 artifact bucket.
- Select Add.
- Add the supply code .zip file you downloaded.
The primary pipeline run (proven as Auto Construct within the following diagram) begins routinely and takes about 5 minutes to achieve the guide approval stage. The pipeline routinely downloads the supply code from the artifact bucket, builds the Java venture kinesis-analytics-application utilizing Maven, and publishes the output binary JAR file again to the artifact bucket beneath the listing jars.

View the appliance pipeline run
Full the next steps to view the appliance pipeline run:
- On the AWS CloudFormation console, navigate to the stack
ApplicationPipelineStack. - On the Outputs tab, select the hyperlink for the important thing
ApplicationCodePipelineLink.
You’re redirected to the pipeline particulars web page. You’ll be able to see an in depth view of the pipeline, together with the state of every motion in every stage and the state of the transitions.
Don’t approve the construct for the guide approval stage but; that is completed later.
Half 3: The platform crew deploys the infrastructure pipeline
The applying pipeline run publishes a JAR file named kinesis-analytics-application-final.jar to the artifact bucket. Subsequent, we deploy the Kinesis Information Analytics structure. Full the next steps to deploy the instance move:
- Open a terminal, bash, or command window relying in your OS.
- Swap the present path to the folder
infrastructure-cdk. - Run
cdk deploy InfraPipelineStackto deploy the infrastructure pipeline.
This course of ought to take about 5 minutes to finish and deploys a pipeline containing phases for CodeBuild and CodeDeploy to your AWS account, as highlighted in inexperienced within the following diagram.

When the cdk deploy is full, the infrastructure pipeline run begins routinely (proven as Auto Construct 1 within the following diagram) and takes about 10 minutes to obtain the supply code from the artifact bucket, construct the AWS CDK venture infrastructure-stack, and deploy ApplicationStack routinely to your AWS account. When the infrastructure pipeline run is full, the next assets are deployed to your account (proven in inexperienced in following diagram):
- A CloudFormation template named
app-ApplicationStack - A Lambda perform performing as a knowledge supply
- A Kinesis information stream performing because the stream storage
- A Kinesis Information Analytics software with the primary model of
kinesis-analytics-application-final.jar
View the infrastructure pipeline run
Full the next steps to view the appliance pipeline run:
- On the AWS CloudFormation console, navigate to the stack
InfraPipelineStack.
- On the Outputs tab, select the hyperlink for the important thing
InfraCodePipelineLink.
You’re redirected to the pipeline particulars web page. You’ll be able to see an in depth view of the pipeline, together with the state of every motion in every stage and the state of the transitions.
Step 4: The info engineering crew deploys the appliance
Now your account has all the things in place for the info engineering crew to work independently and roll out new variations of the Kinesis Information Analytics software. You’ll be able to approve the respective software construct from the appliance pipeline to deploy new variations of the appliance. The next diagram illustrates the complete workflow.

The construct course of begins routinely when it detects adjustments within the supply code. You’ll be able to check a model replace by re-uploading the supply code .zip file to the S3 artifact bucket. In a real-world use case, you replace the primary department both through a pull request or by merging your adjustments, and this motion triggers a brand new pipeline run routinely.
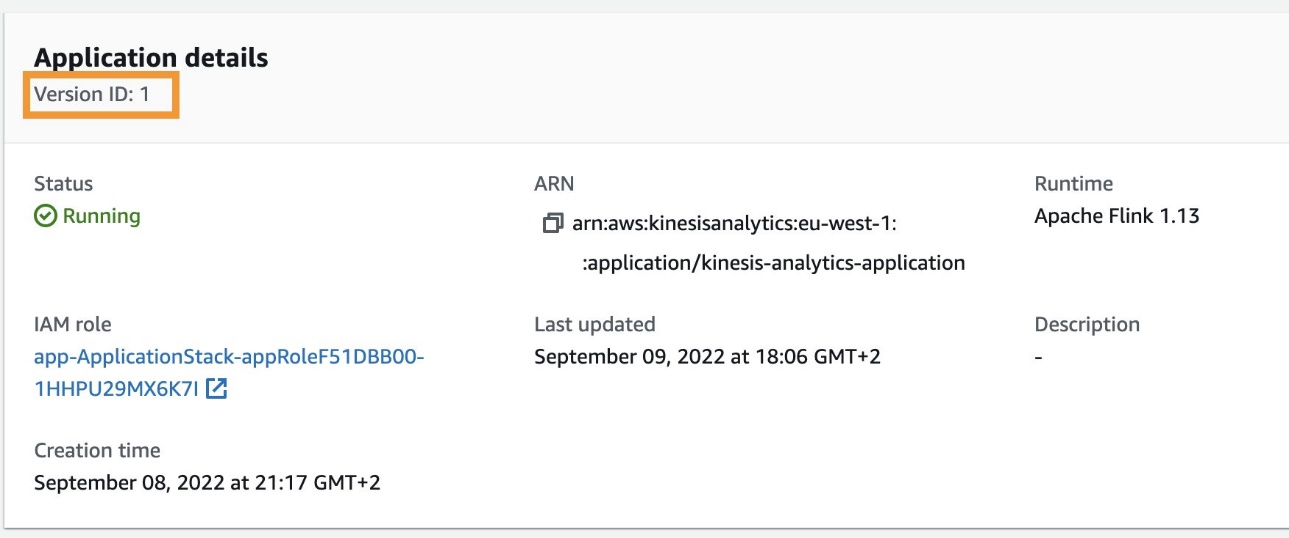
View the present software model
To view the present model of the Kinesis Information Analytics software, full the next steps:
- On the AWS CloudFormation console, navigate to the stack
InfraPipelineStack. - On the Outputs tab, select the hyperlink for the important thing
KDAApplicationLink.
You’re redirected to the Kinesis Information Analytics software particulars web page. You will discover the present software model by Model ID.
Approve the appliance deployment
Full the next steps to approve the deployment (or model replace) of the Kinesis Information Analytics software:
- On the AWS CloudFormation console, navigate to the stack
ApplicationPipelineStack. - On the Outputs tab, select the hyperlink for the important thing
ApplicationCodePipelineLink. - Select Evaluate from the pipeline approval stage.

- When prompted, select Approve to offer approval (optionally including any feedback) for the Kinesis Information Analytics software deployment or model replace.

- Repeat the steps talked about earlier to view the present software model.
It’s best to see the appliance model as outlined in Model ID elevated by one, as proven within the following screenshot.

Deploying a brand new model of the Kinesis Information Analytics software will trigger a downtime of round 5 minutes as a result of the Lambda perform liable for the model replace makes the API name UpdateApplication, which restarts the appliance after updating the model. Nevertheless, the appliance resumes stream processing the place it left off after the restart.
Clear up
Full the next steps to delete your assets and cease incurring prices:
- On the AWS CloudFormation console, choose the stack
InfraPipelineStackand select Delete. - Choose the stack
app-ApplicationStackand select Delete. - Choose stack
ApplicationPipelineStackand select Delete. - On the Amazon S3 console, choose the bucket with the identify beginning with
javaappCodePipelineand select Empty. - Enter completely delete to substantiate the selection.
- Choose the bucket once more and select Delete.
- Affirm the motion by coming into the bucket identify when prompted.
- Repeat these steps to delete the bucket with the identify beginning with
infrapipelinestack-pipelineartifactsbucket.
Abstract
This put up demonstrated automate deployment and model updates on your Kinesis Information Analytics functions utilizing CodePipeline and AWS CDK.
For extra data, see Steady integration and supply (CI/CD) utilizing CDK Pipelines and CodePipeline tutorials.
Concerning the Writer
 Anand Shah is a Large Information Prototyping Options Architect at AWS. He works with AWS prospects and their engineering groups to construct prototypes utilizing AWS analytics companies and purpose-built databases. Anand helps prospects resolve probably the most difficult issues utilizing the artwork of the doable expertise. He enjoys seashores in his leisure time.
Anand Shah is a Large Information Prototyping Options Architect at AWS. He works with AWS prospects and their engineering groups to construct prototypes utilizing AWS analytics companies and purpose-built databases. Anand helps prospects resolve probably the most difficult issues utilizing the artwork of the doable expertise. He enjoys seashores in his leisure time.

{kind=link}