

In the present day, we’re excited to announce the final availability of Predictive I/O for Databricks SQL (DB SQL): a machine studying powered function to make your level lookups sooner and cheaper. Predictive I/O leverages the years of expertise Databricks has in constructing giant AI/ML programs to make the Lakehouse the neatest information warehouse with no further indexes and no costly background providers. Actually, for level lookups, Predictive I/O offers you all the advantages of indexes and optimization providers, however with out the complexity and price of sustaining them. Predictive I/O is on by default in DB SQL Professional and Serverless and works with no added value.
What are level lookups and why are they so costly?
A selective question or a degree lookup, seeks to return a small or single end result from a big dataset, frequent in BI and Analytics use instances. Generally known as a “needle-in-the-haystack” question, making these queries quick whereas retaining prices low is difficult.
It is onerous as a result of with the intention to make your level lookups quick on a cloud information warehouse (CDW), you will should create an index or use an extra optimization service. Additional, these choices are knobs, which means that every method requires understanding how and when to make use of, earlier than enabling.
Indexes are time-consuming and costly as a result of:
- You should work out which column(s) to index on
- You must keep the index, deciding when to rebuild and paying for every rebuild
- You should suppose this course of for every desk, for every use case
- You must beware write amplification
- If the utilization sample modifications, you have to to rebuild the index
Optimization providers are costly as a result of:
- You should decide which tables you want to allow it on
- You should pay for operating the service within the background because the desk modifications
- You should suppose by way of this course of for every desk
In abstract, CDW’s indexes and optimization providers for level lookups are costly. Given all of the concerns required, these choices are advanced knobs that take money and time to tune. There must be a greater manner.
The Advantages of Predictive I/O
Now think about this… What if you did not have to make a duplicate of the information? What if there was no want for costly indexes or search optimization providers? What if the system might study which information is required to your queries and anticipate what you will want subsequent? What in case your queries had been merely quick with out knobs?
What if Databricks can cease the endless loop of DBA grief and substitute it with an clever system that lets you get again to simplicity? That is the place Predictive I/O enters the chat. Let us take a look at two examples of Predictive I/O efficiency out-of-the-box.
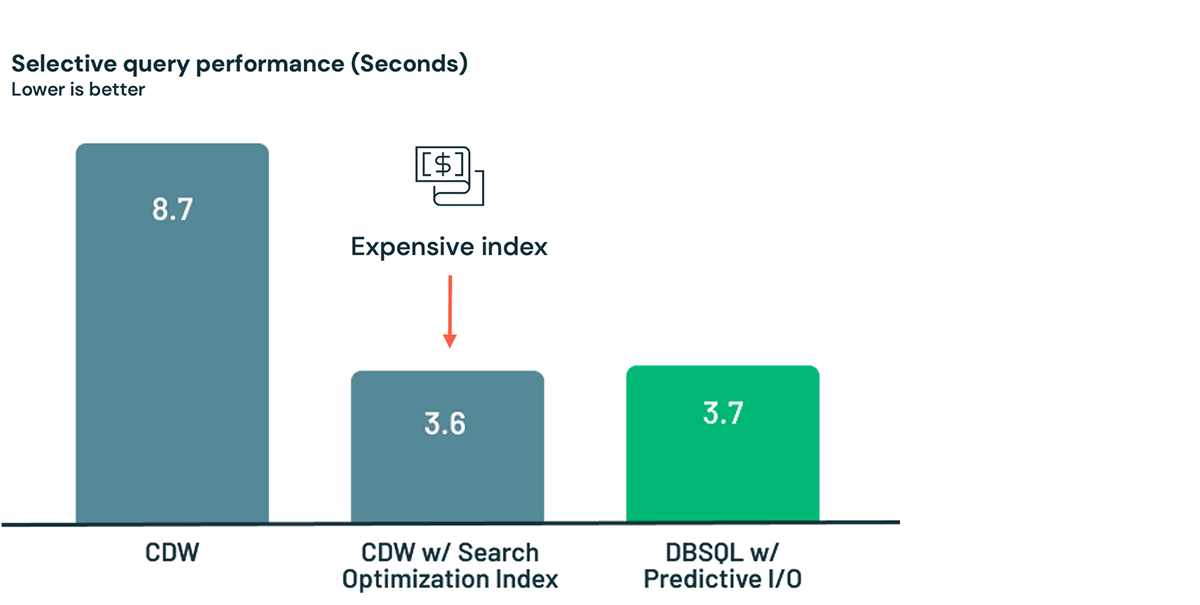
First, let’s examine Databricks SQL Serverless efficiency towards a Cloud Knowledge Warehouse (CDW) for a degree lookup. Within the case beneath, after loading a dataset into the CDW, it takes 8.7 seconds to question. If that is not quick sufficient for you, you should utilize an costly optimization service and get the time down to three.6 seconds. However keep in mind: you are paying for this. Each time your desk modifications, the optimization service should run upkeep operations. Or, as a a lot simpler and cheaper different, simply load and question your information within the Lakehouse in 3.7 seconds due to Predictive I/O!
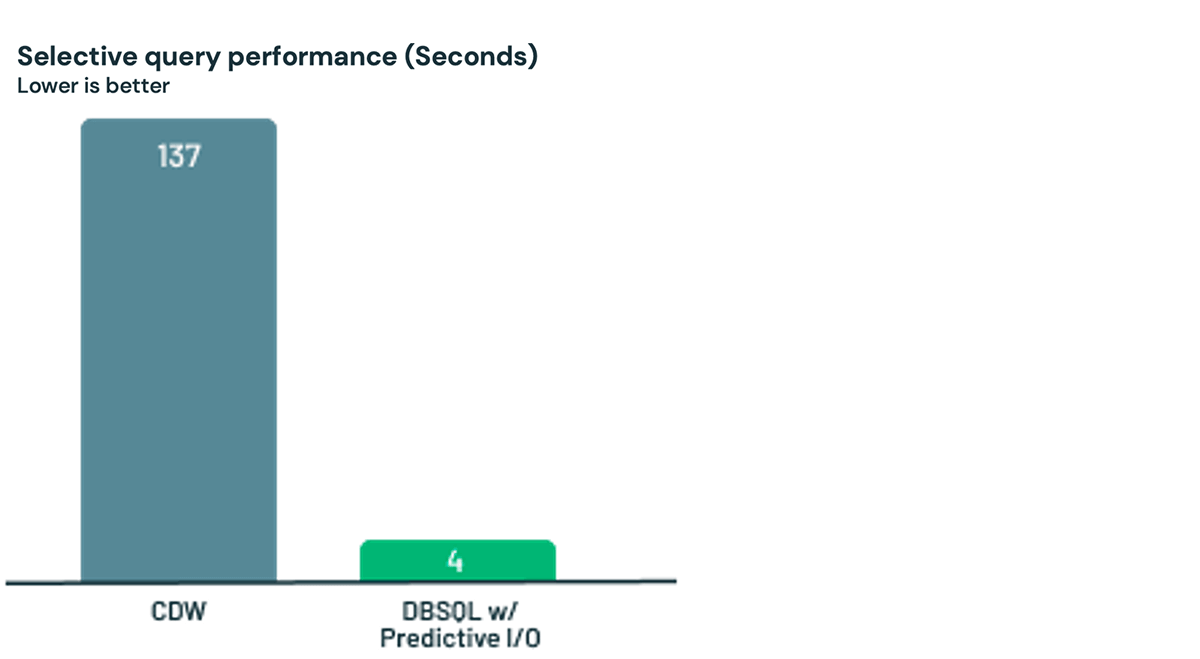
Subsequent, let’s take a look at an actual world workload from an early buyer of Predictive I/O. The method was easy – load the information into Databricks after which run a selective question. Predictive I/O was 35x sooner than the CDW for this buyer’s use case. Once more, no knobs wanted for nice efficiency.
That sounds nice! However how does Predictive I/O work?
For Delta Lake and Parquet tables, Predictive I/O makes use of varied types of machine studying and machine intelligence equivalent to heuristics, modeling, and predicting scan efficiency based mostly on file properties to allow and disable varied optimizations intelligently. The general purpose was easy: speed up the efficiency of selective queries and save our clients money and time.
Utilizing the traits of the question, we resolve what number of assets must be allotted with the intention to optimally execute the question.
What’s subsequent?
Predictive I/O represents a efficiency enchancment milestone for our clients. Given how frequent selective queries are in analytics, we’re excited to maintain innovating on this area. Keep tuned (no pun meant) for the following wave of efficiency options coming quickly, guaranteeing our clients proceed to have best-in-class price-performance and making the Lakehouse the very best information warehouse.
If you happen to’re an present buyer, you will get began with Predictive I/O at present. Merely setup a Databricks SQL Serverless warehouse for the very best expertise, and simply begin querying your information.

{kind=link}