


(Warm_Tail/Shutterstock)
Firms that discover themselves unable to get solutions out of conventional analytical databases rapidly sufficient to fulfill their efficiency necessities could need to try an rising class of real-time analytical databases. As one of many main members of this new class, Apache Druid is discovering followers among the many most subtle shoppers, together with Salesforce and Confluent.
Cloud information warehouses like Google Massive Question, Snowflake, and Amazon Redshift have remodeled the economics of huge information storage and ushered in a brand new period of superior analytics. Firms all over the world that couldn’t afford to construct their very own scale-out, column-oriented analytical databases, or who simply didn’t need the effort, might lease entry to a giant cloud information warehouse with virtually limitless scalability.
However as transformational as these cloud information warehouses, information lakes, and information lakehouses have been, they nonetheless can not ship the SQL question efficiency demanded by a number of the largest corporations on the planet.
In case your requirement consists of analyzing petabytes’ price of real-time occasion information mixed with historic information, getting the reply again in lower than a second, and doing this concurrently 1000’s of occasions per second, you discover that you simply rapidly exceed the technical functionality of the standard information warehouse.
And that’s the place you end up coming into the realm of a brand new class of database. The parents at Suggest, the corporate behind the Apache Druid undertaking, name it a real-time analytics database, however different outfits have totally different names for it.
David Wang, vice chairman of product advertising at Suggest, says Druid sits on the intersection of analytics and purposes.![]()
“Analytics all the time represented large-scale aggregations and group-bys and large filtered queries, however purposes all the time represented a workload meaning excessive concurrency on operational information. It needs to be actually, actually quick and interactive,” he says. “There may be this intersection level on the Venn diagram that, once you’re attempting to do actual analytics, however do it on the velocity, the concurrency, and the operational nature of occasions, you then’ve acquired to have one thing that’s function constructed for that intersection. And I feel that’s the place this class has emerged.”
Druid’s Deepest, Darkest Secrets and techniques
Apache Druid was initially created in 2011 by 4 engineers at Metamarkets, a developer of programmatic promoting options, to energy advanced SQL analytics atop massive quantities of excessive dimensional and excessive cardinality information. One of many Druid co-authors, Fangjin Yang, went on to co-found and function CEO Suggest, and he’s additionally a Datanami Individual to Watch for 2023.
There’s no single secret ingredient in Druid that makes it so quick, Wang says. Slightly, it’s a mix of capabilities developed over years that enable it to do issues that conventional databases simply can’t do.
“It’s about CPU effectivity,” Wang says. “What we do below the covers is we’ve a extremely optimized storage format that leverages this actually distinctive method to how we do segmentation and partitioning, in addition to how we truly retailer the info. It’s not simply columnar storage, however we leverage dictionary encoding, bit-mapped indexing, and different algorithms that enable us to essentially reduce the quantity of rows and quantity of columns that really must be analyzed. That makes a big impact when it comes to efficiency.”
The separation of compute and storage has grow to be customary working process within the cloud, because it allows corporations to scale them independently, which saves cash. The tradeoff in lack of efficiency by separating compute and storage and putting information in object shops is suitable in lots of use circumstances. However for those who’re reaching for the higher reaches of analytics efficiency on large, fast-moving information, that tradeoff is now not possible.
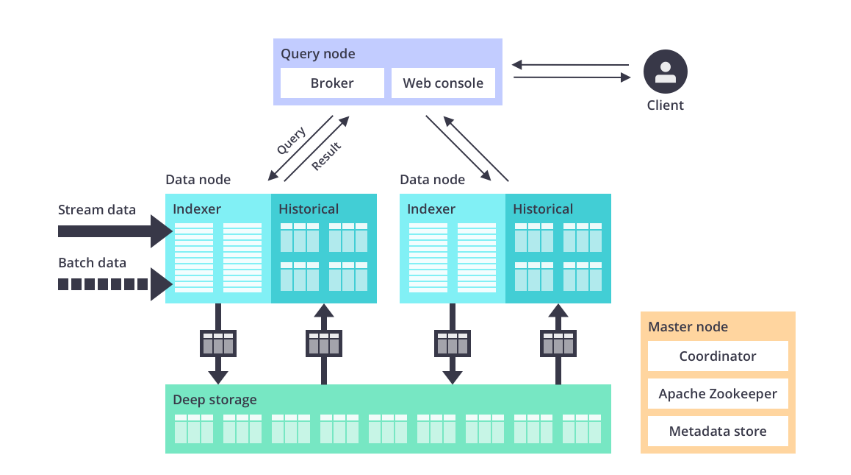
Apache Druid’s structure (Picture supply: Apache Druid)
“You possibly can’t get the sort of [high] efficiency for those who don’t have information structured in a sure approach that drives the effectivity of the processing,” Wang says. “We undoubtedly imagine that, for the actually quick queries, the place you’re actually attempting to drive interactivity, you’ve acquired to do basic items, like don’t transfer information. For those who’re going to have to maneuver information from object storage into you’re the compute nodes at question time you’re getting successful on community latency. That’s simply physics.”
Druid in Motion
The SQL analytic choices from Snowflake, Redshift, and Databricks excel at serving conventional BI experiences and dashboards, Wang says. Druid is serving a special class of person with a special workload.
For instance, Salesforce’s engineering staff is utilizing Druid to energy its edge intelligence system, Wang says. Product managers, website reliability engineers (SREs), and varied improvement groups are utilizing Druid to research totally different facets of the Salesforce cloud, together with efficiency, bugs, and triaging points, he says.
“It’s all ad-hoc. They’re not predefining the queries prematurely of what they’re in search of. It’s not pre-cached. It’s all on-the-fly pivot tables which might be being created off of trillions of rows of knowledge and so they’re getting on the spot responses,” Wang says. “Why is Salesforce doing that? It’s as a result of the dimensions of their occasion information is at a measurement that they want a very quick engine to have the ability to course of it rapidly.”
Even when a conventional information warehouse might ingest the actual time information rapidly sufficient, it couldn’t energy the quantity concurrent queries to help any such use case, Wang says.
“We’re not attempting to combat Snowflake or Databricks or any of those guys, as a result of our workload is simply totally different,” he says. “Snowflake’s most concurrency is eight. Your largest scale-up digital information warehouse can help eight concurrent queries. You possibly can cluster like eight or 10, so that you get 80 QPS [queries per second]. We’ve clients that run POCs which have 1000’s of QPS. It’s a special ball recreation.”

(vecktor/Shutterstock)
‘Spinning Wheel of Demise’
Confluent has an identical requirement to watch its cloud operations. The corporate that employs the foremost consultants within the Apache Kafka message bus chosen Druid to energy an infrastructure observability providing that’s used each internally (by Confluent engineers) in addition to externally (uncovered to Confluent clients).
In response to Wang, their information necessities had been huge. Confluent demanded an analytics database that would ingest 5 million occasions per second and ship subsecond question response time throughout 350 channels concurrently (350 QPS). As a substitute of utilizing their very own product (ksqlDB) or a streaming information system (Confluent just lately acquired an Apache Flink specialist and is growing a Flink providing), they selected Druid.
Confluent, which wrote about its use of Druid, chosen Druid resulting from its means to question each real-time and historic information, Wang says.
“There’s a elementary distinction between a stream processor and an analytic database,” he says. “For those who’re attempting to only do a predefined question on a steady stream, then a stream course of goes to be fairly enough there. However for those who’re attempting to do actual time analytics, taking a look at real-time occasions comparatively with historic information, then it is advisable have a persistent information retailer that helps each actual time information in addition to historic information. That’s why you want an analytics database.”
Momentum is constructing for Druid, Wang says. Greater than 1,400 corporations have put Druid into motion, he says, together with corporations like Netflix, Goal, Cisco’s ThousandEyes, and main banks. Petabyte-scale deployments involving 1000’s of nodes will not be unusual. Suggest itself has been pushing improvement of its cloud-based Druid service, dubbed Polaris, and extra new options are anticipated to be introduced subsequent month.
As consciousness of real-time analytics databases builds, corporations discover Druid is an effective match for each new information analytics tasks, in addition to present tasks that wanted somewhat extra analytics muscle. These roads finally result in Druid and Suggest, Wang says.
“After we’re speaking to builders in regards to the analytic tasks, we requested them, hey, are there any use circumstances the place efficiency and scale matter? The place they tried to construct an analytic software utilizing…a special database and so they hit that scale limitation, the place they hit the spinning wheel of dying as a result of that structure wasn’t designed for these sort of aggregations on the quantity and the concurrency necessities?” he says. “After which we open up a dialog.”
Associated Gadgets:
Suggest Raises $100M Collection D to Make Builders the Heroes of Analytics
Apache Druid Shapeshifts with New Question Engine
Yahoo Casts Actual-Time OLAP Queries with Druid

{kind=link}