


(Blue Andy/Shutterstock)
ChatGPT developer OpenAI is utilizing Ray, an open-source unified compute framework, to ease the infrastructure prices and complexity of coaching its massive language fashions. Anyscale, the corporate behind Ray, has made enhancements and enhancements to the platform’s latest model, Ray 2.2, so as to help the present AI explosion.
With all the joy surrounding ChatGPT and LLMs, it’s straightforward to miss simply how a lot work goes into bringing these seemingly magical fashions into existence. There is not only the information science and machine studying work, but in addition the event work of constructing and working the advanced computing infrastructure required for coaching and deploying these fashions. As proven by the estimated $12 million it value to coach the 175 billion parameter GPT-3 in 2020, the huge period of time and sources wanted to coach and deploy LLMs will be staggering.
Robert Nishihara, CEO and co-founder of Anyscale, agrees: “AI is rising, however the quantity of compute wanted to do AI is off the charts,” he mentioned in an interview with Datanami.
![]() Distributed computing, or a number of computer systems working a number of software program parts as a single system, is one strategy to convey down infrastructure complexity and prices for AI tasks. Ray automates most of the improvement duties that take consideration away from AI and ML work and will increase the efficiency and cost-efficiency of distributed methods. The platform was created by Nishihara and his colleagues at UC Berkeley’s RISELab and is now commercially accessible for enterprise use by Anyscale.
Distributed computing, or a number of computer systems working a number of software program parts as a single system, is one strategy to convey down infrastructure complexity and prices for AI tasks. Ray automates most of the improvement duties that take consideration away from AI and ML work and will increase the efficiency and cost-efficiency of distributed methods. The platform was created by Nishihara and his colleagues at UC Berkeley’s RISELab and is now commercially accessible for enterprise use by Anyscale.
OpenAI makes use of Ray to coach its largest fashions, together with these powering ChatGPT. At Anyscale’s Ray Summit final yr, OpenAI President and Co-founder Greg Brockman shared how Ray turned an integral a part of the coaching of the corporate’s LLMs. In a hearth chat with Nishihara, Brockman defined that OpenAI was in search of higher methods to architect its machine studying methods and went with Ray after exploring a number of choices. “We’re utilizing it to coach our largest fashions. It’s been very useful for us to scale as much as an unprecedented scale,” he mentioned.
Ray distributes the work of coaching an ML mannequin throughout the a number of (in OpenAI’s case, hundreds) CPUs, GPUs, and different {hardware} parts comprising the coaching system. Utilizing the programming language Python, the platform manages every {hardware} element as a single unit, directs knowledge to the place it must go, and troubleshoots failures and bottlenecks.
![]() Time and useful resource prices could make or break AI tasks, and Nishihara says that platforms like Ray can convey AI success inside attain: “The thrilling factor about constructing this platform is you may have customers doing wonderful issues. We predict AI has the potential to essentially rework so many various industries, but it surely’s very onerous to do. Numerous AI tasks fail. Numerous them develop into profitable prototypes however don’t make it to manufacturing,” he mentioned. “The infrastructure and the tooling round AI is among the large causes that it’s onerous. If we may help these corporations transfer sooner to succeed with AI, to get worth out of AI, to do the sorts of issues that Google or OpenAI does, however not should develop into consultants in infrastructure … that’s one thing we’re very enthusiastic about.”
Time and useful resource prices could make or break AI tasks, and Nishihara says that platforms like Ray can convey AI success inside attain: “The thrilling factor about constructing this platform is you may have customers doing wonderful issues. We predict AI has the potential to essentially rework so many various industries, but it surely’s very onerous to do. Numerous AI tasks fail. Numerous them develop into profitable prototypes however don’t make it to manufacturing,” he mentioned. “The infrastructure and the tooling round AI is among the large causes that it’s onerous. If we may help these corporations transfer sooner to succeed with AI, to get worth out of AI, to do the sorts of issues that Google or OpenAI does, however not should develop into consultants in infrastructure … that’s one thing we’re very enthusiastic about.”
Ray was initially designed as a general-purpose system for working Python functions in a distributed method and was not particularly made for ML coaching functions, but it surely has develop into wanted for computationally intensive ML duties. Apart from mannequin coaching, Ray can also be used for mannequin serving, or internet hosting a mannequin and making it accessible by APIs, in addition to batch processing workloads. Anyscale energy customers, like OpenAI, can use the “deep” integration of Ray which entails utilizing Ray APIs or libraries to run functions in a serverless method on the general public cloud. Brockman has discovered Ray to be helpful for developer productiveness on the whole: “Massive mannequin coaching is the place it actually began, however we’ve seen it actually spiral out to different functions, like knowledge processing and scheduling throughout a number of machines, and it’s actually handy to simply run that on high of Ray, and never should assume very onerous,” he mentioned throughout his Ray Summit interview.

These are a number of the accessible integrations for the Ray platform. (Supply: Anyscale)
Certainly one of Ray’s strengths is its potential to combine with machine studying platforms and different improvement frameworks, equivalent to TensorFlow and PyTorch. To that finish, Anyscale not too long ago introduced an integration with Weights & Biases, an MLOps platform specializing in experiment monitoring, dataset versioning, and mannequin administration, that are elements of the machine studying course of that Ray doesn’t particularly handle. Nishihara defined that this integration optimizes the person expertise for patrons of Anyscale and Weights & Biases by growing monitoring capabilities and reproducibility for machine studying tasks.
“While you’re one thing within the Weights & Biases UI, you may click on again to seek out the experiment logs in Anyscale to see what experiments had been run, and you’ll click on a button to breed that experiment. From the Anyscale UI, as you’re doing machine studying coaching, there’s a hyperlink to navigate again to Weights & Biases. The entire info is there to seamlessly use the 2 platforms collectively,” mentioned Nishihara.
Anyscale additionally not too long ago launched Ray 2.2, which it says presents improved developer expertise, efficiency, and stability. The dimension of efficiency is a high precedence for Nishihara: “Efficiency can imply a number of issues—scalability, velocity, value effectivity—all of this stuff are necessary. Main as much as Ray 2.0, a number of our focus was on stability and making it rock stable. Now reliability is in a great spot, and a number of the enhancements we are attempting to make are round efficiency,” he mentioned.
Ray 2.2 options improved dashboards, debugging instruments, and instruments for monitoring reminiscence efficiency. The replace centered on decreasing latency and reminiscence footprint for batch prediction for deep studying fashions by avoiding pointless knowledge conversions. The corporate says Ray 2.2 presents practically 50% improved throughput efficiency and 100x diminished GPU reminiscence footprint for batch inference on image-based workloads.
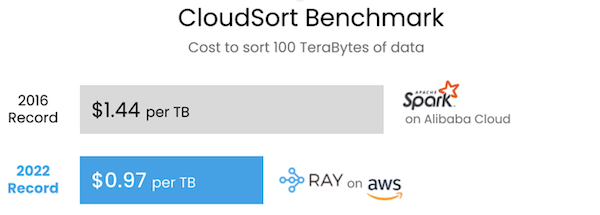
Outcomes of the CloudSort Benchmark. (Supply: Anyscale)
Ray not too long ago helped the Sky Computing Lab at UC Berkeley set a world report on the CloudSort benchmark that broke by the $1/TB barrier, demonstrating the platform’s potential to scale back prices and sources. The lab developed Exoshuffle, a brand new structure for constructing distributed shuffle that’s constructed upon Ray. Shuffling is the method of exchanging knowledge between partitions, and on this benchmark, the workforce was in a position to type 100TB of knowledge on the general public cloud utilizing solely $97 of cloud sources, or $0.97 per terabyte. Anyscale says that is 33% extra cost-efficient than the earlier world report set by Apache Spark in 2016 at $1.44 per terabyte. Spark is specialised for knowledge processing, in contrast to general-purpose Ray, however on this case, the specialised system didn’t outperform the overall system, says Nishihara. He additionally explains how the benchmark additionally confirmed how easy it may be to combine Ray: “As a result of Ray handles all the distributed computing logic for you, the workforce was in a position to implement all of the sorting logic and algorithms as an software on high of Ray. They didn’t want to change Ray in any respect. It was just some hundred traces of code to implement the sorting algorithm on high of Ray.”
Associated Gadgets:
Anyscale Branches Past ML Coaching with Ray 2.0 and AI Runtime
Anyscale Nabs $100M, Unleashes Parallel, Serverless Computing within the Cloud
From Amazon to Uber, Corporations Are Adopting Ray

{kind=link}