

Amazon Redshift is a quick, totally managed cloud knowledge warehouse that makes it easy and cost-effective to research all of your knowledge utilizing commonplace SQL and your current enterprise intelligence (BI) instruments. Amazon Redshift knowledge sharing permits for a safe and straightforward strategy to share reside knowledge for studying throughout Amazon Redshift clusters. It permits an Amazon Redshift producer cluster to share objects with a number of Amazon Redshift client clusters for learn functions with out having to repeat the information. With this method, workloads remoted to completely different clusters can share and collaborate ceaselessly on knowledge to drive innovation and supply value-added analytic providers to your inner and exterior stakeholders. You’ll be able to share knowledge at many ranges, together with databases, schemas, tables, views, columns, and user-defined SQL features, to supply fine-grained entry controls that may be tailor-made for various customers and companies that each one want entry to Amazon Redshift knowledge. The characteristic itself is easy to use and combine into current BI instruments.
On this put up, we focus on Amazon Redshift knowledge sharing, together with some greatest practices and concerns.
How does Amazon Redshift knowledge sharing work ?
- To attain greatest at school efficiency Amazon Redshift client clusters cache and incrementally replace block degree knowledge (allow us to seek advice from this as block metadata) of objects which can be queried, from the producer cluster (this works even when cluster is paused).
- The time taken for caching block metadata is determined by the speed of the information change on the producer for the reason that respective object(s) had been final queried on the patron. (As of at this time the patron clusters solely replace their metadata cache for an object solely on demand i.e. when queried)
- If there are frequent DDL operations, the patron is compelled to re-cache the total block metadata for an object throughout the subsequent entry to keep up consistency as to allow reside sharing as construction adjustments on the producer invalidate all the prevailing metadata cache on the customers.
- As soon as the patron has the block metadata in sync with the newest state of an object on the producer that’s when the question would execute as some other common question (question referring to native objects).
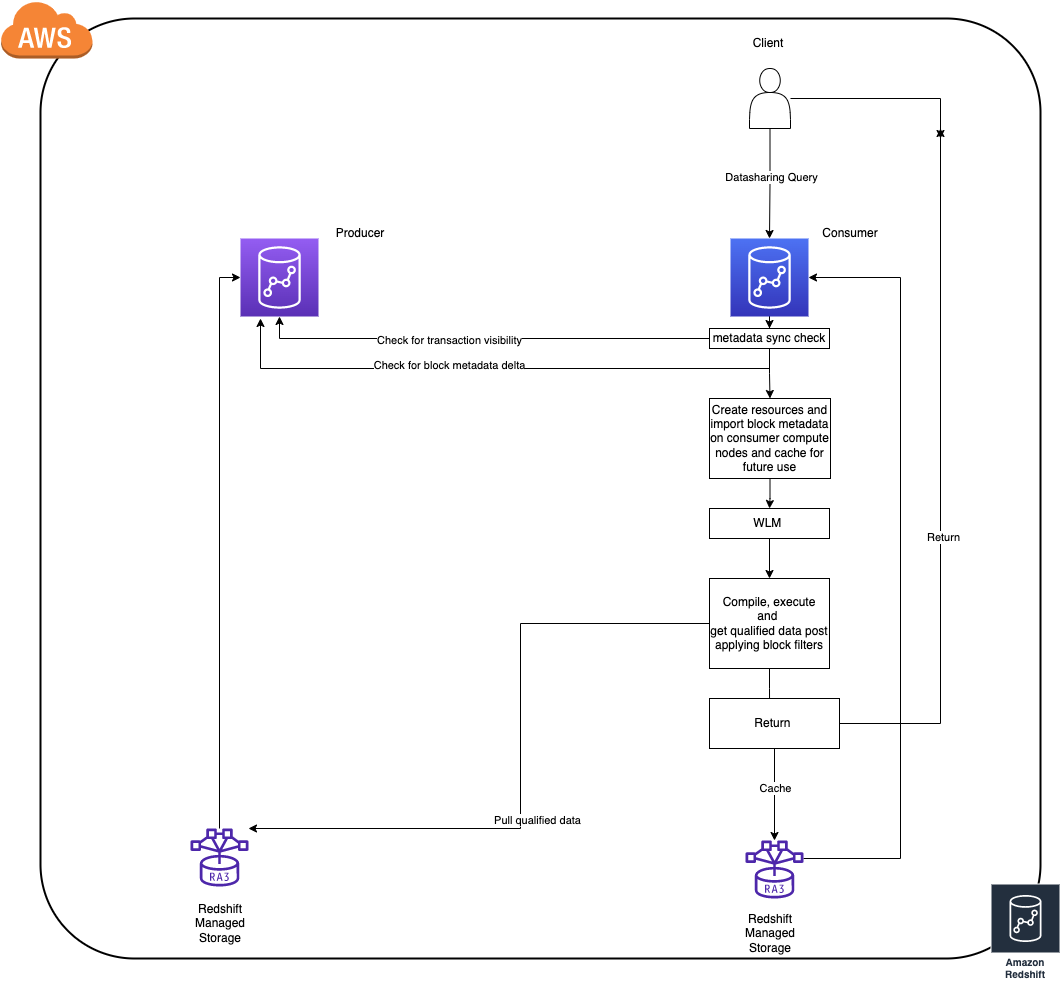
Now that we’ve the required background on knowledge sharing and the way it works, let’s take a look at just a few greatest practices throughout streams that may assist enhance workloads whereas utilizing knowledge sharing.
Safety
On this part, we share some greatest practices for safety when utilizing Amazon Redshift knowledge sharing.
Use INCLUDE NEW cautiously
INCLUDE NEW is a really helpful setting whereas including a schema to a knowledge share (ALTER DATASHARE). If set to TRUE, this robotically provides all of the objects created sooner or later within the specified schema to the information share robotically. This may not be ultimate in circumstances the place you need to have fine-grained management on objects being shared. In these circumstances, go away the setting at its default of FALSE.
Use views to realize fine-grained entry management
To attain fine-grained entry management for knowledge sharing, you may create late-binding views or materialized views on shared objects on the patron, after which share the entry to those views to customers on client cluster, as an alternative of giving full entry on the unique shared objects. This comes with its personal set of concerns, which we clarify later on this put up.
Audit knowledge share utilization and adjustments
Amazon Redshift supplies an environment friendly strategy to audit all of the exercise and adjustments with respect to a knowledge share utilizing system views. We will use the next views to verify these particulars:
Efficiency
On this part, we focus on greatest practices associated to efficiency.
Materialized views in knowledge sharing environments
Materialized views (MVs) present a strong path to precompute complicated aggregations to be used circumstances the place excessive throughput is required, and you may immediately share a materialized view object through knowledge sharing as effectively.
For materialized views constructed on tables the place there are frequent write operations, it’s ultimate to create the materialized view object on the producer itself and share the view. This technique offers us the chance to centralize the administration of the view on the producer cluster itself.
For slowly altering knowledge tables, you may share the desk objects immediately and construct the materialized view on the shared objects immediately on the patron. This technique offers us the flexibleness of making a personalized view of information on every client in accordance with your use case.
This will help optimize the block metadata obtain and caching occasions within the knowledge sharing question lifecycle. This additionally helps in materialized view refreshes as a result of, as of this writing, Redshift doesn’t assist incremental refresh for MVs constructed on shared objects.
Elements to contemplate when utilizing cross-Area knowledge sharing
Information sharing is supported even when the producer and client are in several Areas. There are just a few variations we have to take into account whereas implementing a share throughout Areas:
- Client knowledge reads are charged at $5/TB for cross area knowledge shares, Information sharing throughout the identical Area is free. For extra info, seek advice from Managing price management for cross-Area knowledge sharing.
- Efficiency will even range when in comparison with a uni-Regional knowledge share as a result of the block metadata alternate and knowledge switch course of between the cross-Regional shared clusters will take extra time as a consequence of community throughput.
Metadata entry
There are a lot of system views that assist with fetching the listing of shared objects a person has entry to. A few of these embrace all of the objects from the database that you simply’re at the moment linked to, together with objects from all the opposite databases that you’ve got entry to on the cluster, together with exterior objects. The views are as follows:
We propose utilizing very restrictive filtering whereas querying these views as a result of a easy choose * will end in a complete catalog learn, which isn’t ultimate. For instance, take the next question:
This question will attempt to gather metadata for all of the shared and native objects, making it very heavy by way of metadata scans, particularly for shared objects.
The next is a greater question for reaching an analogous end result:
It is a good observe to observe for all metadata views and tables; doing so permits seamless integration into a number of instruments. You can too use the SVV_DATASHARE* system views to solely see shared object-related info.
Producer/client dependencies
On this part, we focus on the dependencies between the producer and client.
Influence of the patron on the producer
Queries on the patron cluster can have no influence by way of efficiency or exercise on the producer cluster. This is the reason we will obtain true workload isolation utilizing knowledge sharing.
Encrypted producers and customers
Information sharing seamlessly integrates even when each the producer and the patron are encrypted utilizing completely different AWS Key Administration Service (AWS KMS) keys. There are refined, extremely safe key alternate protocols to facilitate this so that you don’t have to fret about encryption at relaxation and different compliance dependencies. The one factor to ensure is that each the producer and client are in a homogeneous encryption configuration.
Information visibility and consistency
An information sharing question on the patron can’t influence the transaction semantics on the producer. All of the queries involving shared objects on the patron cluster observe read-committed transaction consistency whereas checking for seen knowledge for that transaction.
Upkeep
If there’s a scheduled guide VACUUM operation in use for upkeep actions on the producer cluster on shared objects, you need to use VACUUM recluster at any time when doable. That is particularly essential for big objects as a result of it has optimizations by way of the variety of knowledge blocks the utility interacts with, which leads to much less block metadata churn in comparison with a full vacuum. This advantages the information sharing workloads by lowering the block metadata sync occasions.
Add-ons
On this part, we focus on further add-on options for knowledge sharing in Amazon Redshift.
Actual-time knowledge analytics utilizing Amazon Redshift streaming knowledge
Amazon Redshift just lately introduced the preview for streaming ingestion utilizing Amazon Kinesis Information Streams. This eliminates the necessity for staging the information and helps obtain low-latency knowledge entry. The information generated through streaming on the Amazon Redshift cluster is uncovered utilizing a materialized view. You’ll be able to share this as some other materialized view through an information share and use it to arrange low-latency shared knowledge entry throughout clusters in minutes.
Amazon Redshift concurrency scaling to enhance throughput
Amazon Redshift knowledge sharing queries can make the most of concurrency scaling to enhance the general throughput of the cluster. You’ll be able to allow concurrency scaling on the patron cluster for queues the place you anticipate a heavy workload to enhance the general throughput when the cluster is experiencing heavy load.
For extra details about concurrency scaling, seek advice from Information sharing concerns in Amazon Redshift.
Amazon Redshift Serverless
Amazon Redshift Serverless clusters are prepared for knowledge sharing out of the field. A serverless cluster can even act as a producer or a client for a provisioned cluster. The next are the supported permutations with Redshift Serverless:
- Serverless (producer) and provisioned (client)
- Serverless (producer) and serverless (client)
- Serverless (client) and provisioned (producer)
Conclusion
Amazon Redshift knowledge sharing offers you the flexibility to fan out and scale complicated workloads with out worrying about workload isolation. Nonetheless, like all system, not having the fitting optimization methods in place may pose complicated challenges in the long run because the programs develop in scale. Incorporating one of the best practices listed on this put up presents a strategy to mitigate potential efficiency bottlenecks proactively in varied areas.
Strive knowledge sharing at this time to unlock the total potential of Amazon Redshift, and please don’t hesitate to attain out to us in case of additional questions or clarifications.
Concerning the authors
 BP Yau is a Sr Product Supervisor at AWS. He’s enthusiastic about serving to clients architect massive knowledge options to course of knowledge at scale. Earlier than AWS, he helped Amazon.com Provide Chain Optimization Applied sciences migrate its Oracle knowledge warehouse to Amazon Redshift and construct its subsequent era massive knowledge analytics platform utilizing AWS applied sciences.
BP Yau is a Sr Product Supervisor at AWS. He’s enthusiastic about serving to clients architect massive knowledge options to course of knowledge at scale. Earlier than AWS, he helped Amazon.com Provide Chain Optimization Applied sciences migrate its Oracle knowledge warehouse to Amazon Redshift and construct its subsequent era massive knowledge analytics platform utilizing AWS applied sciences.
 Sai Teja Boddapati is a Database Engineer based mostly out of Seattle. He works on fixing complicated database issues to contribute to constructing essentially the most person pleasant knowledge warehouse out there. In his spare time, he loves travelling, taking part in video games and watching motion pictures & documentaries.
Sai Teja Boddapati is a Database Engineer based mostly out of Seattle. He works on fixing complicated database issues to contribute to constructing essentially the most person pleasant knowledge warehouse out there. In his spare time, he loves travelling, taking part in video games and watching motion pictures & documentaries.

{kind=link}