

OpenSearch is a scalable, versatile, and extensible open-source software program suite for search, analytics, safety monitoring, and observability purposes, licensed beneath the Apache 2.0 license. It includes a search engine, OpenSearch, which delivers low-latency search and aggregations, OpenSearch Dashboards, a visualization and dashboarding instrument, and a collection of plugins that present superior capabilities like alerting, fine-grained entry management, observability, safety monitoring, and vector storage and processing. Amazon OpenSearch Service is a totally managed service that makes it easy to deploy, scale, and function OpenSearch within the AWS Cloud.
As an end-user, once you use OpenSearch’s search capabilities, you usually have a purpose in thoughts—one thing you wish to accomplish. Alongside the best way, you employ OpenSearch to assemble data in assist of reaching that purpose (or possibly the knowledge is the unique purpose). We’ve all turn into used to the “search field” interface, the place you kind some phrases, and the search engine brings again outcomes based mostly on word-to-word matching. Let’s say you wish to purchase a sofa to be able to spend cozy evenings with your loved ones across the fireplace. You go to Amazon.com, and also you kind “a comfy place to take a seat by the hearth.” Sadly, if you happen to run that search on Amazon.com, you get objects like fireplace pits, heating followers, and residential decorations—not what you meant. The issue is that sofa producers in all probability didn’t use the phrases “cozy,” “place,” “sit,” and “fireplace” of their product titles or descriptions.
In recent times, machine studying (ML) strategies have turn into more and more standard to boost search. Amongst them are using embedding fashions, a sort of mannequin that may encode a big physique of information into an n-dimensional house the place every entity is encoded right into a vector, an information level in that house, and arranged such that comparable entities are nearer collectively. An embedding mannequin, as an example, may encode the semantics of a corpus. By looking for the vectors nearest to an encoded doc — k-nearest neighbor (k-NN) search — you could find probably the most semantically comparable paperwork. Refined embedding fashions can assist a number of modalities, as an example, encoding the picture and textual content of a product catalog and enabling similarity matching on each modalities.
A vector database supplies environment friendly vector similarity search by offering specialised indexes like k-NN indexes. It additionally supplies different database performance like managing vector knowledge alongside different knowledge varieties, workload administration, entry management and extra. OpenSearch’s k-NN plugin supplies core vector database performance for OpenSearch, so when your buyer searches for “a comfy place to take a seat by the hearth” in your catalog, you possibly can encode that immediate and use OpenSearch to carry out a nearest neighbor question to floor that 8-foot, blue sofa with designer organized pictures in entrance of fireplaces.
Utilizing OpenSearch Service as a vector database
With OpenSearch Service’s vector database capabilities, you possibly can implement semantic search, Retrieval Augmented Technology (RAG) with LLMs, suggestion engines, and search wealthy media.
Semantic search
With semantic search, you enhance the relevance of retrieved outcomes utilizing language-based embeddings on search paperwork. You allow your search prospects to make use of pure language queries, like “a comfy place to take a seat by the hearth” to search out their 8-foot-long blue sofa. For extra data, consult with Constructing a semantic search engine in OpenSearch to learn the way semantic search can ship a 15% relevance enchancment, as measured by normalized discounted cumulative acquire (nDCG) metrics in contrast with key phrase search. For a concrete instance, our Enhance search relevance with ML in Amazon OpenSearch Service workshop explores the distinction between key phrase and semantic search, based mostly on a Bidirectional Encoder Representations from Transformers (BERT) mannequin, hosted by Amazon SageMaker to generate vectors and retailer them in OpenSearch. The workshop makes use of product query solutions for instance to indicate how key phrase search utilizing the key phrases/phrases of the question results in some irrelevant outcomes. Semantic search is ready to retrieve extra related paperwork by matching the context and semantics of the question. The next diagram reveals an instance structure for a semantic search utility with OpenSearch Service because the vector database.
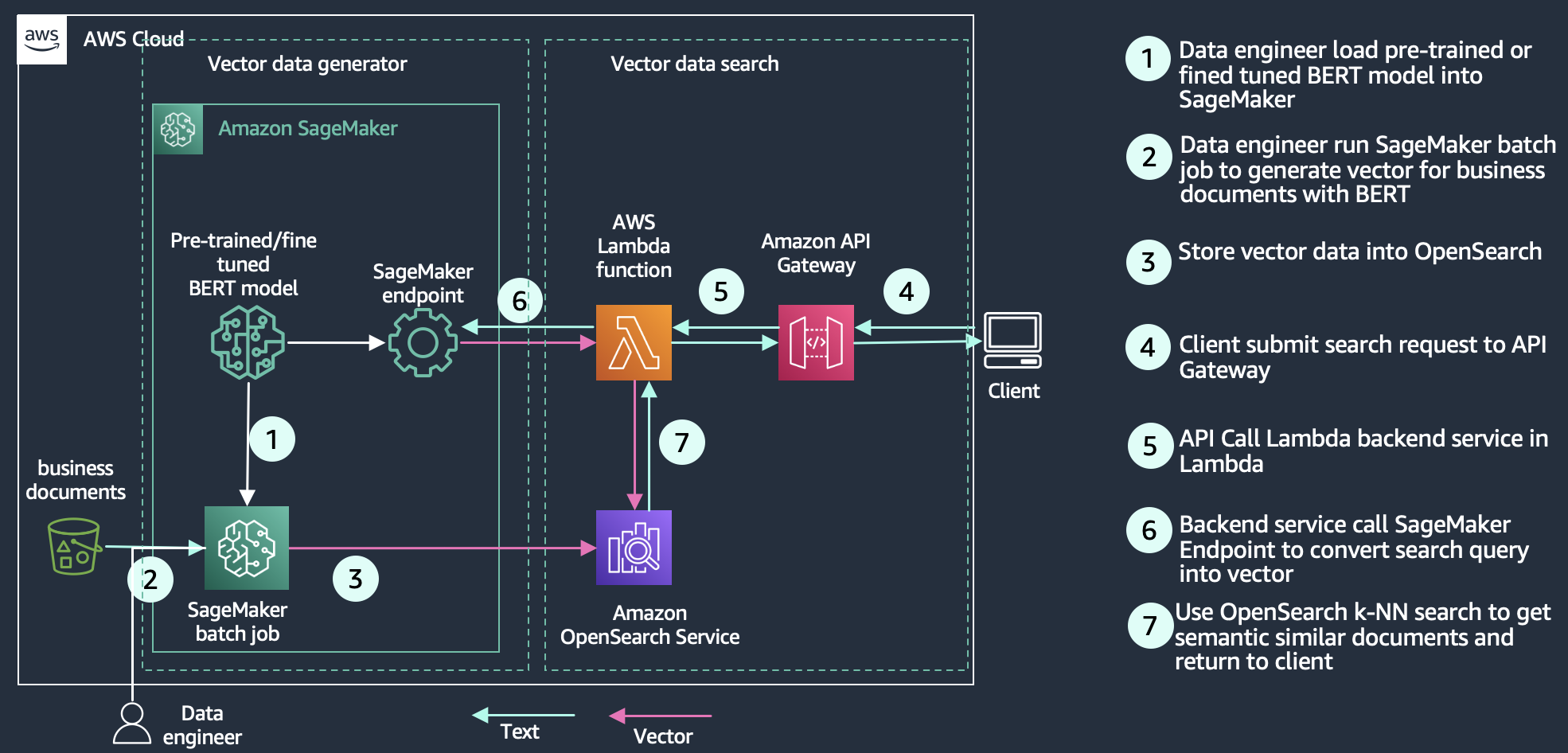
Retrieval Augmented Technology with LLMs
RAG is a technique for constructing reliable generative AI chatbots utilizing generative LLMs like OpenAI, ChatGPT, or Amazon Titan Textual content. With the rise of generative LLMs, utility builders are searching for methods to benefit from this modern expertise. One standard use case entails delivering conversational experiences by means of clever brokers. Maybe you’re a software program supplier with data bases for product data, buyer self-service, or business area data like tax reporting guidelines or medical details about ailments and coverings. A conversational search expertise supplies an intuitive interface for customers to sift by means of data by means of dialog and Q&A. Generative LLMs on their very own are vulnerable to hallucinations—a state of affairs the place the mannequin generates a plausible however factually incorrect response. RAG solves this downside by complementing generative LLMs with an exterior data base that’s usually constructed utilizing a vector database hydrated with vector-encoded data articles.
As illustrated within the following diagram, the question workflow begins with a query that’s encoded and used to retrieve related data articles from the vector database. These outcomes are despatched to the generative LLM whose job is to enhance these outcomes, usually by summarizing the outcomes as a conversational response. By complementing the generative mannequin with a data base, RAG grounds the mannequin on details to reduce hallucinations. You possibly can study extra about constructing a RAG answer within the Retrieval Augmented Technology module of our semantic search workshop.
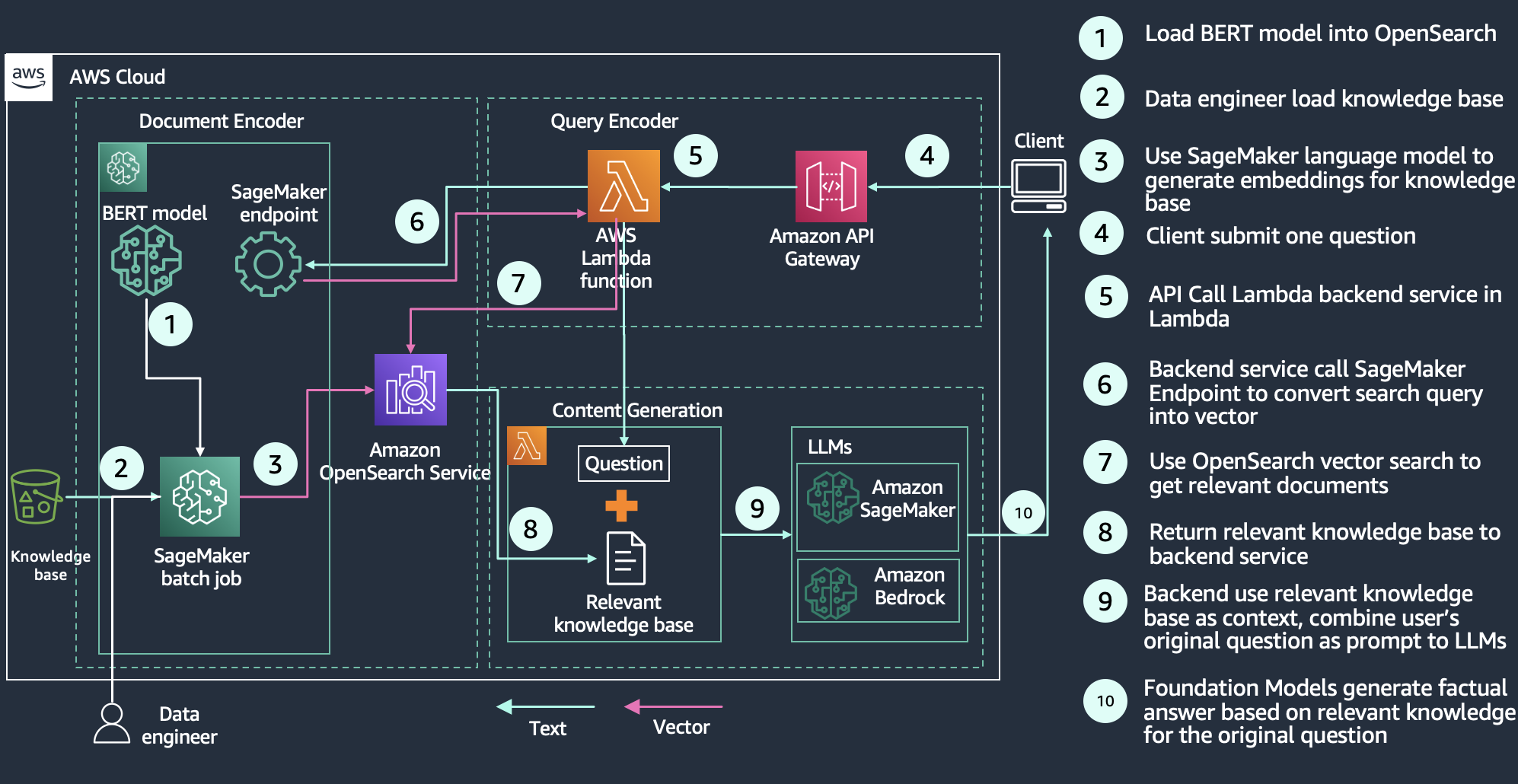
Advice engine
Suggestions are a typical element within the search expertise, particularly for ecommerce purposes. Including a consumer expertise characteristic like “extra like this” or “prospects who purchased this additionally purchased that” can drive further income by means of getting prospects what they need. Search architects make use of many strategies and applied sciences to construct suggestions, together with Deep Neural Community (DNN) based mostly suggestion algorithms such because the two-tower neural web mannequin, YoutubeDNN. A skilled embedding mannequin encodes merchandise, for instance, into an embedding house the place merchandise which are ceaselessly purchased collectively are thought-about extra comparable, and due to this fact are represented as knowledge factors which are nearer collectively within the embedding house. One other chance
is that product embeddings are based mostly on co-rating similarity as an alternative of buy exercise. You possibly can make use of this affinity knowledge by means of calculating the vector similarity between a selected consumer’s embedding and vectors within the database to return advisable objects. The next diagram reveals an instance structure of constructing a suggestion engine with OpenSearch as a vector retailer.
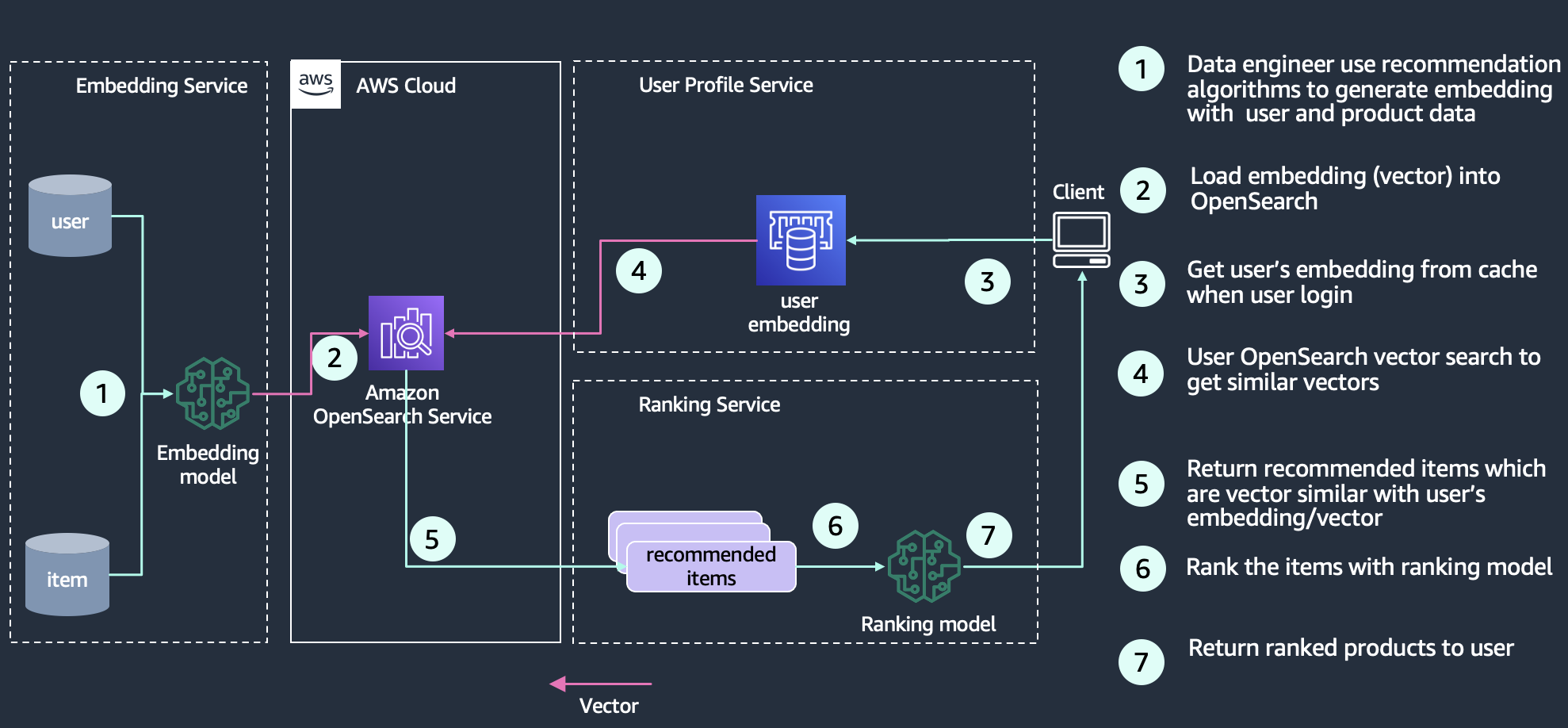
Media search
Media search allows customers to question the search engine with wealthy media like photos, audio, and video. Its implementation is just like semantic search—you create vector embeddings on your search paperwork after which question OpenSearch Service with a vector. The distinction is you employ a pc imaginative and prescient deep neural community (e.g. Convolutional Neural Community (CNN)) resembling ResNet to transform photos into vectors. The next diagram reveals an instance structure of constructing a picture search with OpenSearch because the vector retailer.
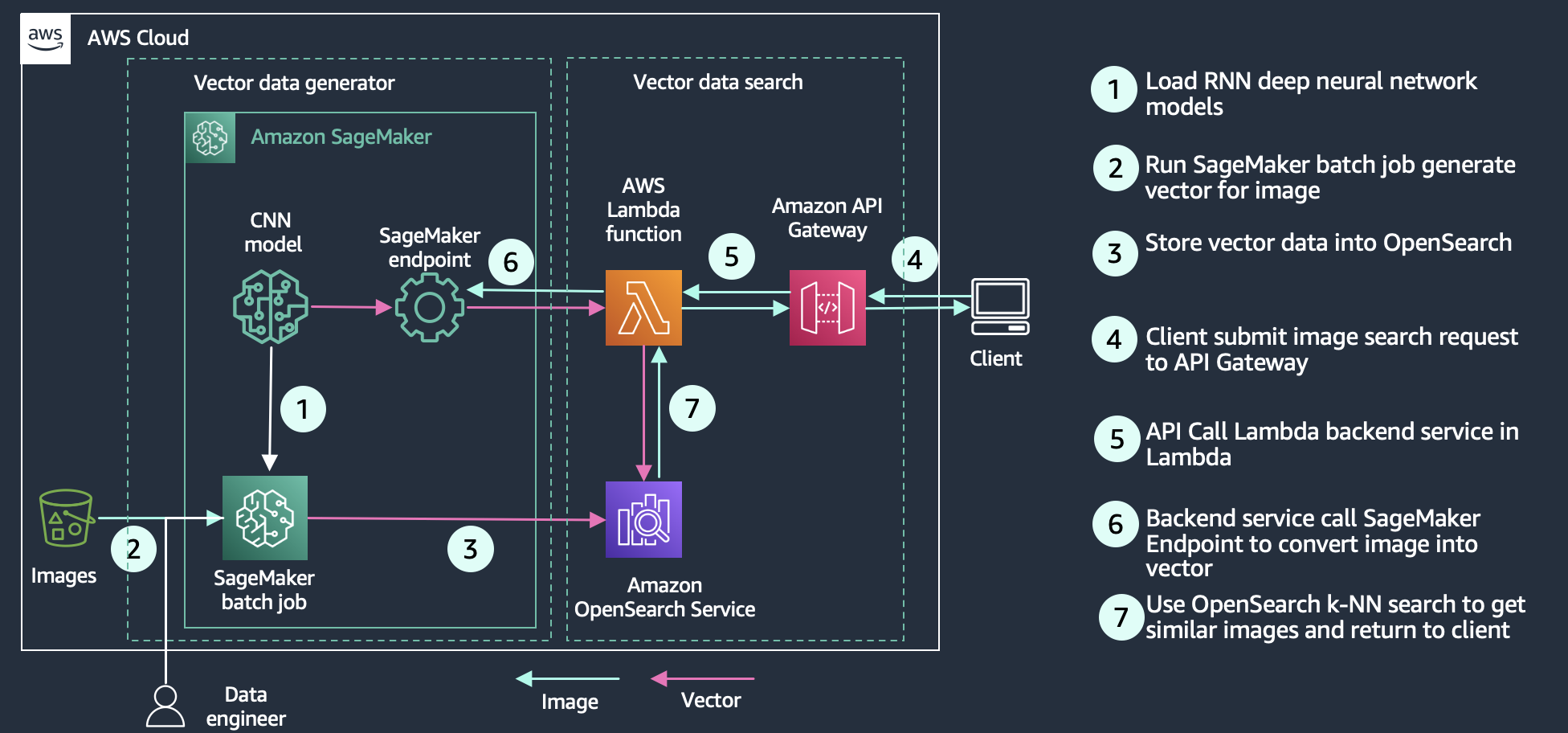
Understanding the expertise
OpenSearch makes use of approximate nearest neighbor (ANN) algorithms from the NMSLIB, FAISS, and Lucene libraries to energy k-NN search. These search strategies make use of ANN to enhance search latency for big datasets. Of the three search strategies the k-NN plugin supplies, this technique affords one of the best search scalability for big datasets. The engine particulars are as follows:
- Non-Metric House Library (NMSLIB) – NMSLIB implements the HNSW ANN algorithm
- Fb AI Similarity Search (FAISS) – FAISS implements each HNSW and IVF ANN algorithms
- Lucene – Lucene implements the HNSW algorithm
Every of the three engines used for approximate k-NN search has its personal attributes that make yet another wise to make use of than the others in a given state of affairs. You possibly can comply with the overall data on this part to assist decide which engine will greatest meet your necessities.
On the whole, NMSLIB and FAISS must be chosen for large-scale use circumstances. Lucene is an efficient choice for smaller deployments, however affords advantages like sensible filtering the place the optimum filtering technique—pre-filtering, post-filtering, or actual k-NN—is robotically utilized relying on the state of affairs. The next desk summarizes the variations between every choice.
| . |
NMSLIB-HNSW |
FAISS-HNSW |
FAISS-IVF |
Lucene-HNSW |
|
Max Dimension |
16,000 |
16,000 |
16,000 |
1024 |
|
Filter |
Publish filter |
Publish filter |
Publish filter |
Filter whereas search |
|
Coaching Required |
No |
No |
Sure |
No |
|
Similarity Metrics |
l2, innerproduct, cosinesimil, l1, linf |
l2, innerproduct |
l2, innerproduct |
l2, cosinesimil |
|
Vector Quantity |
Tens of billions |
Tens of billions |
Tens of billions |
< Ten million |
|
Indexing latency |
Low |
Low |
Lowest |
Low |
|
Question Latency & High quality |
Low latency & top quality |
Low latency & top quality |
Low latency & low high quality |
Excessive latency & top quality |
|
Vector Compression |
Flat |
Flat Product Quantization |
Flat Product Quantization |
Flat |
|
Reminiscence Consumption |
Excessive |
Excessive Low with PQ |
Medium Low with PQ |
Excessive |
Approximate and actual nearest-neighbor search
The OpenSearch Service k-NN plugin helps three completely different strategies for acquiring the k-nearest neighbors from an index of vectors: approximate k-NN, rating script (actual k-NN), and painless extensions (actual k-NN).
Approximate k-NN
The primary technique takes an approximate nearest neighbor strategy—it makes use of one in every of a number of algorithms to return the approximate k-nearest neighbors to a question vector. Often, these algorithms sacrifice indexing velocity and search accuracy in return for efficiency advantages resembling decrease latency, smaller reminiscence footprints, and extra scalable search. Approximate k-NN is the only option for searches over giant indexes (that’s, a whole lot of hundreds of vectors or extra) that require low latency. You shouldn’t use approximate k-NN if you wish to apply a filter on the index earlier than the k-NN search, which enormously reduces the variety of vectors to be searched. On this case, it’s best to use both the rating script technique or painless extensions.
Rating script
The second technique extends the OpenSearch Service rating script performance to run a brute power, actual k-NN search over knn_vector fields or fields that may characterize binary objects. With this strategy, you possibly can run k-NN search on a subset of vectors in your index (typically known as a pre-filter search). This strategy is most well-liked for searches over smaller our bodies of paperwork or when a pre-filter is required. Utilizing this strategy on giant indexes could result in excessive latencies.
Painless extensions
The third technique provides the gap capabilities as painless extensions that you need to use in additional complicated mixtures. Much like the k-NN rating script, you need to use this technique to carry out a brute power, actual k-NN search throughout an index, which additionally helps pre-filtering. This strategy has barely slower question efficiency in comparison with the k-NN rating script. In case your use case requires extra customization over the ultimate rating, it’s best to use this strategy over rating script k-NN.
Vector search algorithms
The straightforward option to discover comparable vectors is to make use of k-nearest neighbors (k-NN) algorithms, which compute the gap between a question vector and the opposite vectors within the vector database. As we talked about earlier, the rating script k-NN and painless extensions search strategies use the precise k-NN algorithms beneath the hood. Nonetheless, within the case of extraordinarily giant datasets with excessive dimensionality, this creates a scaling downside that reduces the effectivity of the search. Approximate nearest neighbor (ANN) search strategies can overcome this by using instruments that restructure indexes extra effectively and scale back the dimensionality of searchable vectors. There are completely different ANN search algorithms; for instance, locality delicate hashing, tree-based, cluster-based, and graph-based. OpenSearch implements two ANN algorithms: Hierarchical Navigable Small Worlds (HNSW) and Inverted File System (IVF). For a extra detailed clarification of how the HNSW and IVF algorithms work in OpenSearch, see weblog publish “Select the k-NN algorithm on your billion-scale use case with OpenSearch”.
Hierarchical Navigable Small Worlds
The HNSW algorithm is without doubt one of the hottest algorithms on the market for ANN search. The core concept of the algorithm is to construct a graph with edges connecting index vectors which are shut to one another. Then, on search, this graph is partially traversed to search out the approximate nearest neighbors to the question vector. To steer the traversal in the direction of the question’s nearest neighbors, the algorithm at all times visits the closest candidate to the question vector subsequent.
Inverted File
The IVF algorithm separates your index vectors right into a set of buckets, then, to cut back your search time, solely searches by means of a subset of those buckets. Nonetheless, if the algorithm simply randomly cut up up your vectors into completely different buckets, and solely searched a subset of them, it might yield a poor approximation. The IVF algorithm makes use of a extra elegant strategy. First, earlier than indexing begins, it assigns every bucket a consultant vector. When a vector is listed, it will get added to the bucket that has the closest consultant vector. This manner, vectors which are nearer to one another are positioned roughly in the identical or close by buckets.
Vector similarity metrics
All engines like google use a similarity metric to rank and type outcomes and produce probably the most related outcomes to the highest. If you use a plain textual content question, the similarity metric is named TF-IDF, which measures the significance of the phrases within the question and generates a rating based mostly on the variety of textual matches. When your question features a vector, the similarity metrics are spatial in nature, profiting from proximity within the vector house. OpenSearch helps a number of similarity or distance measures:
- Euclidean distance – The straight-line distance between factors.
- L1 (Manhattan) distance – The sum of the variations of all the vector parts. L1 distance measures what number of orthogonal metropolis blocks you have to traverse from level A to level B.
- L-infinity (chessboard) distance – The variety of strikes a King would make on an n-dimensional chessboard. It’s completely different than Euclidean distance on the diagonals—a diagonal step on a 2-dimensional chessboard is 1.41 Euclidean items away, however 2 L-infinity items away.
- Interior product – The product of the magnitudes of two vectors and the cosine of the angle between them. Often used for pure language processing (NLP) vector similarity.
- Cosine similarity – The cosine of the angle between two vectors in a vector house.
- Hamming distance – For binary-coded vectors, the variety of bits that differ between the 2 vectors.
Benefit of OpenSearch as a vector database
If you use OpenSearch Service as a vector database, you possibly can benefit from the service’s options like usability, scalability, availability, interoperability, and safety. Extra importantly, you need to use OpenSearch’s search options to boost the search expertise. For instance, you need to use Studying to Rank in OpenSearch to combine consumer clickthrough habits knowledge into your search utility and enhance search relevance. It’s also possible to mix OpenSearch textual content search and vector search capabilities to look paperwork with key phrase and semantic similarity. It’s also possible to use different fields within the index to filter paperwork to enhance relevance. For superior customers, you need to use a hybrid scoring mannequin to mix OpenSearch’s text-based relevance rating, computed with the Okapi BM25 operate and its vector search rating to enhance the rating of your search outcomes.
Scale and limits
OpenSearch as vector database assist billions of vector data. Take note the next calculator concerning variety of vectors and dimensions to dimension your cluster.
Variety of vectors
OpenSearch VectorDB takes benefit of the sharding capabilities of OpenSearch and may scale to billions of vectors at single-digit millisecond latencies by sharding vectors and scale horizontally by including extra nodes. The variety of vectors that may slot in a single machine is a operate of the off-heap reminiscence availability on the machine. The variety of nodes required will rely upon the quantity of reminiscence that can be utilized for the algorithm per node and the entire quantity of reminiscence required by the algorithm. The extra nodes, the extra reminiscence and higher efficiency. The quantity of reminiscence out there per node is computed as memory_available = (node_memory – jvm_size) * circuit_breaker_limit, with the next parameters:
- node_memory – The entire reminiscence of the occasion.
- jvm_size – The OpenSearch JVM heap dimension. That is set to half of the occasion’s RAM, capped at roughly 32 GB.
- circuit_breaker_limit – The native reminiscence utilization threshold for the circuit breaker. That is set to 0.5.
Complete cluster reminiscence estimation depends upon complete variety of vector data and algorithms. HNSW and IVF have completely different reminiscence necessities. You possibly can consult with Reminiscence Estimation for extra particulars.
Variety of dimensions
OpenSearch’s present dimension restrict for the vector discipline knn_vector is 16,000 dimensions. Every dimension is represented as a 32-bit float. The extra dimensions, the extra reminiscence you’ll must index and search. The variety of dimensions is often decided by the embedding fashions that translate the entity to a vector. There are numerous choices to select from when constructing your knn_vector discipline. To find out the proper strategies and parameters to decide on, consult with Selecting the best technique.
Buyer tales:
Amazon Music
Amazon Music is at all times innovating to offer prospects with distinctive and personalised experiences. One in all Amazon Music’s approaches to music suggestions is a remix of a traditional Amazon innovation, item-to-item collaborative filtering, and vector databases. Utilizing knowledge aggregated based mostly on consumer listening habits, Amazon Music has created an embedding mannequin that encodes music tracks and buyer representations right into a vector house the place neighboring vectors characterize tracks which are comparable. 100 million songs are encoded into vectors, listed into OpenSearch, and served throughout a number of geographies to energy real-time suggestions. OpenSearch presently manages 1.05 billion vectors and helps a peak load of seven,100 vector queries per second to energy Amazon Music suggestions.
The item-to-item collaborative filter continues to be among the many hottest strategies for on-line product suggestions due to its effectiveness at scaling to giant buyer bases and product catalogs. OpenSearch makes it simpler to operationalize and additional the scalability of the recommender by offering scale-out infrastructure and k-NN indexes that develop linearly with respect to the variety of tracks and similarity search in logarithmic time.
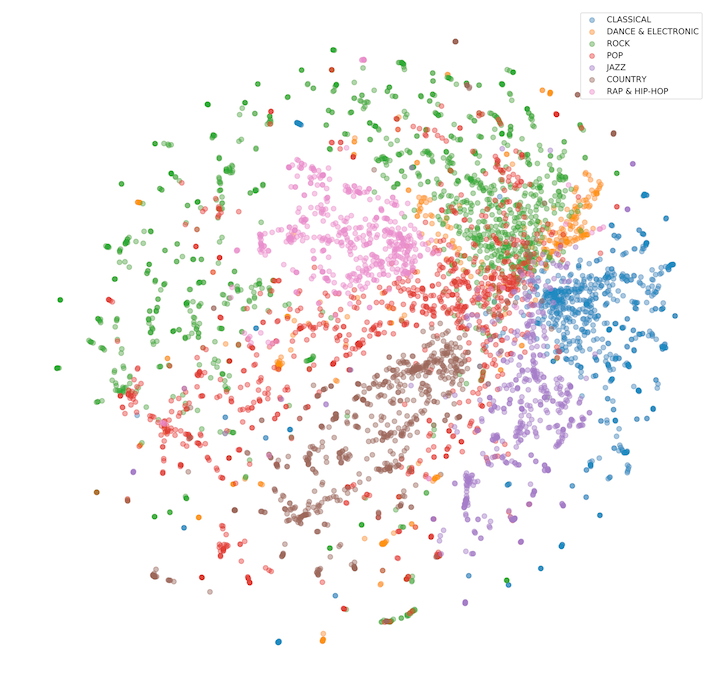
The next determine visualizes the high-dimensional house created by the vector embedding.
Model safety at Amazon
Amazon strives to ship the world’s most reliable buying expertise, providing prospects the widest potential choice of genuine merchandise. To earn and keep our prospects’ belief, we strictly prohibit the sale of counterfeit merchandise, and we proceed to spend money on improvements that guarantee solely genuine merchandise attain our prospects. Amazon’s model safety packages construct belief with manufacturers by precisely representing and utterly defending their model. We attempt to make sure that public notion mirrors the reliable expertise we ship. Our model safety technique focuses on 4 pillars: (1) Proactive Controls (2) Highly effective Instruments to Shield Manufacturers (3) Holding Dangerous Actors Accountable (4) Defending and Educating Clients. Amazon OpenSearch Service is a key a part of Amazon’s Proactive Controls.
In 2022, Amazon’s automated expertise scanned greater than 8 billion tried modifications each day to product element pages for indicators of potential abuse. Our proactive controls discovered greater than 99% of blocked or eliminated listings earlier than a model ever needed to discover and report it. These listings had been suspected of being fraudulent, infringing, counterfeit, or prone to different types of abuse. To carry out these scans, Amazon created tooling that makes use of superior and modern strategies, together with using superior machine studying fashions to automate the detection of mental property infringements in listings throughout Amazon’s shops globally. A key technical problem in implementing such automated system is the flexibility to seek for protected mental property inside an unlimited billion-vector corpus in a quick, scalable and value efficient method. Leveraging Amazon OpenSearch Service’s scalable vector database capabilities and distributed structure, we efficiently developed an ingestion pipeline that has listed a complete of 68 billion, 128- and 1024-dimension vectors into OpenSearch Service to allow manufacturers and automatic programs to conduct infringement detection, in real-time, by means of a extremely out there and quick (sub-second) search API.
Conclusion
Whether or not you’re constructing a generative AI answer, looking out wealthy media and audio, or bringing extra semantic search to your present search-based utility, OpenSearch is a succesful vector database. OpenSearch helps a wide range of engines, algorithms, and distance measures that you could make use of to construct the suitable answer. OpenSearch supplies a scalable engine that may assist vector search at low latency and as much as billions of vectors. With OpenSearch and its vector DB capabilities, your customers can discover that 8-foot-blue sofa simply, and loosen up by a comfy fireplace.
Concerning the Authors
 Jon Handler is a Senior Principal Options Architect at Amazon Net Providers based mostly in Palo Alto, CA. Jon works intently with OpenSearch and Amazon OpenSearch Service, offering assist and steering to a broad vary of shoppers who’ve search and log analytics workloads that they wish to transfer to the AWS Cloud. Previous to becoming a member of AWS, Jon’s profession as a software program developer included 4 years of coding a large-scale, eCommerce search engine. Jon holds a Bachelor of the Arts from the College of Pennsylvania, and a Grasp of Science and a Ph. D. in Pc Science and Synthetic Intelligence from Northwestern College.
Jon Handler is a Senior Principal Options Architect at Amazon Net Providers based mostly in Palo Alto, CA. Jon works intently with OpenSearch and Amazon OpenSearch Service, offering assist and steering to a broad vary of shoppers who’ve search and log analytics workloads that they wish to transfer to the AWS Cloud. Previous to becoming a member of AWS, Jon’s profession as a software program developer included 4 years of coding a large-scale, eCommerce search engine. Jon holds a Bachelor of the Arts from the College of Pennsylvania, and a Grasp of Science and a Ph. D. in Pc Science and Synthetic Intelligence from Northwestern College.
 Jianwei Li is a Principal Analytics Specialist TAM at Amazon Net Providers. Jianwei supplies marketing consultant service for purchasers to assist buyer design and construct fashionable knowledge platform. Jianwei has been working in large knowledge area as software program developer, marketing consultant and tech chief.
Jianwei Li is a Principal Analytics Specialist TAM at Amazon Net Providers. Jianwei supplies marketing consultant service for purchasers to assist buyer design and construct fashionable knowledge platform. Jianwei has been working in large knowledge area as software program developer, marketing consultant and tech chief.
 Dylan Tong is a Senior Product Supervisor at AWS. He works with prospects to assist drive their success on the AWS platform by means of thought management and steering on designing nicely architected options. He has spent most of his profession constructing on his experience in knowledge administration and analytics by working for leaders and innovators within the house.
Dylan Tong is a Senior Product Supervisor at AWS. He works with prospects to assist drive their success on the AWS platform by means of thought management and steering on designing nicely architected options. He has spent most of his profession constructing on his experience in knowledge administration and analytics by working for leaders and innovators within the house.
 Vamshi Vijay Nakkirtha is a Software program Engineering Supervisor engaged on the OpenSearch Mission and Amazon OpenSearch Service. His main pursuits embrace distributed programs. He’s an lively contributor to varied plugins, like k-NN, GeoSpatial, and dashboard-maps.
Vamshi Vijay Nakkirtha is a Software program Engineering Supervisor engaged on the OpenSearch Mission and Amazon OpenSearch Service. His main pursuits embrace distributed programs. He’s an lively contributor to varied plugins, like k-NN, GeoSpatial, and dashboard-maps.

{kind=link}