

Amazon Managed Streaming for Apache Kafka (Amazon MSK) is a completely managed service that lets you construct and run functions that use Apache Kafka to course of streaming information.
Right now, we’re excited to convey the advantages of Graviton3 to Kafka workloads, with Amazon MSK now providing M7g cases for brand new MSK provisioned clusters. AWS Graviton processors are customized Arm-based processors constructed by AWS to ship the perfect price-performance in your cloud workloads. For instance, when working an MSK provisioned cluster utilizing M7g.4xlarge cases, you possibly can obtain as much as 27% discount in CPU utilization and as much as 29% larger write and browse throughput in comparison with M5.4xlarge cases. These efficiency enhancements, together with M7g’s decrease costs, present as much as 24% in compute price financial savings over M5 cases.
In February 2023, AWS launched new Graviton3-based M7g cases. M7g cases are outfitted with DDR5 reminiscence, which gives as much as 50% larger reminiscence bandwidth than the DDR4 reminiscence utilized in earlier generations. M7g cases additionally ship as much as 25% larger storage throughput and as much as 88% enhance in community throughput in comparison with comparable sized M5 cases to ship price-performance advantages for Kafka workloads. You’ll be able to learn extra about M7g options in New Graviton3-Primarily based Basic Objective (m7g) and Reminiscence-Optimized (r7g) Amazon EC2 Situations.
The next desk lists the specs for the M7g cases on Amazon MSK:
| Identify | vCPUs | Reminiscence | Community Bandwidth | Storage Bandwidth |
| M7g.giant | 2 | 8 GiB | as much as 12.5 Gbps | as much as 10 Gbps |
| M7g.xlarge | 4 | 16 GiB | as much as 12.5 Gbps | as much as 10 Gbps |
| M7g.2xlarge | 8 | 32 GiB | as much as 15 Gbps | as much as 10 Gbps |
| M7g.4xlarge | 16 | 64 GiB | as much as 15 Gbps | as much as 10 Gbps |
| M7g.8xlarge | 32 | 128 GiB | 15 Gbps | 10 Gbps |
| M7g.12xlarge | 48 | 192 GiB | 22.5 Gbps | 15 Gbps |
| M7g.16xlarge | 64 | 256 GiB | 30 Gbps | 20 Gbps |
M7g cases on Amazon MSK
Organizations are adopting Amazon MSK to seize and analyze information in actual time, run machine studying (ML) workflows, and construct event-driven architectures. Amazon MSK lets you scale back operational overhead and run your functions with larger availability and sturdiness. It additionally provides a constant discount in price-performance with capabilities similar to Tiered Storage. With compute making up a big portion of Kafka prices, clients needed a approach to optimize them additional and see Graviton cases offering them the quickest path. Amazon MSK has absolutely examined and validated M7g on Kafka variations 2.8.2, 3.3.2, and above, making it simple to run vital workloads and profit from Graviton3 price financial savings.
You will get began by provisioning new clusters with the Graviton3-based M7g cases because the dealer sort utilizing the AWS Administration Console, APIs by way of the AWS SDK, and the AWS Command Line Interface (AWS CLI). M7g cases help all Amazon MSK and Kafka options, making it simple so that you can run all of your present Kafka workloads with minimal modifications. Amazon MSK helps Graviton3-based M7g cases from giant by way of 16xlarge sizes to run all Kafka workloads.
Let’s take the M7g cases on MSK provisioned clusters for a check drive and see the way it compares with Amazon MSK M5 cases.
M7g cases in motion
Prospects run all kinds of workloads on Amazon MSK; some are latency delicate, and a few are throughput sure. On this publish, we give attention to M7g efficiency influence on throughput-bound workloads. M7g comes with a rise in community and storage throughput, offering a better throughput per dealer in comparison with an M5-based cluster.
To grasp the implications, let’s take a look at how Kafka makes use of accessible throughput for writing or studying information. Each dealer within the MSK cluster comes with a bounded storage and community throughput entitlement. Predominantly, writes in Kafka devour each storage and community throughput, whereas reads devour largely community throughput. It’s because a Kafka shopper is often studying real-time information from a web page cache and sometimes goes to disk to course of outdated information. Subsequently, the general throughput positive aspects additionally change primarily based on the workload’s write to learn throughput ratios.
Let’s take a look at the throughput positive aspects primarily based on an instance. Our setup contains an MSK cluster with M7g.4xlarge cases and one other with M5.4xlarge cases, with three nodes in three totally different Availability Zones. We additionally enabled TLS encryption, AWS Id and Entry Administration (IAM) authentication, and a replication issue of three throughout each M7g and M5 MSK clusters. We additionally utilized Amazon MSK greatest practices for dealer configurations, together with num.community.threads = 8 and num.io.threads = 16. On the shopper aspect for writes, we optimized the batch dimension with applicable linger.ms and batch.dimension configurations. For the workload, we assumed 6 matters every with 64 partitions (384 per dealer). For ingestion, we generated load with a mean message dimension of 512 bytes and with one shopper group per matter. The quantity of load despatched to the clusters was equivalent.
As we ingest extra information into the MSK cluster, the M7g.4xlarge occasion helps larger throughput per dealer, as proven within the following graph. After an hour of constant writes, M7g.4xlarge brokers help as much as 54 MB/s of write throughput vs. 40 MB/s with M5-based brokers, which represents a 29% enhance.
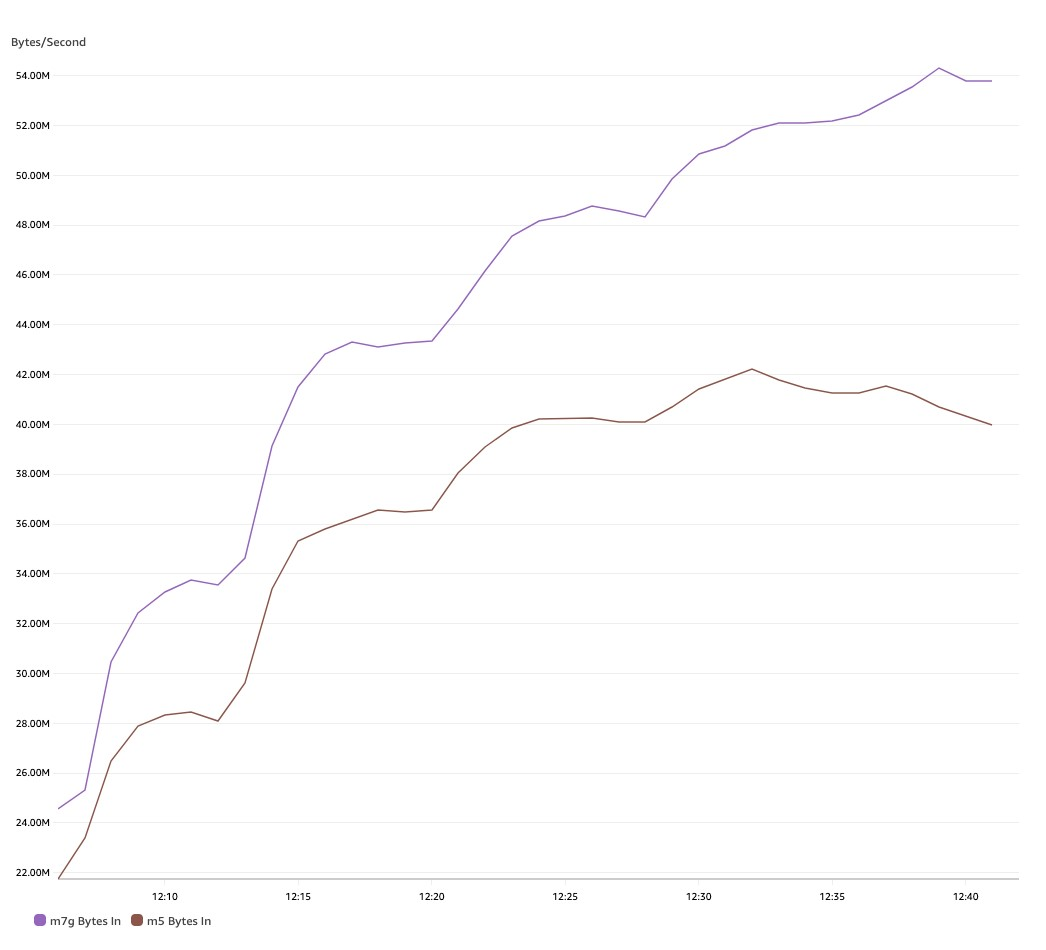
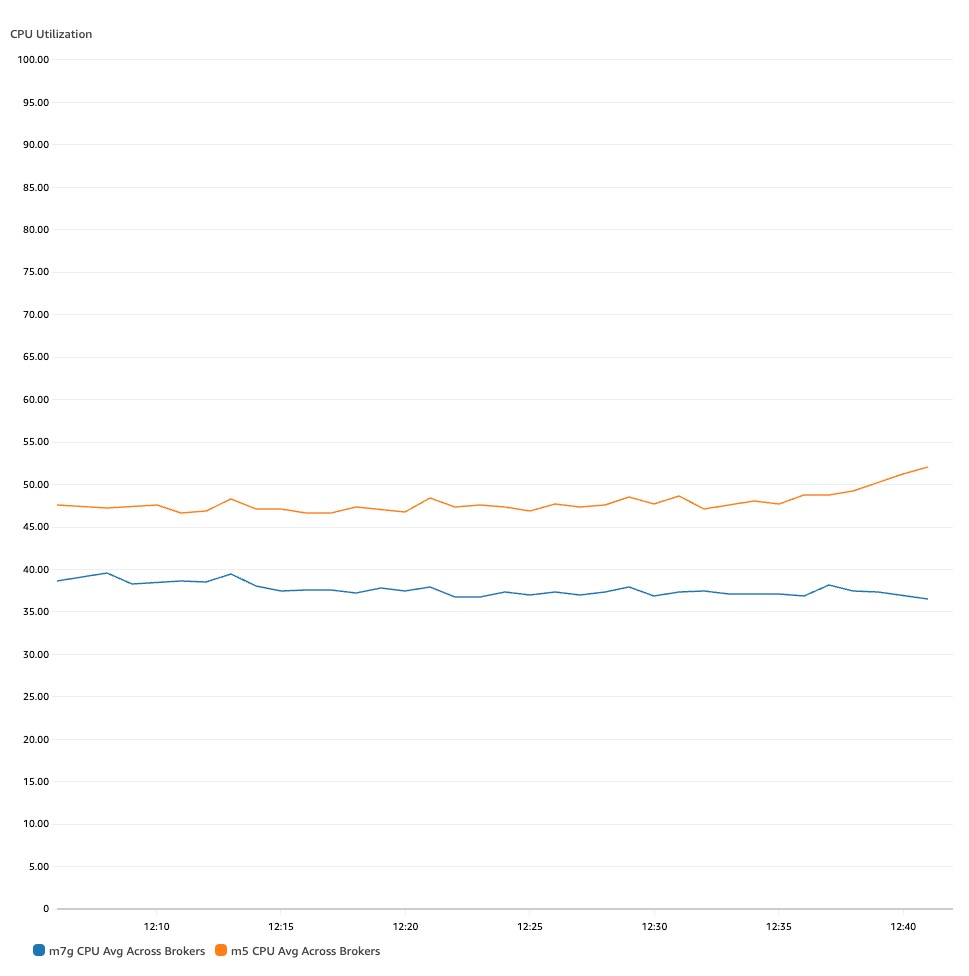
We additionally see one other essential commentary: M7g-based brokers devour a lot fewer CPU sources than M5s, though they help 29% larger throughput. As seen within the following chart, CPU utilization of an M7g-based dealer is on common 40%, whereas on an M5-based dealer, it’s 47%.
As coated beforehand, clients may even see totally different efficiency enhancements primarily based on the variety of shopper group, batch sizes, and occasion dimension. We advocate referring to MSK Sizing and Pricing to calculate M7g efficiency positive aspects in your use case or making a cluster primarily based on M7g cases and benchmark the positive aspects by yourself.
Decrease prices, with lesser operational burden, and better resiliency
Since its launch, Amazon MSK has made it cost-effective to run your Kafka workloads, whereas nonetheless bettering general resiliency. Since day 1, you’ve been capable of run brokers in a number of Availability Zones with out worrying about extra networking prices. In October 2022, we launched Tiered Storage, which gives just about limitless storage at as much as 50% decrease prices. If you use Tiered Storage, you not solely save on general storage price but additionally enhance the general availability and elasticity of your cluster.
Persevering with down this path, we are actually decreasing compute prices for patrons whereas nonetheless offering efficiency enhancements. With M7g cases, Amazon MSK gives 24% financial savings on compute prices in comparison with comparable sized M5 cases. If you transfer to Amazon MSK, you cannot solely decrease your operational overhead utilizing options similar to Amazon MSK Join, Amazon MSK Replicator, and computerized Kafka model upgrades, but additionally enhance over resiliency and scale back your infrastructure prices.
Pricing and Areas
M7g cases on Amazon MSK can be found in the present day within the Asia Pacific (Tokyo), Asia Pacific (Mumbai), Asia Pacific (Singapore), Asia Pacific (Sydney), Europe (Stockholm), Europe (Spain), Europe (Eire), US East (N. Virginia), US East (Ohio), US West (N. California), US West (Oregon) areas.
Discuss with Amazon MSK pricing to find out about Graviton3-based cases with Amazon MSK pricing.
Abstract
On this publish, we mentioned the efficiency positive aspects achieved whereas utilizing Graviton-based M7g cases. These cases can present vital enchancment in learn and write throughput in comparison with comparable sized M5 cases for Amazon MSK workloads. To get began, create a brand new cluster with M7g brokers utilizing the AWS Administration Console, and consult with the Amazon MSK Developer Information for extra data.
In regards to the Authors
 Sai Maddali is a Senior Supervisor Product Administration at AWS who leads the product group for Amazon MSK. He’s keen about understanding buyer wants, and utilizing know-how to ship companies that empowers clients to construct modern functions. In addition to work, he enjoys touring, cooking, and working.
Sai Maddali is a Senior Supervisor Product Administration at AWS who leads the product group for Amazon MSK. He’s keen about understanding buyer wants, and utilizing know-how to ship companies that empowers clients to construct modern functions. In addition to work, he enjoys touring, cooking, and working.
 Umesh Chaudhari is a Streaming Options Architect at AWS. He works with AWS clients to design and construct real-time information processing techniques. He has 13 years of working expertise in software program engineering together with architecting, designing, and creating information analytics techniques.
Umesh Chaudhari is a Streaming Options Architect at AWS. He works with AWS clients to design and construct real-time information processing techniques. He has 13 years of working expertise in software program engineering together with architecting, designing, and creating information analytics techniques.
 Lanre Afod is a Options Architect centered with World Monetary Companies at AWS, keen about serving to clients with deploying safe, scalable, excessive accessible, and resilient architectures inside the AWS Cloud.
Lanre Afod is a Options Architect centered with World Monetary Companies at AWS, keen about serving to clients with deploying safe, scalable, excessive accessible, and resilient architectures inside the AWS Cloud.

{kind=link}