

Trendy apps usually are not monolithic; they’re composed of a fancy graph of
interconnected microservices, the place the response time for one element
can affect the efficiency of the complete system. For example, a web page
load on an e-commerce web site might require inputs from a dozen
microservices, every of which should execute shortly to render the complete
web page as quick as doable so that you don’t lose a buyer. It’s essential
that the info methods that help these microservices carry out quickly
and reliably, and the place velocity is a main concern, Redis has all the time
been prime of thoughts for me.
Redis is an extremely widespread distributed information construction retailer. It was
named the “Most Cherished” database by Stack Overflow’s developer
survey for the fifth
yr in a row for its developer-focused APIs to govern in-memory
information constructions. It’s generally used for caching, streaming, session
shops, and leaderboards, however it may be used for any software
requiring distant, synchronized information constructions. With all information saved in
reminiscence, most operations take solely microseconds to execute. Nevertheless, the
velocity of an in-memory system comes with a draw back—within the occasion of a
course of failure, information will likely be misplaced and there’s no approach to configure Redis
to be each strongly constant and extremely accessible.
AWS already helps Redis for caching and different ephemeral use instances
with Amazon ElastiCache. We’ve
heard from builders that Redis is their most well-liked information retailer for very
low-latency microservices functions the place each microsecond issues,
however that they want stronger consistency ensures. Builders would
work round this deficiency with advanced architectures that re-hydrate
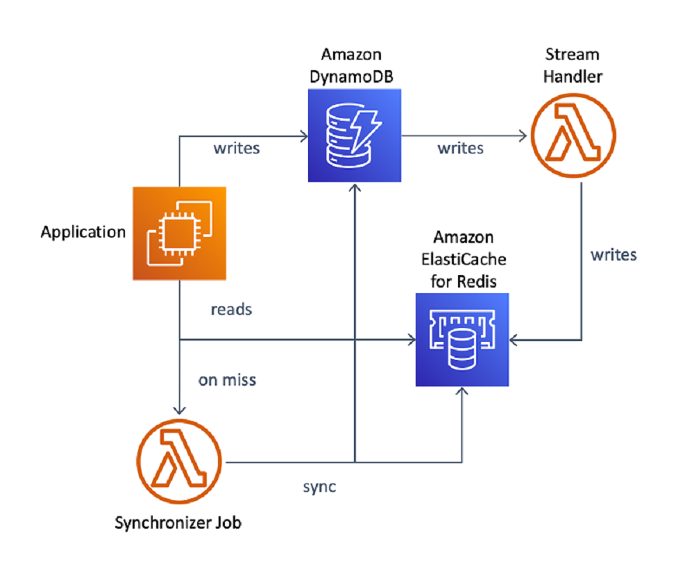
information from a secondary database within the occasion of knowledge loss. For instance, a
catalog microservice in an e-commerce procuring software might need to
fetch merchandise particulars from Redis to serve tens of millions of web page views per
second. In an optimum setup, the service shops all information in Redis, however
as a substitute has to make use of an information pipeline to ingest catalog information right into a
separate database, like DynamoDB, earlier than triggering writes to Redis
by way of a DynamoDB stream. When the service detects that an merchandise is
lacking in Redis—an indication of knowledge loss—a separate job should reconcile
Redis in opposition to DynamoDB.
That is overly advanced for many, and a database-grade Redis providing
would drastically cut back this undifferentiated heavy lifting. That is what
motivated us to construct Amazon MemoryDB for
Redis, a strongly-consistent,
Redis-compatible, in-memory database service for ultra-fast efficiency.
However extra on that in a minute, I’d wish to first cowl slightly extra
in regards to the inherent challenges with Redis earlier than stepping into how we
solved for this with MemoryDB.
Redis’ best-effort consistency #
Even in a replicated or clustered setup, Redis is weakly
constant with an unbounded inconsistency window, which means it’s
by no means assured that an observer will see an up to date worth after a
write. Why is that this? Redis was designed to be extremely quick, however made
tradeoffs to enhance latency at the price of consistency. First, information is
saved in reminiscence. Any course of loss (corresponding to an influence failure) means a
node loses all information and requires restore from scratch, which is
computationally costly and time-consuming. One failure lowers the
resilience of the complete system because the probability of cascading failure
(and everlasting information loss) turns into greater. Sturdiness isn’t the one
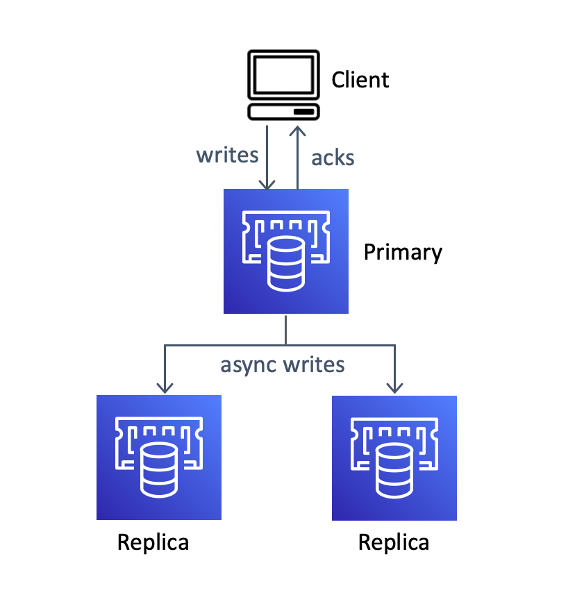
requirement to enhance consistency. Redis’ replication system is
asynchronous: all updates to main nodes are replicated after being
dedicated. Within the occasion of a failure of a main, acknowledged updates
could be misplaced. This sequence permits Redis to reply shortly, however prevents
the system from sustaining sturdy consistency throughout failures. For
instance, in our catalog microservice, a worth replace to an merchandise could also be
reverted after a node failure, inflicting the applying to promote an
outdated worth. This sort of inconsistency is even more durable to detect than
dropping a complete merchandise.
Redis has a lot of mechanisms for tunable consistency, however none can
assure sturdy consistency in a extremely accessible, distributed
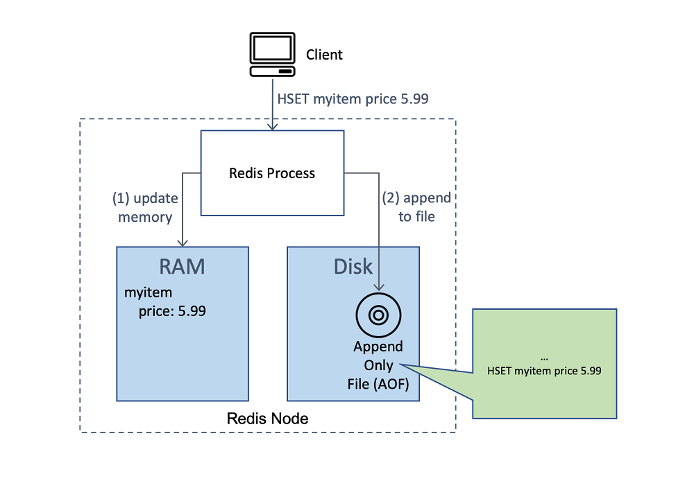
setup. For persistence to disk, Redis helps an Append-Solely-File (AOF)
characteristic the place all replace instructions are written to disk in a file referred to as
a transaction log. Within the occasion of a course of restart, the engine will
re-run all of those logged instructions and reconstruct the info construction
state. As a result of this restoration course of takes time, AOF is primarily helpful
for configurations that may afford to sacrifice availability. When used
with replication, information loss can happen if a failover is initiated when a
main fails as a substitute of replaying from the AOF due to asynchronous
replication.
Redis can failover to any accessible duplicate when a failure happens. This
permits it to be extremely accessible, but additionally signifies that to keep away from dropping an
replace, all replicas should course of it. To make sure this, some clients
use a command known as WAIT, which may block the calling consumer till all
replicas have acknowledged an replace. This method additionally doesn’t flip
Redis right into a strongly constant system. First, it permits reads to information
not but absolutely dedicated by the cluster (a “soiled learn”). For instance, an
order in our retail procuring software might present as being efficiently
positioned despite the fact that it might nonetheless be misplaced. Second, writes will fail when
any node fails, lowering availability considerably. These caveats are
nonstarters for an enterprise-grade database.
MemoryDB: It’s all in regards to the replication log #
We constructed MemoryDB to offer each sturdy consistency and excessive
availability so clients can use it as a sturdy main database. We
knew it needed to be absolutely appropriate with Redis so clients who already
leverage Redis information constructions and instructions can proceed to make use of them.
Like we did with Amazon Aurora, we began designing MemoryDB by
decomposing the stack into a number of layers. First, we chosen Redis as
an in-memory execution engine for efficiency and compatibility. Reads
and writes in MemoryDB nonetheless entry Redis’ in-memory information
constructions. Then, we constructed a model new on-disk storage and replication
system to unravel the deficiencies in Redis. This method makes use of a
distributed transaction log to manage each sturdiness and
replication. We offloaded this log from the in-memory cluster so it
scales independently. Clusters with fewer nodes profit from the identical
sturdiness and consistency properties as bigger clusters.
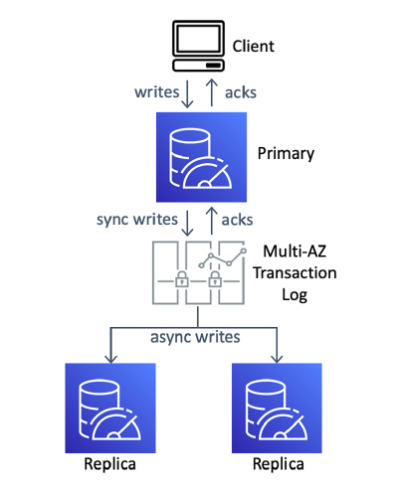
The distributed transaction log helps strongly constant append
operations and shops information encrypted in a number of Availability Zones
(AZs) for each sturdiness and availability. Each write to Redis is
saved on disk in a number of AZs earlier than it turns into seen to a
consumer. This transaction log is then used as a replication bus: the
main node data its updates to the log, after which replicas eat
them. This allows replicas to have an ultimately constant view of the
information on the first, offering Redis-compatible entry strategies.
With a sturdy transaction log in place, we shifted focus to consistency
and excessive availability. MemoryDB helps lossless failover. We do that
by coordinating failover actions utilizing the identical transaction log that
retains monitor of replace instructions. A reproduction in steady-state is ultimately
constant, however will grow to be strongly constant throughout promotion to
main. It should append to the transaction log to failover and is
due to this fact assured to watch all prior dedicated writes. Earlier than
accepting consumer instructions as main, it applies unobserved modifications,
which permits the system to offer linearizable consistency for each
reads and writes throughout failovers. This coordination additionally ensures that
there’s a single main, stopping “break up mind” issues typical in
different database methods beneath sure networking partitions, the place writes
could be mistakenly accepted concurrently by two nodes solely to be later
thrown away.
Redis-compatible #
We leveraged Redis as an in-memory execution system inside MemoryDB, and
wanted to seize replace instructions on a Redis main to retailer them in
the transaction log. A standard sample is to intercept requests previous to
execution, retailer them within the transaction log, and as soon as dedicated, permit
nodes to execute them from the log. That is known as
energetic replication and is commonly used with consensus algorithms like
Paxos or Raft. In energetic replication, instructions within the log should apply
deterministically on all nodes, or totally different nodes might find yourself with
totally different outcomes. Redis, nonetheless, has many sources of nondeterminism,
corresponding to a command to take away a random ingredient from a set, or to execute
arbitrary scripts. An order microservice might solely permit orders for a brand new
product to be positioned after a launch day. It might do that utilizing a LUA
script, which rejects orders when submitted too early primarily based on Redis’
clock. If this script have been run on varied replicas throughout replication,
some nodes might settle for the order primarily based on their native clock and a few might
not, inflicting divergence. MemoryDB as a substitute depends on passive
replication, the place a single main executes a command and replicates
its ensuing results, making them deterministic. On this instance, the
main executes the LUA script, decides whether or not or to not settle for the
order, after which replicates its choice to the remaining replicas. This
approach permits MemoryDB to help the complete Redis command set.
With passive replication, a Redis main node executes writes and
updates in-memory state earlier than a command is durably dedicated to the
transaction log. The first might determine to simply accept an order, nevertheless it might
nonetheless fail till dedicated to the transaction log, so this alteration should
stay invisible till the transaction log accepts it. Counting on
key-level locking to stop entry to the merchandise throughout this time would
restrict general concurrency and improve latency. As a substitute, in MemoryDB we
proceed executing and buffering responses, however delay these responses
from being despatched to purchasers till the dependent information is absolutely
dedicated. If the order microservice submits two consecutive instructions to
place an order after which retrieve the order standing, it could count on the
second command to return a sound order standing. MemoryDB will course of
each instructions upon receipt, executing on essentially the most up-to-date information, however
will delay sending each responses till the transaction log has
confirmed the write. This enables the first node to attain
linearizable consistency with out sacrificing throughput.
We offloaded one extra duty from the core execution
engine: snapshotting. A sturdy transaction log of all updates to the
database continues to develop over time, prolonging restore time when a
node fails and must be repaired. An empty node would want to replay
all of the transactions for the reason that database was created. On occasion,
we compact this log to permit the restore course of to finish shortly. In
MemoryDB, we constructed a system to compact the log by producing a snapshot
offline. By eradicating snapshot duties from the operating cluster,
extra RAM is devoted to buyer information storage and efficiency will likely be
constant.
Goal-built database for velocity #
The world strikes quicker and quicker each day, which suggests information, and the
methods that help that information, have to maneuver even quicker nonetheless. Now,
when clients want an ultra-fast, sturdy database to course of and retailer
real-time information, they now not need to danger information loss. With Amazon
MemoryDB for Redis, AWS lastly gives sturdy consistency for Redis so
clients can deal with what they need to construct for the longer term.
MemoryDB for Redis can be utilized as a system of report that synchronously
persists each write request to disk throughout a number of AZs for sturdy
consistency and excessive availability. With this structure, write
latencies grow to be single-digit milliseconds as a substitute of microseconds, however
reads are served from native reminiscence for sub-millisecond
efficiency. MemoryDB is a drop-in alternative for any Redis workload
and helps the identical information constructions and instructions as open supply
Redis. Clients can select to execute strongly constant instructions
in opposition to main nodes or ultimately constant instructions in opposition to
replicas. I encourage clients searching for a strongly constant,
sturdy Redis providing to think about Amazon MemoryDB for Redis, whereas
clients who’re searching for sub-millisecond efficiency on each writes
and reads with ephemeral workloads ought to take into account Amazon ElastiCache
for Redis.
To be taught extra, go to the Amazon MemoryDB
documentation. When you
have any questions, you possibly can contact the staff immediately
at memorydb-help@amazon.com.

{kind=link}