


|
I’m happy to announce as we speak the provision of Amazon File Cache, a brand new high-speed cache service on AWS designed for processing file knowledge saved in disparate places—together with on premises. File Cache accelerates and simplifies your most demanding cloud bursting and hybrid workflows by giving your purposes entry to information utilizing a quick and acquainted POSIX interface, irrespective of if the unique information reside on premises on any file system that may be accessed by way of NFS v3 or on Amazon Easy Storage Service (Amazon S3).
Think about you’ve a big knowledge set on on-premises storage infrastructure, and your end-of-month reporting usually takes two to 3 days to run. You wish to transfer that occasional workload to the cloud to run it on bigger machines with extra CPU and reminiscence to cut back the processing time. However you’re not prepared to maneuver the info set to the cloud but.
Think about one other state of affairs the place you’ve entry to a big knowledge set on Amazon Easy Storage Service (Amazon S3), unfold throughout a number of Areas. Your utility that desires to take advantage of this knowledge set is coded for conventional (POSIX) file system entry and makes use of command line instruments like awk, sed, pipes, and so forth. Your utility requires file entry with sub-millisecond latencies. You can’t replace the supply code to make use of the S3 API.
File Cache helps to deal with these use circumstances and plenty of others, take into consideration administration and transformation of video information, AI/ML knowledge units, and so forth. File Cache creates a file system–based mostly cache in entrance of both NFS v3 file methods or S3 buckets in a number of Areas. It transparently masses file content material and metadata (such because the file title, dimension, and permissions) from the origin and presents it to your purposes as a conventional file system. File Cache routinely releases the much less just lately used cached information to make sure essentially the most energetic information can be found within the cache to your purposes.
You’ll be able to hyperlink as much as eight NFS file methods or eight S3 buckets to a cache, and they are going to be uncovered as a unified set of information and directories. You’ll be able to entry the cache from quite a lot of AWS compute providers, equivalent to digital machines or containers. The connection between File Cache and your on-premises infrastructure makes use of your current community connection, based mostly on AWS Direct Join and/or Web site-to-Web site VPN.
When utilizing File Cache, your purposes profit from constant, sub-millisecond latencies, as much as tons of of GB/s of throughput, and as much as thousands and thousands of operations per second. Similar to with different storage providers, equivalent to Amazon Elastic Block Retailer (Amazon EBS), the efficiency will depend on the scale of the cache. The cache dimension may be expanded to petabyte scale, with a minimal dimension of 1.2 TiB.
Let’s See How It Works
To indicate you the way it works, I create a file cache on high of two current Amazon FSx for OpenZFS file methods. In a real-world state of affairs, it’s seemingly you’ll create caches on high of on-premises file methods. I select FSx for OpenZFS for the demo as a result of I don’t have an on-premises knowledge middle at hand (I ought to perhaps put money into seb-west-1). Each demo OpenZFS file methods are accessible from a non-public subnet in my AWS account. Lastly, I entry the cache from an EC2 Linux occasion.
I open my browser and navigate to the AWS Administration Console. I seek for “Amazon FSx” within the console search bar and click on on Caches within the left navigation menu. Alternatively, I’m going on to the File Cache part of the console. To get began, I choose Create cache.
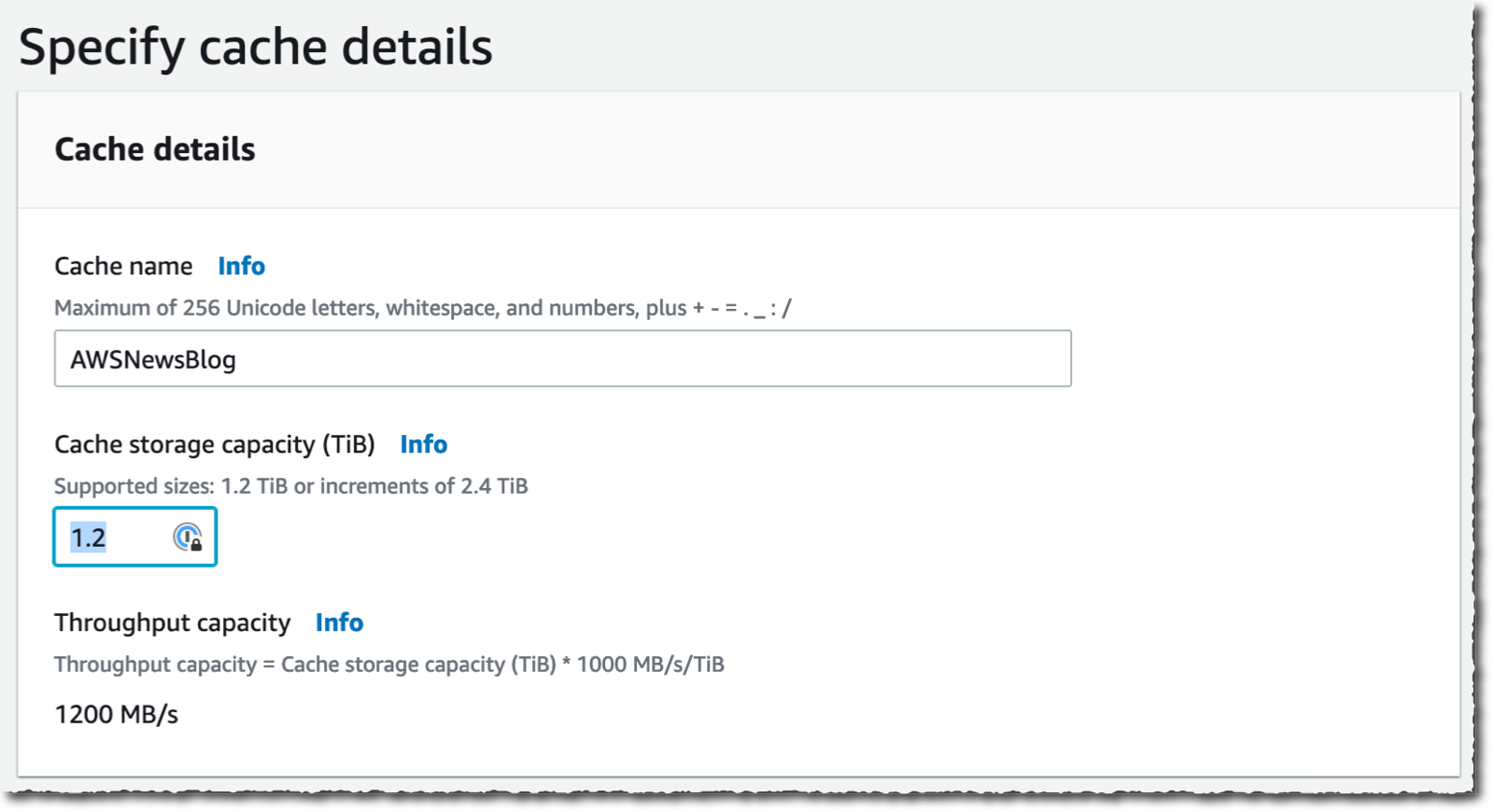
 I enter a Cache title for my cache (AWSNewsBlog for this demo) and a Cache storage capability. The storage capability is expressed in tebibytes. The minimal worth is 1.2 TiB or increments of two.4 TiB. Discover that the Throughput capability will increase as you select giant cache sizes.
I enter a Cache title for my cache (AWSNewsBlog for this demo) and a Cache storage capability. The storage capability is expressed in tebibytes. The minimal worth is 1.2 TiB or increments of two.4 TiB. Discover that the Throughput capability will increase as you select giant cache sizes.
 I verify and settle for the default values supplied for Networking and Encryption. For networking, I would choose a VPC, subnet, and safety group to affiliate with my cache community interface. It is strongly recommended to deploy the cache in the identical subnet as your compute service to attenuate the latency when accessing information. For encryption, I would use an AWS KMS-managed key (the default) or choose my very own.
I verify and settle for the default values supplied for Networking and Encryption. For networking, I would choose a VPC, subnet, and safety group to affiliate with my cache community interface. It is strongly recommended to deploy the cache in the identical subnet as your compute service to attenuate the latency when accessing information. For encryption, I would use an AWS KMS-managed key (the default) or choose my very own.
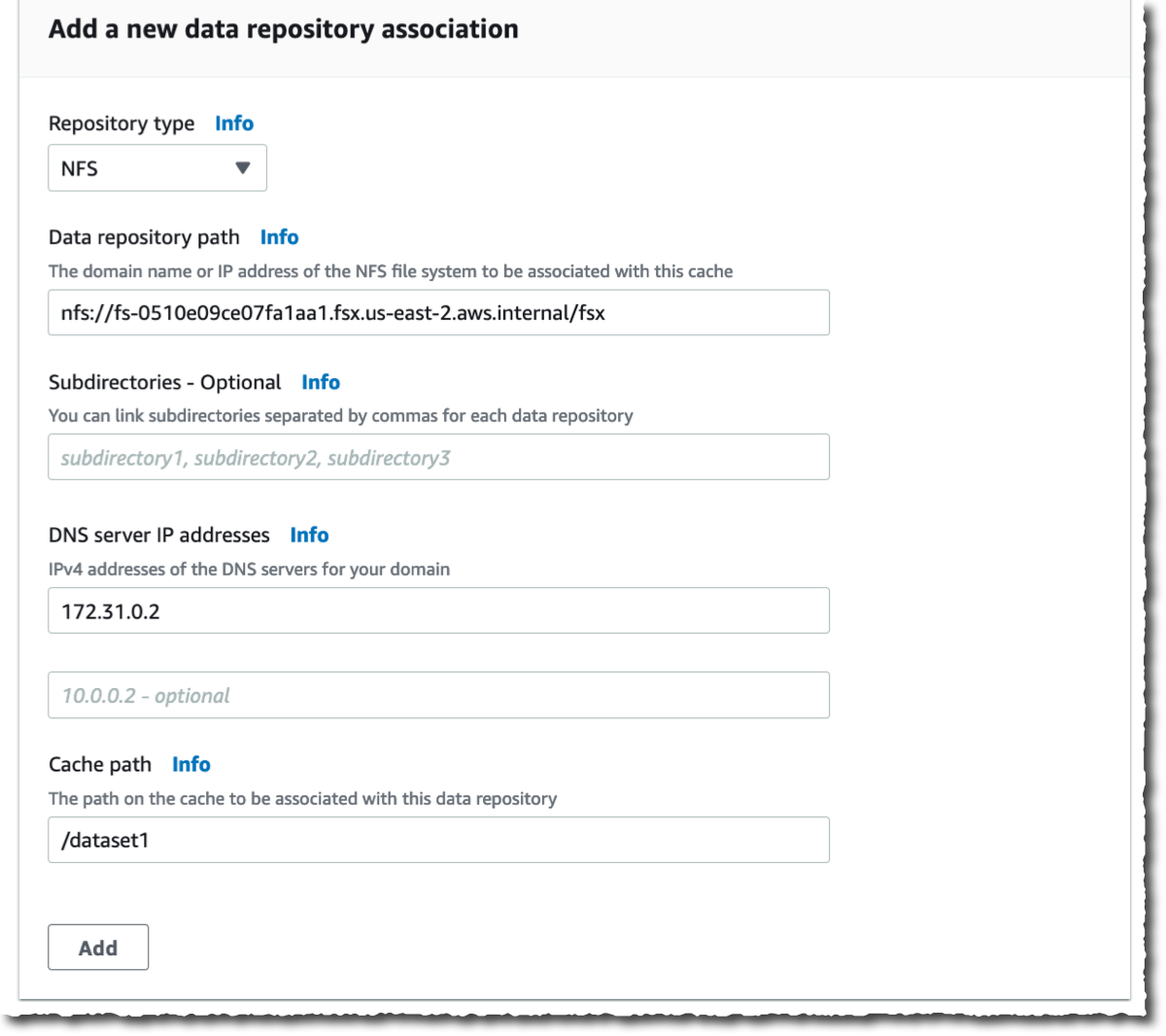
Then, I create Information Repository Affiliation. That is the hyperlink between the cache and a knowledge supply. A knowledge supply may be an NFS file system or an S3 bucket or prefix. I would create as much as eight knowledge repository associations for one cache. All Information Repository Associations for a cache have the identical kind: they’re all NFS v3 or all S3. For those who want each, you may create two caches.
On this demo, I select to hyperlink two OpenZFS file methods on my AWS account. You’ll be able to hyperlink to any NFS v3 servers, together with those you have already got on premises. Cache path lets you select the place the supply file system will probably be mounted within the cache. The Information repository path is the URL to your NFS v3 or S3 knowledge repository. The format is nfs://hostname/path or s3://bucketname/path.
The DNS server IP addresses permits File Cache to resolve the DNS title of your NFS server. That is helpful when DNS decision is non-public, like in my instance. When you find yourself associating NFS v3 servers deployed in a VPC, and when utilizing the AWS-provided DNS server, the DNS server IP tackle of your VPC is the VPC Vary + two. In my instance, my VPC CIDR vary is 172.31.0.0, therefore the DNS server IP tackle is 172.31.0.2.
Don’t forget to click on on the Add button! In any other case, your enter is ignored. You’ll be able to repeat the operation so as to add extra knowledge repositories.
 |
 |
As soon as I’ve entered my two knowledge repositories, I choose Subsequent, and I evaluate my selections. When I’m prepared, I choose Create cache.

After a couple of minutes, the cache standing turns into ✅ Accessible.

The final half is to mount the cache on the machine the place my workload is deployed. File Cache makes use of Lustre behind the scene. I’ve to put in the Lustre shopper for Linux first, as defined in our documentation. As soon as accomplished, I choose the Connect button on the console to obtain the directions to obtain and set up the Lustre shopper and to mount the cache file system. To take action, I hook up with an EC2 occasion operating in the identical VPC. Then I kind:
To take action, I hook up with an EC2 occasion operating in the identical VPC. Then I kind:
sudo mount -t lustre -o relatime,flock file_cache_dns_name@tcp:/mountname /mntThis command mounts my cache with two choices:
relatime– Maintainsatime(inode entry occasions) knowledge, however not for every time {that a} file is accessed. With this feature enabled,atimeknowledge is written to disk provided that the file has been modified because theatimeknowledge was final up to date (mtime) or if the file was final accessed greater than a sure period of time in the past (in the future by default).relatimeis required for automated cache eviction to work correctly.flock– Permits file locking to your cache. For those who don’t need file locking enabled, use the mount command with out flock.
As soon as mounted, processes operating on my EC2 occasion can entry information within the cache as ordinary. As I outlined at cache creation time, the primary ZFS file system is out there contained in the cache at /dataset1, and the second ZFS file system is out there as /dataset2.
$ echo "Hey File Cache World" > /mnt/zsf1/greetings
$ sudo mount -t lustre -o relatime,flock fc-0280000000001.fsx.us-east-2.aws.inner@tcp:/r3xxxxxx /mnt/cache
$ ls -al /mnt/cache
complete 98
drwxr-xr-x 5 root root 33280 Sep 21 14:37 .
drwxr-xr-x 2 root root 33280 Sep 21 14:33 dataset1
drwxr-xr-x 2 root root 33280 Sep 21 14:37 dataset2
$ cat /mnt/cache/dataset1/greetings
Hey File Cache World
I can observe and measure the exercise and the well being of my caches utilizing Amazon CloudWatch metrics and AWS CloudTrail log monitoring.
CloudWatch metrics for a File Cache useful resource are organized into three classes:
- Entrance-end I/O metrics
- Backend I/O metrics
- Cache front-end utilization metrics
As ordinary, I can create dashboards or outline alarms to learn when metrics attain thresholds that I outlined.
Issues To Hold In Thoughts
There are a few key factors to remember when utilizing or planning to make use of File Cache.
First, File Cache encrypts knowledge at relaxation and helps encryption of knowledge in transit. Your knowledge is at all times encrypted at relaxation utilizing keys managed in AWS Key Administration Service (AWS KMS). You need to use both service-owned keys or your individual keys (customer-managed CMKs).
Second, File Cache gives two choices for importing knowledge out of your knowledge repositories to the cache: lazy load and preload. Lazy load imports knowledge on demand if it’s not already cached, and preload imports knowledge at consumer request earlier than you begin your workload. Lazy loading is the default. It is sensible for many workloads because it permits your workload to begin with out ready for metadata and knowledge to be imported to the cache. Pre loading is useful when your entry sample is delicate to first-byte latencies.
Pricing and Availability
There are not any upfront or fixed-price prices when utilizing File Cache. You might be billed for the provisioned cache storage capability and metadata storage capability. The pricing web page has the main points. Along with File Cache itself, you pay for S3 request prices, AWS Direct Join costs, and the standard knowledge switch costs for inter-AZ, inter-Area, and web egress site visitors between File Cache and the info sources.
File Cache is out there in US East (Ohio), US East (N. Virginia), US West (Oregon), Asia Pacific (Singapore), Asia Pacific (Sydney), Asia Pacific (Tokyo), Canada (Central), Europe (Frankfurt), Europe (Eire), and Europe (London).
Now go construct and create your first file cache as we speak!

{kind=link}