

Sturdy algorithm design is the spine of techniques throughout Google, notably for our ML and AI fashions. Therefore, creating algorithms with improved effectivity, efficiency and pace stays a excessive precedence because it empowers companies starting from Search and Adverts to Maps and YouTube. Google Analysis has been on the forefront of this effort, creating many inventions from privacy-safe suggestion techniques to scalable options for large-scale ML. In 2022, we continued this journey, and superior the state-of-the-art in a number of associated areas. Right here we spotlight our progress in a subset of those, together with scalability, privateness, market algorithms, and algorithmic foundations.
Scalable algorithms: Graphs, clustering, and optimization
As the necessity to deal with large-scale datasets will increase, scalability and reliability of complicated algorithms that additionally exhibit improved explainability, robustness, and pace stay a excessive precedence. We continued our efforts in creating new algorithms for dealing with giant datasets in varied areas, together with unsupervised and semi-supervised studying, graph-based studying, clustering, and large-scale optimization.
An necessary part of such techniques is to construct a similarity graph — a nearest-neighbor graph that represents similarities between objects. For scalability and pace, this graph ought to be sparse with out compromising high quality. We proposed a 2-hop spanner method, referred to as STAR, as an environment friendly and distributed graph constructing technique, and confirmed the way it considerably decreases the variety of similarity computations in concept and apply, constructing a lot sparser graphs whereas producing high-quality graph studying or clustering outputs. For example, for graphs with 10T edges, we reveal ~100-fold enhancements in pairwise similarity comparisons and important operating time speedups with negligible high quality loss. We had beforehand utilized this concept to develop massively parallel algorithms for metric, and minimum-size clustering. Extra broadly within the context of clustering, we developed the primary linear-time hierarchical agglomerative clustering (HAC) algorithm in addition to DBSCAN, the primary parallel algorithm for HAC with logarithmic depth, which achieves 50x speedup on 100B-edge graphs. We additionally designed improved sublinear algorithms for various flavors of clustering issues equivalent to geometric linkage clustering, constant-round correlation clustering, and absolutely dynamic k-clustering.
Impressed by the success of multi-core processing (e.g., GBBS), we launched into a mission to develop graph mining algorithms that may deal with graphs with 100B edges on a single multi-core machine. The massive problem right here is to attain quick (e.g., sublinear) parallel operating time (i.e., depth). Following our earlier work for group detection and correlation clustering, we developed an algorithm for HAC, referred to as ParHAC, which has provable polylogarithmic depth and near-linear work and achieves a 50x speedup. For example, it took ParHAC solely ~10 minutes to seek out an approximate affinity hierarchy over a graph of over 100B edges, and ~3 hours to seek out the total HAC on a single machine. Following our earlier work on distributed HAC, we use these multi-core algorithms as a subroutine inside our distributed algorithms with a purpose to deal with tera-scale graphs.
We additionally had a variety of fascinating outcomes on graph neural networks (GNN) in 2022. We offered a model-based taxonomy that unified many graph studying strategies. As well as, we found insights for GNN fashions from their efficiency throughout hundreds of graphs with various construction (proven under). We additionally proposed a new hybrid structure to beat the depth necessities of present GNNs for fixing basic graph issues, equivalent to shortest paths and the minimal spanning tree.
 |
| Relative efficiency outcomes of three GNN variants (GCN, APPNP, FiLM) throughout 50,000 distinct node classification datasets in GraphWorld. We discover that educational GNN benchmark datasets exist in areas the place mannequin rankings don’t change. GraphWorld can uncover beforehand unexplored graphs that reveal new insights about GNN architectures. |
Moreover, to deliver a few of these many advances to the broader group, we had three releases of our flagship modeling library for constructing graph neural networks in TensorFlow (TF-GNN). Highlights embrace a mannequin library and mannequin orchestration API to make it simple to compose GNN options. Following our NeurIPS’20 workshop on Mining and Studying with Graphs at Scale, we ran a workshop on graph-based studying at ICML’22, and a tutorial for GNNs in TensorFlow at NeurIPS’22.
In “Sturdy Routing Utilizing Electrical Flows”, we offered a latest paper that proposed a Google Maps resolution to effectively compute alternate paths in highway networks which can be immune to failures (e.g., closures, incidents). We reveal the way it considerably outperforms the state-of-the-art plateau and penalty strategies on real-world highway networks.
 |
| Instance of how we assemble {the electrical} circuit similar to the highway community. The present will be decomposed into three flows, i1, i2 and that i3, every of which corresponds to a viable alternate path from Fremont, CA to San Rafael, CA. |
On the optimization entrance, we open-sourced Vizier, our flagship blackbox optimization and hyperparameter tuning library at Google. We additionally developed new strategies for linear programming (LP) solvers that handle scalability limits attributable to their reliance on matrix factorizations, which restricts the chance for parallelism and distributed approaches. To this finish, we open-sourced a primal-dual hybrid gradient (PDHG) resolution for LP referred to as primal-dual linear programming (PDLP), a brand new first-order solver for large-scale LP issues. PDLP has been used to resolve real-world issues with as many as 12B non-zeros (and an inside distributed model scaled to 92B non-zeros). PDLP’s effectiveness is because of a mix of theoretical developments and algorithm engineering.
 |
| With OSS Vizier, a number of purchasers every ship a “Recommend” request to the Service API, which produces Recommendations for the purchasers utilizing Pythia insurance policies. The purchasers consider these strategies and return measurements. All transactions are saved to permit fault-tolerance. |
Privateness and federated studying
Respecting consumer privateness whereas offering high-quality companies stays a prime precedence for all Google techniques. Analysis on this space spans many merchandise and makes use of ideas from differential privateness (DP) and federated studying.
Initially, we’ve got made a wide range of algorithmic advances to handle the issue of coaching giant neural networks with DP. Constructing on our earlier work, which enabled us to launch a DP neural community based mostly on the DP-FTRL algorithm, we developed the matrix factorization DP-FTRL strategy. This work demonstrates that one can design a mathematical program to optimize over a big set of potential DP mechanisms to seek out these greatest suited to particular studying issues. We additionally set up margin ensures which can be unbiased of the enter characteristic dimension for DP studying of neural networks and kernel-based strategies. We additional prolong this idea to a broader vary of ML duties, matching baseline efficiency with 300x much less computation. For fine-tuning of enormous fashions, we argued that after pre-trained, these fashions (even with DP) basically function over a low-dimensional subspace, therefore circumventing the curse of dimensionality that DP imposes.

On the algorithmic entrance, for estimating the entropy of a high-dimensional distribution, we obtained native DP mechanisms (that work even when as little as one bit per pattern is out there) and environment friendly shuffle DP mechanisms. We proposed a extra correct technique to concurrently estimate the top-ok hottest objects within the database in a personal method, which we employed within the Plume library. Furthermore, we confirmed a near-optimal approximation algorithm for DP clustering within the massively parallel computing (MPC) mannequin, which additional improves on our earlier work for scalable and distributed settings.
One other thrilling analysis route is the intersection of privateness and streaming. We obtained a near-optimal approximation-space trade-off for the non-public frequency moments and a brand new algorithm for privately counting distinct parts within the sliding window streaming mannequin. We additionally offered a normal hybrid framework for learning adversarial streaming.
Addressing functions on the intersection of safety and privateness, we developed new algorithms which can be safe, non-public, and communication-efficient, for measuring cross-publisher attain and frequency. The World Federation of Advertisers has adopted these algorithms as a part of their measurement system. In subsequent work, we developed new protocols which can be safe and personal for computing sparse histograms within the two-server mannequin of DP. These protocols are environment friendly from each computation and communication factors of view, are considerably higher than what customary strategies would yield, and mix instruments and strategies from sketching, cryptography and multiparty computation, and DP.
Whereas we’ve got skilled BERT and transformers with DP, understanding coaching instance memorization in giant language fashions (LLMs) is a heuristic technique to consider their privateness. Particularly, we investigated when and why LLMs neglect (doubtlessly memorized) coaching examples throughout coaching. Our findings counsel that earlier-seen examples could observe privateness advantages on the expense of examples seen later. We additionally quantified the diploma to which LLMs emit memorized coaching knowledge.
Market algorithms and causal inference
We additionally continued our analysis in enhancing on-line marketplaces in 2022. For instance, an necessary latest space in advert public sale analysis is the research of auto-bidding internet marketing the place the vast majority of bidding occurs through proxy bidders that optimize higher-level goals on behalf of advertisers. The complicated dynamics of customers, advertisers, bidders, and advert platforms results in non-trivial issues on this area. Following our earlier work in analyzing and enhancing mechanisms below auto-bidding auctions, we continued our analysis in enhancing on-line marketplaces within the context of automation whereas taking totally different features into consideration, equivalent to consumer expertise and advertiser budgets. Our findings counsel that correctly incorporating ML recommendation and randomization strategies, even in non-truthful auctions, can robustly enhance the general welfare at equilibria amongst auto-bidding algorithms.
 |
| Construction of auto-bidding on-line advertisements system. |
Past auto-bidding techniques, we additionally studied public sale enhancements in complicated environments, e.g., settings the place consumers are represented by intermediaries, and with Wealthy Adverts the place every advert will be proven in one among a number of potential variants. We summarize our work on this space in a latest survey. Past auctions, we additionally examine using contracts in multi-agent and adversarial settings.
On-line stochastic optimization stays an necessary a part of internet marketing techniques with utility in optimum bidding and price range pacing. Constructing on our long-term analysis in on-line allocation, we not too long ago blogged about twin mirror descent, a brand new algorithm for on-line allocation issues that’s easy, sturdy, and versatile. This state-of-the-art algorithm is powerful towards a variety of adversarial and stochastic enter distributions and may optimize necessary goals past financial effectivity, equivalent to equity. We additionally present that by tailoring twin mirror descent to the particular construction of the more and more fashionable return-on-spend constraints, we are able to optimize advertiser worth. Twin mirror descent has a variety of functions and has been used over time to assist advertisers receive extra worth by way of higher algorithmic choice making.
 |
| An summary of the twin mirror descent algorithm. |
Moreover, following our latest work on the interaction of ML, mechanism design and markets, we investigated transformers for uneven public sale design, designed utility-maximizing methods for no-regret studying consumers, and developed new studying algorithms to bid or to value in auctions.
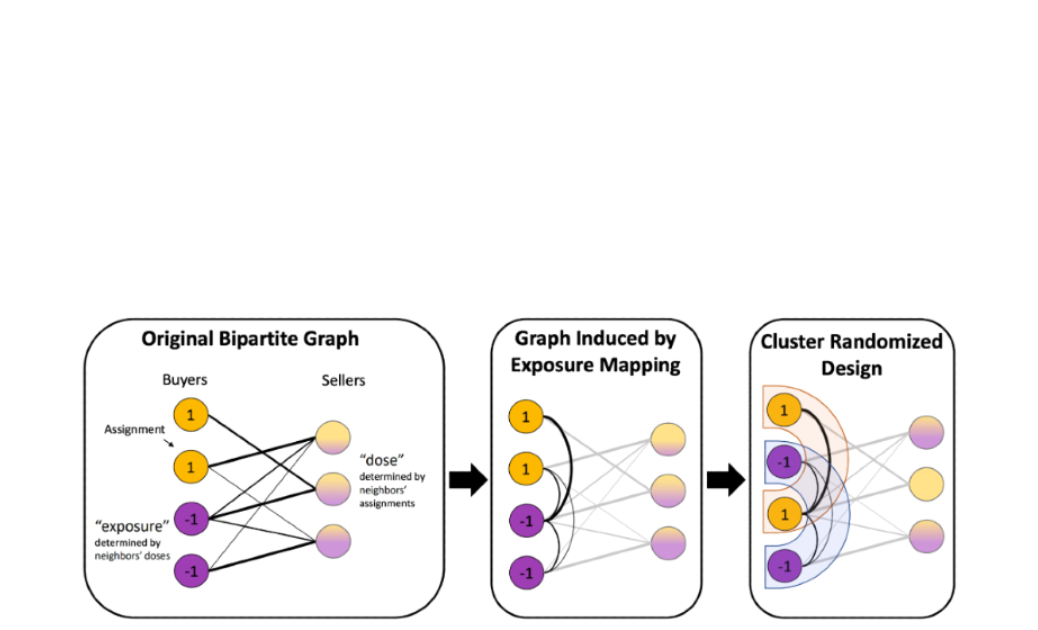
A vital part of any refined on-line service is the flexibility to experimentally measure the response of customers and different gamers to new interventions. A significant problem of estimating these causal results precisely is dealing with complicated interactions — or interference — between the management and therapy items of those experiments. We mixed our graph clustering and causal inference experience to develop the outcomes of our earlier work on this space, with improved outcomes below a versatile response mannequin and a brand new experimental design that’s simpler at decreasing these interactions when therapy assignments and metric measurements happen on the identical aspect of a bipartite platform. We additionally confirmed how artificial management and optimization strategies will be mixed to design extra highly effective experiments, particularly in small knowledge regimes.
Algorithmic foundations and concept
Lastly, we continued our basic algorithmic analysis by tackling long-standing open issues. A surprisingly concise paper affirmatively resolved a four-decade previous open query on whether or not there’s a mechanism that ensures a relentless fraction of the gains-from-trade attainable every time purchaser’s worth weakly exceeds vendor’s price. One other latest paper obtained the state-of-the-art approximation for the basic and highly-studied k-means drawback. We additionally improved the very best approximation for correlation clustering breaking the barrier approximation issue of two. Lastly, our work on dynamic knowledge constructions to resolve min-cost and different community movement issues has contributed to a breakthrough line of labor in adapting steady optimization strategies to resolve basic discrete optimization issues.
Concluding ideas
Designing efficient algorithms and mechanisms is a vital part of many Google techniques that must deal with tera-scale knowledge robustly with vital privateness and security concerns. Our strategy is to develop algorithms with strong theoretical foundations that may be deployed successfully in our product techniques. As well as, we’re bringing many of those advances to the broader group by open-sourcing a few of our most novel developments and by publishing the superior algorithms behind them. On this submit, we lined a subset of algorithmic advances in privateness, market algorithms, scalable algorithms, graph-based studying, and optimization. As we transfer towards an AI-first Google with additional automation, creating sturdy, scalable, and privacy-safe ML algorithms stays a excessive precedence. We’re enthusiastic about creating new algorithms and deploying them extra broadly.
Acknowledgements
This submit summarizes analysis from numerous groups and benefited from enter from a number of researchers together with Gagan Aggarwal, Amr Ahmed, David Applegate, Santiago Balseiro, Vincent Cohen-addad, Yuan Deng, Alessandro Epasto, Matthew Fahrbach, Badih Ghazi, Sreenivas Gollapudi, Rajesh Jayaram, Ravi Kumar, Sanjiv Kumar, Silvio Lattanzi, Kuba Lacki, Brendan McMahan, Aranyak Mehta, Bryan Perozzi, Daniel Ramage, Ananda Theertha Suresh, Andreas Terzis, Sergei Vassilvitskii, Di Wang, and Tune Zuo. Particular because of Ravi Kumar for his contributions to this submit.
Google Analysis, 2022 & past
This was the fifth weblog submit within the “Google Analysis, 2022 & Past” collection. Different posts on this collection are listed within the desk under:
| * Articles will likely be linked as they’re launched. |

{kind=link}