
Google’s AI for Social Good crew consists of researchers, engineers, volunteers, and others with a shared concentrate on optimistic social impression. Our mission is to exhibit AI’s societal profit by enabling real-world worth, with initiatives spanning work in public well being, accessibility, disaster response, local weather and vitality, and nature and society. We imagine that the easiest way to drive optimistic change in underserved communities is by partnering with change-makers and the organizations they serve.
On this weblog put up we talk about work achieved by Undertaking Euphonia, a crew inside AI for Social Good, that goals to enhance computerized speech recognition (ASR) for individuals with disordered speech. For individuals with typical speech, an ASR mannequin’s phrase error price (WER) could be lower than 10%. However for individuals with disordered speech patterns, similar to stuttering, dysarthria and apraxia, the WER might attain 50% and even 90% relying on the etiology and severity. To assist tackle this downside, we labored with greater than 1,000 contributors to gather over 1,000 hours of disordered speech samples and used the information to indicate that ASR personalization is a viable avenue for bridging the efficiency hole for customers with disordered speech. We have proven that personalization could be profitable with as little as 3-4 minutes of coaching speech utilizing layer freezing strategies.
This work led to the event of Undertaking Relate for anybody with atypical speech who may gain advantage from a customized speech mannequin. In-built partnership with Google’s Speech crew, Undertaking Relate permits individuals who discover it arduous to be understood by different individuals and expertise to coach their very own fashions. Individuals can use these personalised fashions to speak extra successfully and achieve extra independence. To make ASR extra accessible and usable, we describe how we fine-tuned Google’s Common Speech Mannequin (USM) to higher perceive disordered speech out of the field, with out personalization, to be used with digital assistant applied sciences, dictation apps, and in conversations.
Addressing the challenges
Working intently with Undertaking Relate customers, it grew to become clear that personalised fashions could be very helpful, however for a lot of customers, recording dozens or a whole bunch of examples could be difficult. As well as, the personalised fashions didn’t at all times carry out effectively in freeform dialog.
To deal with these challenges, Euphonia’s analysis efforts have been specializing in speaker impartial ASR (SI-ASR) to make fashions work higher out of the field for individuals with disordered speech in order that no extra coaching is critical.
Prompted Speech dataset for SI-ASR
Step one in constructing a sturdy SI-ASR mannequin was to create consultant dataset splits. We created the Prompted Speech dataset by splitting the Euphonia corpus into prepare, validation and take a look at parts, whereas making certain that every break up spanned a variety of speech impairment severity and underlying etiology and that no audio system or phrases appeared in a number of splits. The coaching portion consists of over 950k speech utterances from over 1,000 audio system with disordered speech. The take a look at set accommodates round 5,700 utterances from over 350 audio system. Speech-language pathologists manually reviewed the entire utterances within the take a look at set for transcription accuracy and audio high quality.
Actual Dialog take a look at set
Unprompted or conversational speech differs from prompted speech in a number of methods. In dialog, individuals communicate sooner and enunciate much less. They repeat phrases, restore misspoken phrases, and use a extra expansive vocabulary that’s particular and private to themselves and their group. To enhance a mannequin for this use case, we created the Actual Dialog take a look at set to benchmark efficiency.
The Actual Dialog take a look at set was created with the assistance of trusted testers who recorded themselves talking throughout conversations. The audio was reviewed, any personally identifiable info (PII) was eliminated, after which that knowledge was transcribed by speech-language pathologists. The Actual Dialog take a look at set accommodates over 1,500 utterances from 29 audio system.
Adapting USM to disordered speech
We then tuned USM on the coaching break up of the Euphonia Prompted Speech set to enhance its efficiency on disordered speech. As an alternative of fine-tuning the complete mannequin, our tuning was based mostly on residual adapters, a parameter-efficient tuning method that provides tunable bottleneck layers as residuals between the transformer layers. Solely these layers are tuned, whereas the remainder of the mannequin weights are untouched. We’ve got beforehand proven that this method works very effectively to adapt ASR fashions to disordered speech. Residual adapters have been solely added to the encoder layers, and the bottleneck dimension was set to 64.
Outcomes
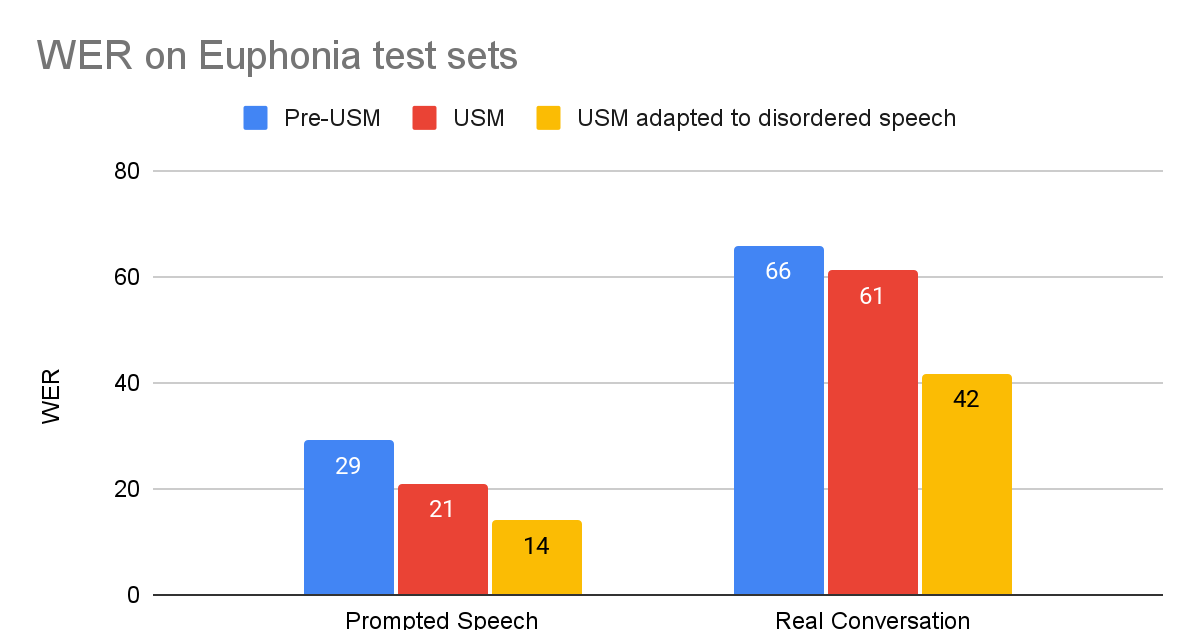
To guage the tailored USM, we in contrast it to older ASR fashions utilizing the 2 take a look at units described above. For every take a look at, we evaluate tailored USM to the pre-USM mannequin finest suited to that activity: (1) For brief prompted speech, we evaluate to Google’s manufacturing ASR mannequin optimized for brief kind ASR; (2) for longer Actual Dialog speech, we evaluate to a mannequin educated for lengthy kind ASR. USM enhancements over pre-USM fashions could be defined by USM’s relative dimension improve, 120M to 2B parameters, and different enhancements mentioned within the USM weblog put up.
 |
| Mannequin phrase error charges (WER) for every take a look at set (decrease is best). |
We see that the USM tailored with disordered speech considerably outperforms the opposite fashions. The tailored USM’s WER on Actual Dialog is 37% higher than the pre-USM mannequin, and on the Prompted Speech take a look at set, the tailored USM performs 53% higher.
These findings recommend that the tailored USM is considerably extra usable for an finish person with disordered speech. We are able to exhibit this enchancment by transcripts of Actual Dialog take a look at set recordings from a trusted tester of Euphonia and Undertaking Relate (see under).
| Audio1 | ||||||
| Floor Fact | Pre-USM ASR | Tailored USM | ||||
| I now have an Xbox adaptive controller on my lap. | i now have so much and that guide on my mouth | i now had an xbox adapter controller on my lamp. | ||||
| I have been speaking for fairly some time now. Let’s examine. | fairly some time now | i have been speaking for fairly some time now. | ||||
| Instance audio and transcriptions of a trusted tester’s speech from the Actual Dialog take a look at set. |
A comparability of the Pre-USM and tailored USM transcripts revealed some key benefits:
- The primary instance reveals that Tailored USM is best at recognizing disordered speech patterns. The baseline misses key phrases like “XBox” and “controller” which might be necessary for a listener to know what they’re attempting to say.
- The second instance is an effective instance of how deletions are a major difficulty with ASR fashions that aren’t educated with disordered speech. Although the baseline mannequin did transcribe a portion accurately, a big a part of the utterance was not transcribed, dropping the speaker’s meant message.
Conclusion
We imagine that this work is a crucial step in direction of making speech recognition extra accessible to individuals with disordered speech. We’re persevering with to work on enhancing the efficiency of our fashions. With the speedy developments in ASR, we intention to make sure individuals with disordered speech profit as effectively.
Acknowledgements
Key contributors to this mission embody Fadi Biadsy, Michael Brenner, Julie Cattiau, Richard Cave, Amy Chung-Yu Chou, Dotan Emanuel, Jordan Inexperienced, Rus Heywood, Pan-Pan Jiang, Anton Kast, Marilyn Ladewig, Bob MacDonald, Philip Nelson, Katie Seaver, Joel Shor, Jimmy Tobin, Katrin Tomanek, and Subhashini Venugopalan. We gratefully acknowledge the help Undertaking Euphonia obtained from members of the USM analysis crew together with Yu Zhang, Wei Han, Nanxin Chen, and plenty of others. Most significantly, we needed to say an enormous thanks to the two,200+ contributors who recorded speech samples and the various advocacy teams who helped us join with these contributors.
1Audio quantity has been adjusted for ease of listening, however the unique information can be extra according to these utilized in coaching and would have pauses, silences, variable quantity, and so on. 

{kind=link}