
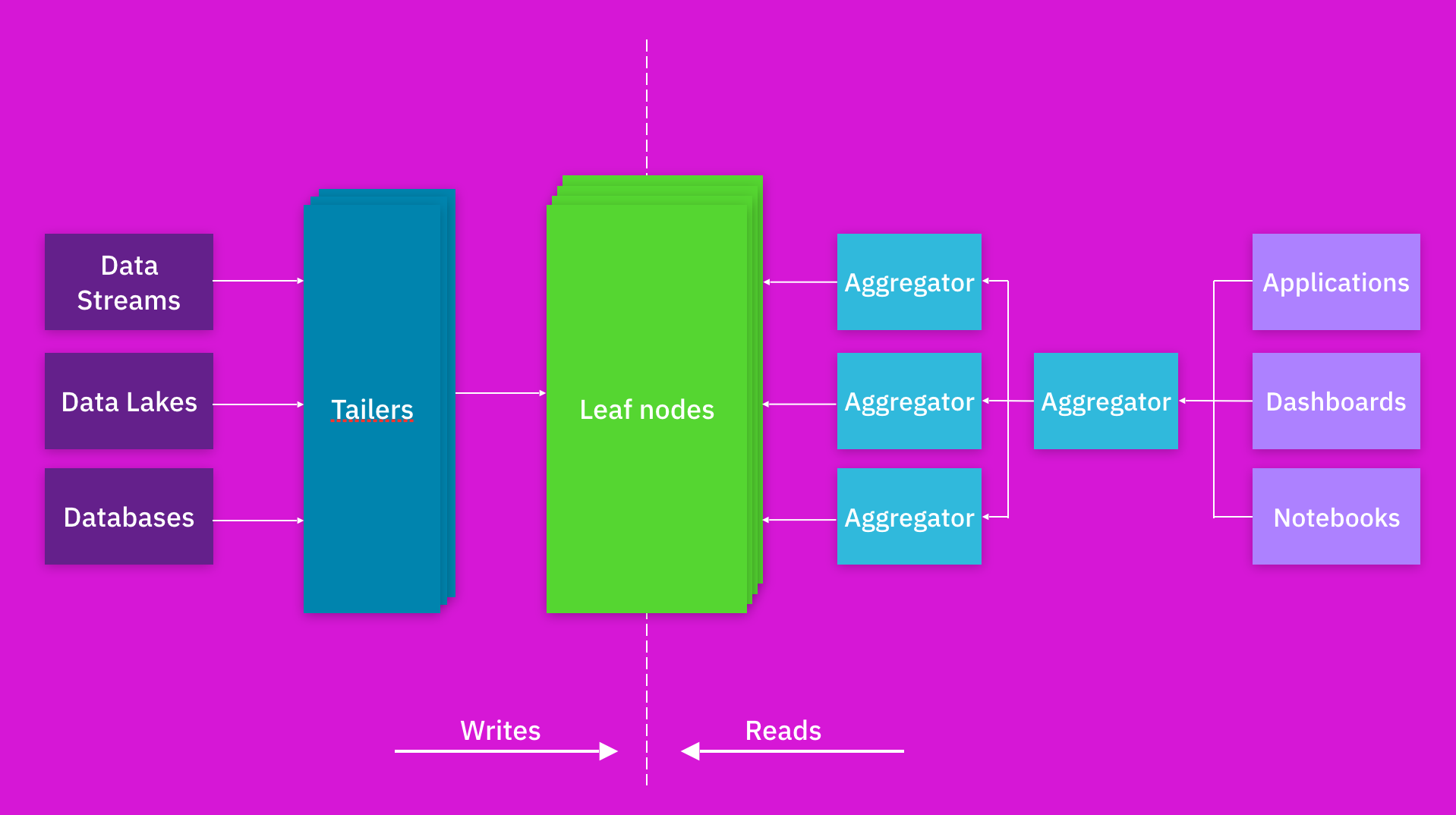
Aggregator Leaf Tailer (ALT) is the info structure favored by web-scale firms, like Fb, LinkedIn, and Google, for its effectivity and scalability. On this weblog put up, I’ll describe the Aggregator Leaf Tailer structure and its benefits for low-latency knowledge processing and analytics.
Once we began Rockset, we got down to implement a real-time analytics engine that made the developer’s job so simple as attainable. That meant a system that was sufficiently nimble and highly effective to execute quick SQL queries on uncooked knowledge, basically performing any wanted transformations as a part of the question step, and never as a part of a fancy knowledge pipeline. That additionally meant a system that took full benefit of cloud efficiencies–responsive useful resource scheduling and disaggregation of compute and storage–whereas abstracting away all infrastructure-related particulars from customers. We selected ALT for Rockset.
Conventional Knowledge Processing: Batch and Streaming
MapReduce, mostly related to Apache Hadoop, is a pure batch system that usually introduces important time lag in massaging new knowledge into processed outcomes. To mitigate the delays inherent in MapReduce, the Lambda structure was conceived to complement batch outcomes from a MapReduce system with a real-time stream of updates. A serving layer unifies the outputs of the batch and streaming layers, and responds to queries.
The true-time stream is usually a set of pipelines that course of new knowledge as and when it’s deposited into the system. These pipelines implement windowing queries on new knowledge after which replace the serving layer. This structure has grow to be widespread within the final decade as a result of it addresses the stale-output drawback of MapReduce programs.
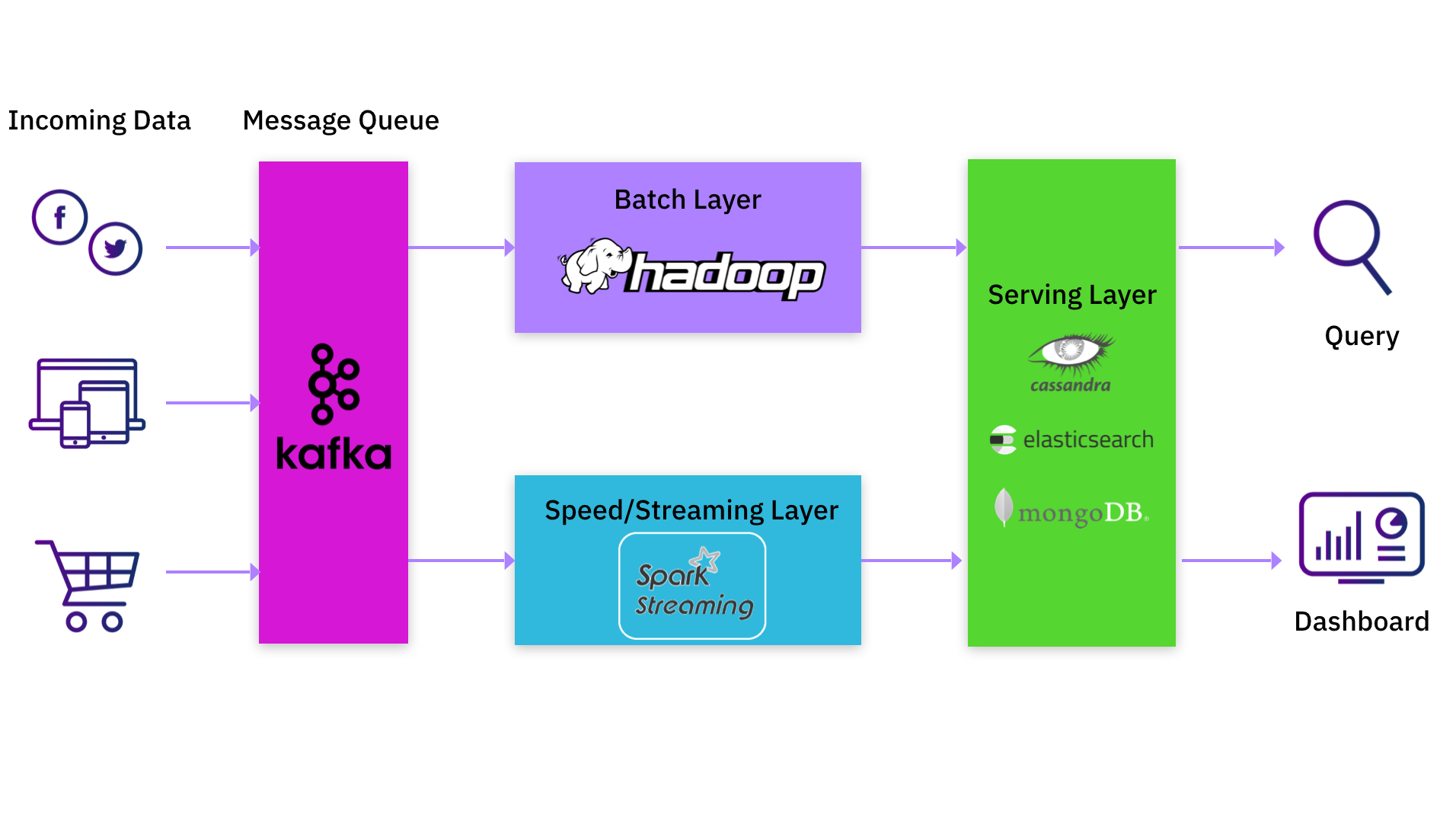
Frequent Lambda Architectures: Kafka, Spark, and MongoDB/Elasticsearch
In case you are an information practitioner, you’d in all probability have both applied or used an information processing platform that comes with the Lambda structure. A standard implementation would have giant batch jobs in Hadoop complemented by an replace stream saved in Apache Kafka. Apache Spark is commonly used to learn this knowledge stream from Kafka, carry out transformations, after which write the end result to a different Kafka log. Usually, this may not be a single Spark job however a pipeline of Spark jobs. Every Spark job within the pipeline would learn knowledge produced by the earlier job, do its personal transformations, and feed it to the subsequent job within the pipeline. The ultimate output could be written to a serving system like Apache Cassandra, Elasticsearch or MongoDB.
Shortcomings of Lambda Architectures
Being an information practitioner myself, I acknowledge the worth the Lambda structure affords by permitting knowledge processing in actual time. But it surely is not a super structure, from my perspective, as a consequence of a number of shortcomings:
- Sustaining two totally different processing paths, one through the batch system and one other through the real-time streaming system, is inherently tough. When you ship new code performance to the streaming software program however fail to make the required equal change to the batch software program, you would get inaccurate outcomes.
- In case you are an software developer or knowledge scientist who desires to make modifications to your streaming or batch pipeline, you must both learn to function and modify the pipeline, or you must watch for another person to make the modifications in your behalf. The previous possibility requires you to choose up knowledge engineering duties and detracts out of your main position, whereas the latter forces you right into a holding sample ready on the pipeline workforce for decision.
- Many of the knowledge transformation occurs as new knowledge enters the system at write time, whereas the serving layer is a less complicated key-value lookup that doesn’t deal with complicated transformations. This complicates the job of the appliance developer as a result of she/he can not simply apply new transformations retroactively on pre-existing knowledge.
The most important benefit of the Lambda structure is that knowledge processing happens when new knowledge arrives within the system, however paradoxically that is its largest weak spot as effectively. Most processing within the Lambda structure occurs within the pipeline and never at question time. As a lot of the complicated enterprise logic is tied to the pipeline software program, the appliance developer is unable to make fast modifications to the appliance and has restricted flexibility within the methods she or he can use the info. Having to keep up a pipeline simply slows you down.
ALT: Actual-Time Analytics With out Pipelines
The ALT structure addresses these shortcomings of Lambda architectures. The important thing part of ALT is a high-performance serving layer that serves complicated queries, and never simply key-value lookups. The existence of this serving layer obviates the necessity for complicated knowledge pipelines.
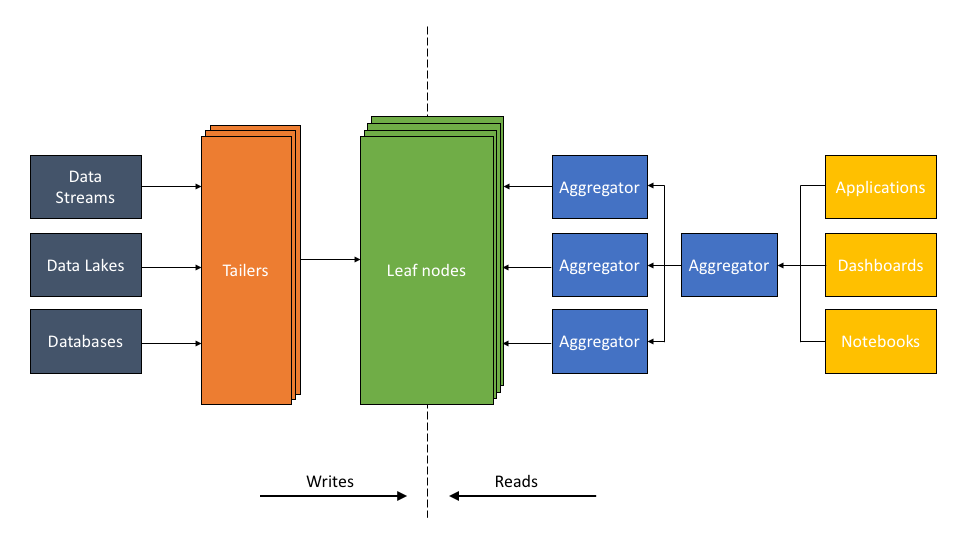
The ALT structure described:
- The Tailer pulls new incoming knowledge from a static or streaming supply into an indexing engine. Its job is to fetch from all knowledge sources, be it an information lake, like S3, or a dynamic supply, like Kafka or Kinesis.
- The Leaf is a robust indexing engine. It indexes all knowledge as and when it arrives through the Tailer. The indexing part builds a number of forms of indexes—inverted, columnar, doc, geo, and lots of others—on the fields of an information set. The aim of indexing is to make any question on any knowledge area quick.
- The scalable Aggregator tier is designed to ship low-latency aggregations, be it columnar aggregations, joins, relevance sorting, or grouping. The Aggregators leverage indexing so effectively that complicated logic sometimes executed by pipeline software program in different architectures might be executed on the fly as a part of the question.
Benefits of ALT
The ALT structure allows the app developer or knowledge scientist to run low-latency queries on uncooked knowledge units with none prior transformation. A big portion of the info transformation course of can happen as a part of the question itself. How is that this attainable within the ALT structure?
- Indexing is crucial to creating queries quick. The Leaves preserve a wide range of indexes concurrently, in order that knowledge might be shortly accessed no matter the kind of question—aggregation, key-value, time collection, or search. Each doc and area is listed, together with each worth and kind of every area, leading to quick question efficiency that permits considerably extra complicated knowledge processing to be inserted into queries.
- Queries are distributed throughout a scalable Aggregator tier. The power to scale the variety of Aggregators, which give compute and reminiscence sources, permits compute energy to be targeting any complicated processing executed on the fly.
- The Tailer, Leaf, and Aggregator run as discrete microservices in disaggregated trend. Every Tailer, Leaf, or Aggregator tier might be independently scaled up and down as wanted. The system scales Tailers when there’s extra knowledge to ingest, scales Leaves when knowledge dimension grows, and scales Aggregators when the quantity or complexity of queries will increase. This unbiased scalability permits the system to deliver important sources to bear on complicated queries when wanted, whereas making it cost-effective to take action.
Essentially the most important distinction is that the Lambda structure performs knowledge transformations up entrance in order that outcomes are pre-materialized, whereas the ALT structure permits for question on demand with on-the-fly transformations.
Why ALT Makes Sense As we speak
Whereas not as extensively often called the Lambda structure, the ALT structure has been in existence for nearly a decade, employed totally on high-volume programs.
- Fb’s Multifeed structure has been utilizing the ALT methodology since 2010, backed by the open-source RocksDB engine, which permits giant knowledge units to be listed effectively.
- LinkedIn’s FollowFeed was redesigned in 2016 to make use of the ALT structure. Their earlier structure, just like the Lambda structure mentioned above, used a pre-materialization method, additionally referred to as fan-out-on-write, the place outcomes have been precomputed and made accessible for easy lookup queries. LinkedIn’s new ALT structure makes use of a question on demand or fan-out-on-read mannequin utilizing RocksDB indexing as an alternative of Lucene indexing. A lot of the computation is completed on the fly, permitting higher velocity and suppleness for builders on this method.
- Rockset makes use of RocksDB as a foundational knowledge retailer and implements the ALT structure (see white paper) in a cloud service.
The ALT structure clearly has the efficiency, scale, and effectivity to deal with real-time use instances at a number of the largest on-line firms. Why has it not been used as extensively until lately? The quick reply is that “indexing” software program is historically expensive, and never commercially viable, when knowledge dimension is giant. That dominated out many smaller organizations from pursuing an ALT, query-on-demand method up to now. However the present state of know-how—the mixture of highly effective indexing software program constructed on open-source RocksDB and favorable cloud economics—has made ALT not solely commercially possible at present, however a sublime structure for real-time knowledge processing and analytics.
Be taught extra about Rockset’s structure on this 30 minute whiteboard video session by Rockset CTO and Co-founder Dhruba Borthakur.
Embedded content material: https://youtu.be/msW8nh5TTwQ
Rockset is the main real-time analytics platform constructed for the cloud, delivering quick analytics on real-time knowledge with stunning effectivity. Be taught extra at rockset.com.

{kind=link}