

Apache Flink is a framework and distributed processing engine for stateful computations over knowledge streams. Amazon Kinesis Information Analytics for Apache Flink is a completely managed service that lets you use an Apache Flink software to course of streaming knowledge. The Deep Java Library (DJL) is an open-source, high-level, engine-agnostic Java framework for deep studying.
On this weblog submit, we show how you should use DJL inside Kinesis Information Analytics for Apache Flink for real-time machine studying inference. Actual-time inference could be worthwhile in a wide range of functions and industries the place it’s important to make predictions or take actions based mostly on new knowledge as rapidly as doable with low latencies. We present easy methods to load a pre-trained deep studying mannequin from the DJL mannequin zoo right into a Flink job and apply the mannequin to categorise knowledge objects in a steady knowledge stream. The DJL mannequin zoo contains all kinds of pre-trained fashions for picture classification, semantic segmentation, speech recognition, textual content embedding technology, query answering, and extra. It helps HuggingFace, Pytorch, MXNet, and TensorFlow mannequin frameworks and likewise helps builders create and publish their very own fashions. We are going to deal with picture classification and use a well-liked classifier referred to as ResNet-18 to provide predictions in actual time. The mannequin has been pre-trained on ImageNet with 1.2 million pictures belonging to 1,000 class labels.
We offer pattern code, structure diagrams, and an AWS CloudFormation template so you’ll be able to comply with alongside and make use of ResNet-18 as your classifier to make real-time predictions. The answer we offer here’s a highly effective design sample for constantly producing ML-based predictions on streaming knowledge inside Kinesis Information Analytics for Apache Flink. You possibly can adapt the offered resolution on your use case and select another mannequin from the mannequin zoo and even present your individual mannequin.
Picture classification is a traditional drawback that takes a picture and selects the best-fitting class, akin to whether or not the picture from an autonomous driving system is that of a bicycle or a pedestrian. Widespread use circumstances for real-time inference on streams of pictures embrace classifying pictures from automobile cameras and license plate recognition techniques, and classifying pictures uploaded to social media and ecommerce web sites. The use circumstances usually want low latency whereas dealing with excessive throughput and probably bursty streams. For instance, in ecommerce web sites, real-time classification of uploaded pictures may also help in marking photos of banned items or hazardous supplies which were provided by sellers. Speedy dedication by way of streaming inference is required to set off alerts and follow-up actions to forestall these pictures from being a part of the catalog. This permits quicker decision-making in comparison with batch jobs that run on a periodic foundation. The info stream pipeline can contain a number of fashions for various functions, akin to classifying uploaded pictures into ecommerce classes of electronics, toys, style, and so forth.
Answer overview
The next diagram illustrates the workflow of our resolution.

The appliance performs the next steps:
- Learn in pictures from Amazon Easy Storage Service (Amazon S3) utilizing the Apache Flink Filesystem File Supply connector.
- Window the photographs into a group of data.
- Classify the batches of pictures utilizing the DJL picture classification class.
- Write inference outcomes to Amazon S3 on the path specified.
Pictures are advisable to be of cheap measurement in order that they might match right into a Kinesis Processing Unit. Pictures bigger than 50MB in measurement could lead to latency in processing and classification.
The principle class for this Apache Flink job is positioned at src/most important/java/com.amazon.embeddedmodelinference/EMI.java. Right here you will discover the most important() methodology and entry level to our Flink job.
Conditions
To get began, configure the next conditions in your native machine:
As soon as that is arrange, you’ll be able to clone the code base to entry the supply code for this resolution. The Java software code for this instance is obtainable on GitHub. To obtain the appliance code, clone the distant repository utilizing the next command:
Discover and navigate to the folder of the picture classification instance, referred to as image-classification.
An instance set of pictures to stream and check the code is obtainable within the imagenet-sample-images folder.
Let’s stroll by way of the code step-by-step.
Check in your native machine
If you want to check this software regionally in your machine, guarantee you’ve AWS credentials arrange regionally in your machine. Moreover, obtain the Flink S3 Filesystem Hadoop JAR to make use of along with your Apache Flink set up and place it in a folder named plugins/s3 within the root of your venture. Then configure the next surroundings variables both in your IDE or in your machine’s native variable scope:
Substitute these values with your individual.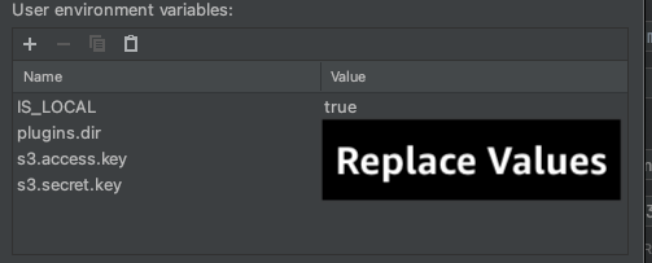
After configuring the surroundings variables and downloading the required plugin JAR, let’s take a look at the code.
Within the most important methodology, after establishing our StreamExecutionEnvironment, we outline our FileSource to learn information from Amazon S3. By default, this supply operator reads from a pattern bucket. You possibly can exchange this bucket identify with your individual by altering the variable referred to as bucket, or setting the appliance property on Kinesis Information Analytics for Apache Flink as soon as deployed.
The FileSource is configured to learn in information within the ImageReaderFormat, and can verify Amazon S3 for brand spanking new pictures each 10 seconds. This may be configured as effectively.
After we’ve learn in our pictures, we convert our FileSource right into a stream that may be processed:
Subsequent, we create a tumbling window of a variable time window period, specified within the configuration, defaulting to 60 seconds. Each window shut creates a batch (record) of pictures to be categorised utilizing a ProcessWindowFunction.
This ProcessWindowFunction calls the classifier predict operate on the record of pictures and returns the perfect likelihood of classification from every picture. This result’s then despatched again to the Flink operator, the place it’s promptly written out to the S3 bucket path of your configuration.
In Classifier.java, we learn the picture and apply crop, transpose, reshape, and at last convert to an N-dimensional array that may be processed by the deep studying mannequin. Then we feed the array to the mannequin and apply a ahead move. Throughout the ahead move, the mannequin computes the neural community layer by layer. Ultimately, the output object incorporates the chances for every picture object that the mannequin is being skilled on. We map the chances with the article identify and return to the map operate.
Deploy the answer with AWS CloudFormation
To run this code base on Kinesis Information Analytics for Apache Flink, we’ve a useful CloudFormation template that may spin up the required sources. Merely open AWS CloudShell or your native machine’s terminal and enter the next instructions. Full the next steps to deploy the answer:
- For those who don’t have the AWS Cloud Improvement Package (AWS CDK) bootstrapped in your account, run the next command, offering your account quantity and present Area:
The script will clone a GitHub repo of pictures to categorise and add them to your supply S3 bucket. Then it is going to launch the CloudFormation stack given your enter parameters. 
- Enter the next code and exchange the BUCKET variables with your individual supply bucket and sink bucket, which is able to comprise the supply pictures and the classifications, respectively:
This CloudFormation stack creates the next sources:
-
- A Kinesis Information Analytics software with 1 Kinesis Processing Unit (KPU) preconfigured with some software properties
-
- An S3 bucket on your output outcomes
- When the stack is full, navigate to the Kinesis Information Analytics for Apache Flink console.
- Discover the appliance referred to as
blog-DJL-flink-ImageClassification-applicationand select Run. - On the Amazon S3 console, navigate to the bucket you specified within the
outputBucketPathvariable.
When you’ve got readable pictures within the supply bucket listed, it is best to see classifications of these pictures throughout the checkpoint interval of the working software.
Deploy the answer manually
For those who desire to make use of your individual code base, you’ll be able to comply with the guide steps on this part:
- After you clone the appliance regionally, create your software JAR by navigating to the listing that incorporates your
pom.xmland working the next command:
This builds your software JAR within the goal/ listing referred to as embedded-model-inference-1.0-SNAPSHOT.jar.
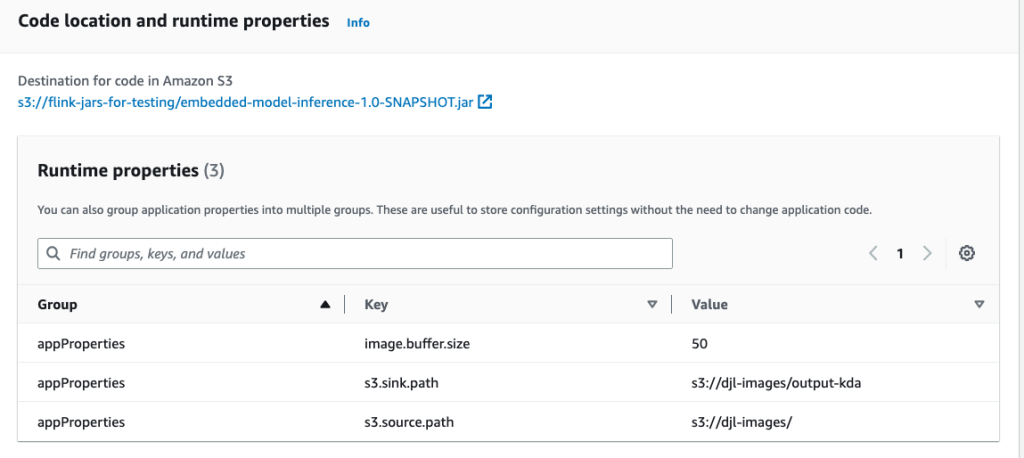
- Add this software JAR to an S3 bucket, both the one created from the CloudFormation template, or one other one to retailer code artifacts.
- You possibly can then configure your Kinesis Information Analytics software to level to this newly uploaded S3 JAR file.
- That is additionally an incredible alternative to configure your runtime properties, as proven within the following screenshot.
- Select Run to start out your software.
You possibly can open the Apache Flink Dashboard to verify for software exceptions or to see knowledge flowing by way of the duties outlined within the code.

Validate the outcomes
To validate our outcomes, let’s verify the ends in Amazon S3 by navigating to the Amazon S3 console and discovering our S3 bucket. We will discover the output in a folder referred to as output-kda.

Once we select one of many data-partitioned folders, we are able to see partition information. Be certain that there isn’t any underscore in entrance of your half file, as a result of this means that the outcomes are nonetheless being finalized in keeping with the rollover interval outlined in Apache Flink’s FileSink connector. After the underscores have disappeared, we are able to use Amazon S3 Choose to view our knowledge.

We now have an answer that constantly performs classification on incoming pictures in actual time utilizing Kinesis Information Analytics for Apache Flink. It extracts a pre-trained classification mannequin (ResNet-18) from the DJL mannequin zoo, applies some preprocessing, hundreds the mannequin right into a Flink operator’s reminiscence, and constantly applies the mannequin for on-line predictions on streaming pictures.
Though we used ResNet-18 on this submit, you’ll be able to select one other mannequin by modifying the classifier. The DJL mannequin zoo gives many different fashions, each for classification and different functions, that can be utilized out of the field. You can too load your customized mannequin by offering an S3 hyperlink or URL to the standards. DJL helps fashions in a lot of engines akin to PyTorch, ONNX, TensorFlow, and MXNet. Utilizing a mannequin within the resolution is comparatively easy. All the preprocessing and postprocessing code is encapsulated within the (built-in) translator, so all we’ve to do is load the mannequin, create a predictor, and name predict(). That is executed throughout the knowledge supply operator, which processes the stream of enter knowledge and sends the hyperlinks to the info to the inference operator the place the mannequin you chose produces the prediction. Then the sink operator writes the outcomes.
The CloudFormation template on this instance targeted on a easy 1 KPU software. You can prolong the answer to additional scale out to giant fashions and high-throughput streams, and assist a number of fashions throughout the pipeline.
Clear up
To wash up the CloudFormation script you launched, full the next steps:
- Empty the supply bucket you specified within the bash script.
- On the AWS CloudFormation console, find the CloudFormation template referred to as
KDAImageClassification. - Delete the stack, which is able to take away all the remaining sources created for this submit.
- It’s possible you’ll optionally delete the bootstrapping CloudFormation template,
CDKToolkit, which you launched earlier as effectively.
Conclusion
On this submit, we offered an answer for real-time classification utilizing the Deep Java Library inside Kinesis Information Analytics for Apache Flink. We shared a working instance and mentioned how one can adapt the answer on your particular ML use case. When you’ve got any suggestions or questions, please go away them within the feedback part.
Concerning the Authors
 Jeremy Ber has been working within the telemetry knowledge area for the previous 9 years as a Software program Engineer, Machine Studying Engineer, and most lately a Information Engineer. At AWS, he’s a Streaming Specialist Options Architect, supporting each Amazon Managed Streaming for Apache Kafka (Amazon MSK) and AWS’s managed providing for Apache Flink.
Jeremy Ber has been working within the telemetry knowledge area for the previous 9 years as a Software program Engineer, Machine Studying Engineer, and most lately a Information Engineer. At AWS, he’s a Streaming Specialist Options Architect, supporting each Amazon Managed Streaming for Apache Kafka (Amazon MSK) and AWS’s managed providing for Apache Flink.
 Deepthi Mohan is a Principal Product Supervisor for Amazon Kinesis Information Analytics, AWS’s managed providing for Apache Flink.
Deepthi Mohan is a Principal Product Supervisor for Amazon Kinesis Information Analytics, AWS’s managed providing for Apache Flink.
 Gaurav Rele is a Information Scientist on the Amazon ML Answer Lab, the place he works with AWS prospects throughout totally different verticals to speed up their use of machine studying and AWS Cloud companies to resolve their enterprise challenges.
Gaurav Rele is a Information Scientist on the Amazon ML Answer Lab, the place he works with AWS prospects throughout totally different verticals to speed up their use of machine studying and AWS Cloud companies to resolve their enterprise challenges.

{kind=link}