
“A quick-moving know-how subject the place new instruments, applied sciences and platforms are launched very ceaselessly and the place it is rather arduous to maintain up with new developments.” I might be describing both the VR house or Knowledge Engineering, however in truth this put up is concerning the intersection of each.
Digital Actuality – The Subsequent Frontier in Media
I work as a Knowledge Engineer at a number one firm within the VR house, with a mission to seize and transmit actuality in excellent constancy. Our content material varies from on-demand experiences to reside occasions like NBA video games, comedy reveals and music live shows. The content material is distributed via each our app, for many of the VR headsets out there, and in addition by way of Oculus Venues.

From a content material streaming perspective, our use case isn’t very completely different from another streaming platform. We ship video content material via the Web; customers can open our app and flick through completely different channels and choose which content material they need to watch. However that’s the place the similarities finish; from the second customers put their headsets on, we get their full consideration. In a conventional streaming utility, the content material could be streaming within the machine however there isn’t a method to know if the person is definitely paying consideration and even wanting on the machine. In VR, we all know precisely when a person is actively consuming content material.
Streams of VR Occasion Knowledge
One integral a part of our immersive expertise providing is reside occasions. The primary distinction with conventional video-on-demand content material is that these experiences are streamed reside solely at some point of the occasion. For instance, we stream reside NBA video games to most VR headsets out there. Dwell occasions convey a unique set of challenges in each the technical elements (cameras, video compression, encoding) and the info they generate from person conduct.

Each person interplay in our app generates a person occasion that’s despatched to our servers: app opening, scrolling via the content material, choosing a selected content material to test the outline and title, opening content material and beginning to watch, stopping content material, fast-forwarding, exiting the app. Even whereas watching content material, the app generates a “beacon” occasion each few seconds. This uncooked information from the gadgets must be enriched with content material metadata and geolocation data earlier than it may be processed and analyzed.
VR is an immersive platform so customers can’t simply look away when a selected piece of content material isn’t attention-grabbing to them; they’ll both maintain watching, swap to completely different content material or—within the worst-case state of affairs—even take away their headsets. Figuring out what content material generates probably the most participating conduct from the customers is vital for content material era and advertising and marketing functions. For instance, when a person enters our utility, we need to know what drives their consideration. Are they concerned with a selected sort of content material, or simply shopping the completely different experiences? As soon as they determine what they need to watch, do they keep within the content material for the whole period or do they simply watch a number of seconds? After watching a selected sort of content material (sports activities or comedy), do they maintain watching the identical form of content material? Are customers from a selected geographic location extra concerned with a selected sort of content material? What concerning the market penetration of the completely different VR platforms?
From an information engineering perspective, this can be a basic state of affairs of clickstream information, with a VR headset as an alternative of a mouse. Massive quantities of information from person conduct are generated from the VR machine, serialized in JSON format and routed to our backend methods the place information is enriched, pre-processed and analyzed in each actual time and batch. We need to know what’s going on in our platform at this very second and we additionally need to know the completely different developments and statistics from this week, final month or the present yr for instance.
The Want for Operational Analytics
The clickstream information state of affairs has some well-defined patterns with confirmed choices for information ingestion: streaming and messaging methods like Kafka and Pulsar, information routing and transformation with Apache NiFi, information processing with Spark, Flink or Kafka Streams. For the info evaluation half, issues are fairly completely different.
There are a number of completely different choices for storing and analyzing information, however our use case has very particular necessities: real-time, low-latency analytics with quick queries on information and not using a fastened schema, utilizing SQL because the question language. Our conventional information warehouse resolution provides us good outcomes for our reporting analytics, however doesn’t scale very nicely for real-time analytics. We have to get data and make choices in actual time: what’s the content material our customers discover extra participating, from what components of the world are they watching, how lengthy do they keep in a selected piece of content material, how do they react to commercials, A/B testing and extra. All this data will help us drive an much more participating platform for VR customers.
A greater clarification of our use case is given by Dhruba Borthakur in his six propositions of Operational Analytics:
- Complicated queries
- Low information latency
- Low question latency
- Excessive question quantity
- Dwell sync with information sources
- Blended sorts
Our queries for reside dashboards and actual time analytics are very advanced, involving joins, subqueries and aggregations. Since we want the knowledge in actual time, low information latency and low question latency are vital. We consult with this as operational analytics, and such a system should help all these necessities.
Design for Human Effectivity
A further problem that most likely most different small firms face is the best way information engineering and information evaluation groups spend their time and sources. There are plenty of superior open-source initiatives within the information administration market – particularly databases and analytics engines – however as information engineers we need to work with information, not spend our time doing DevOps, putting in clusters, organising Zookeeper and monitoring tens of VMs and Kubernetes clusters. The correct stability between in-house growth and managed companies helps firms concentrate on revenue-generating duties as an alternative of sustaining infrastructure.
For small information engineering groups, there are a number of concerns when choosing the proper platform for operational analytics:
- SQL help is a key issue for speedy growth and democratization of the information. We do not have time to spend studying new APIs and constructing instruments to extract information, and by exposing our information via SQL we allow our Knowledge Analysts to construct and run queries on reside information.
- Most analytics engines require the info to be formatted and structured in a particular schema. Our information is unstructured and generally incomplete and messy. Introducing one other layer of information cleaning, structuring and ingestion may also add extra complexity to our pipelines.
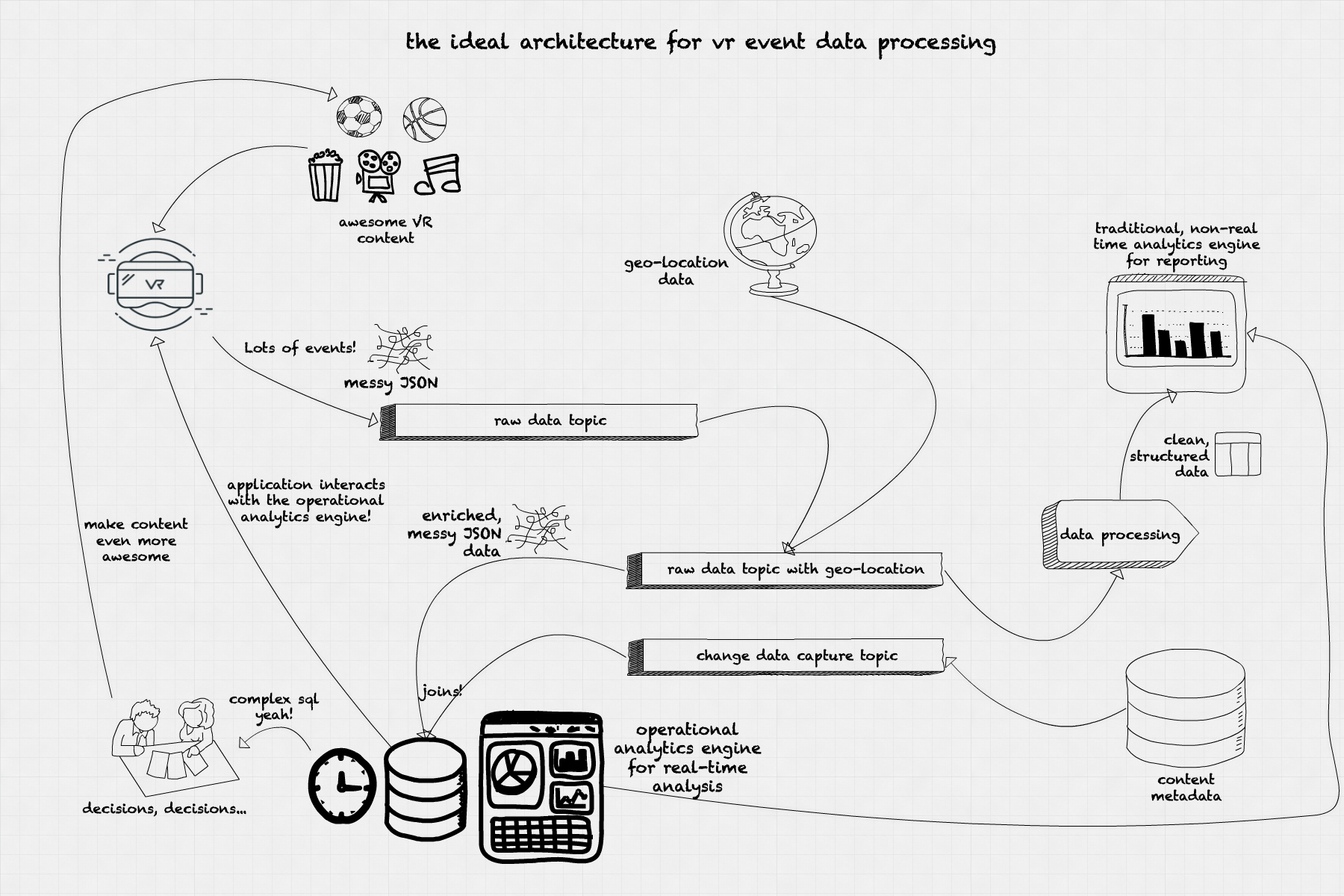
Our Preferrred Structure for Operational Analytics on VR Occasion Knowledge
Knowledge and Question Latency
How are our customers reacting to particular content material? Is that this commercial too invasive that customers cease watching the content material? Are customers from a selected geography consuming extra content material at present? What platforms are main the content material consumption now? All these questions could be answered by operational analytics. Good operational analytics would enable us to research the present developments in our platform and act accordingly, as within the following situations:
Is that this content material getting much less traction in particular geographies? We are able to add a promotional banner on our app focused to that particular geography.
Is that this commercial so invasive that’s inflicting customers to cease watching our content material? We are able to restrict the looks price or change the scale of the commercial on the fly.
Is there a big variety of outdated gadgets accessing our platform for a selected content material? We are able to add content material with decrease definition to present these customers a greater expertise.
These use circumstances have one thing in frequent: the necessity for a low-latency operational analytics engine. All these questions should be answered in a variety from milliseconds to some seconds.
Concurrency
Along with this, our use mannequin requires a number of concurrent queries. Totally different strategic and operational areas want completely different solutions. Advertising and marketing departments can be extra concerned with numbers of customers per platform or area; engineering would need to understand how a selected encoding impacts the video high quality for reside occasions. Executives would need to see what number of customers are in our platform at a selected time limit throughout a reside occasion, and content material companions would have an interest within the share of customers consuming their content material via our platform. All these queries should run concurrently, querying the info in numerous codecs, creating completely different aggregations and supporting a number of completely different real-time dashboards. Every role-based dashboard will current a unique perspective on the identical set of information: operational, strategic, advertising and marketing.
Actual-Time Determination-Making and Dwell Dashboards

As a way to get the info to the operational analytics system rapidly, our perfect structure would spend as little time as potential munging and cleansing information. The information come from the gadgets in JSON format, with a number of IDs figuring out the machine model and mannequin, the content material being watched, the occasion timestamp, the occasion sort (beacon occasion, scroll, clicks, app exit), and the originating IP. All information is nameless and solely identifies gadgets, not the particular person utilizing it. The occasion stream is ingested into our system in a publish/subscribe system (Kafka, Pulsar) in a selected subject for uncooked incoming information. The information comes with an IP handle however with no location information. We run a fast information enrichment course of that attaches geolocation information to our occasion and publishes to a different subject for enriched information. The quick enrichment-only stage doesn’t clear any information since we wish this information to be ingested quick into the operational analytics engine. This enrichment could be carried out utilizing specialised instruments like Apache NiFi and even stream processing frameworks like Spark, Flink or Kafka Streams. On this stage it’s also potential to sessionize the occasion information utilizing windowing with timeouts, establishing whether or not a selected person continues to be within the platform primarily based on the frequency (or absence) of the beacon occasions.
A second ingestion path comes from the content material metadata database. The occasion information should be joined with the content material metadata to transform IDs into significant data: content material sort, title, and period. The choice to hitch the metadata within the operational analytics engine as an alternative of in the course of the information enrichment course of comes from two components: the necessity to course of the occasions as quick as potential, and to dump the metadata database from the fixed level queries wanted for getting the metadata for a selected content material. By utilizing the change information seize from the unique content material metadata database and replicating the info within the operational analytics engine we obtain two targets: preserve a separation between the operational and analytical operations in our system, and in addition use the operational analytics engine as a question endpoint for our APIs.
As soon as the info is loaded within the operational analytics engine, we use visualization instruments like Tableau, Superset or Redash to create interactive, real-time dashboards. These dashboards are up to date by querying the operational analytics engine utilizing SQL and refreshed each few seconds to assist visualize the modifications and developments from our reside occasion stream information.
The insights obtained from the real-time analytics assist make choices on the way to make the viewing expertise higher for our customers. We are able to determine what content material to advertise at a selected time limit, directed to particular customers in particular areas utilizing a selected headset mannequin. We are able to decide what content material is extra participating by inspecting the common session time for that content material. We are able to embrace completely different visualizations in our app, carry out A/B testing and get ends in actual time.
Conclusion
Operational analytics permits enterprise to make choices in actual time, primarily based on a present stream of occasions. This type of steady analytics is essential to understanding person conduct in platforms like VR content material streaming at a worldwide scale, the place choices could be made in actual time on data like person geolocation, headset maker and mannequin, connection pace, and content material engagement. An operational analytics engine providing low-latency writes and queries on uncooked JSON information, with a SQL interface and the flexibility to work together with our end-user API, presents an infinite variety of prospects for serving to make our VR content material much more superior!

{kind=link}