
DevSecOps practices, together with continuous-integration/continuous-delivery (CI/CD) pipelines, allow organizations to answer safety and reliability occasions shortly and effectively and to supply resilient and safe software program on a predictable schedule and price range. Regardless of rising proof and recognition of the efficacy and worth of those practices, the preliminary implementation and ongoing enchancment of the methodology could be difficult. This weblog put up describes our new DevSecOps adoption framework that guides you and your group within the planning and implementation of a roadmap to purposeful CI/CD pipeline capabilities. We additionally present perception into the nuanced variations between an infrastructure group centered on implementing a DevSecOps paradigm and a software-development group.
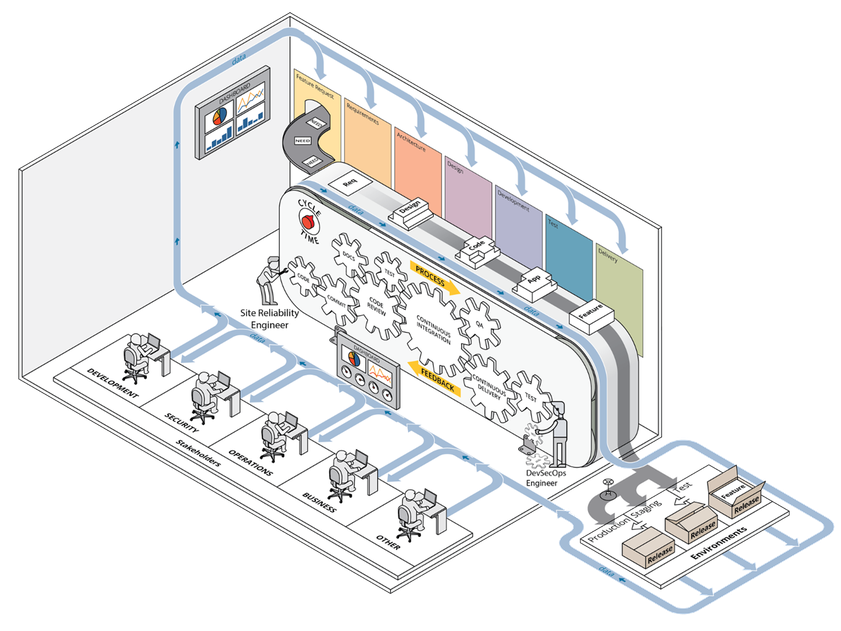
A earlier put up introduced our case for the worth of CI/CD pipeline capabilities and we launched our framework at a excessive stage, outlining the way it helps set priorities throughout preliminary deployment of a improvement atmosphere able to executing CI/CD pipelines and leveraging DevSecOps practices. Determine 1 under depicts the DevSecOps ecosystem, with the complete integration of all parts of a CI/CD pipeline involving stakeholders from a number of departments or teams.
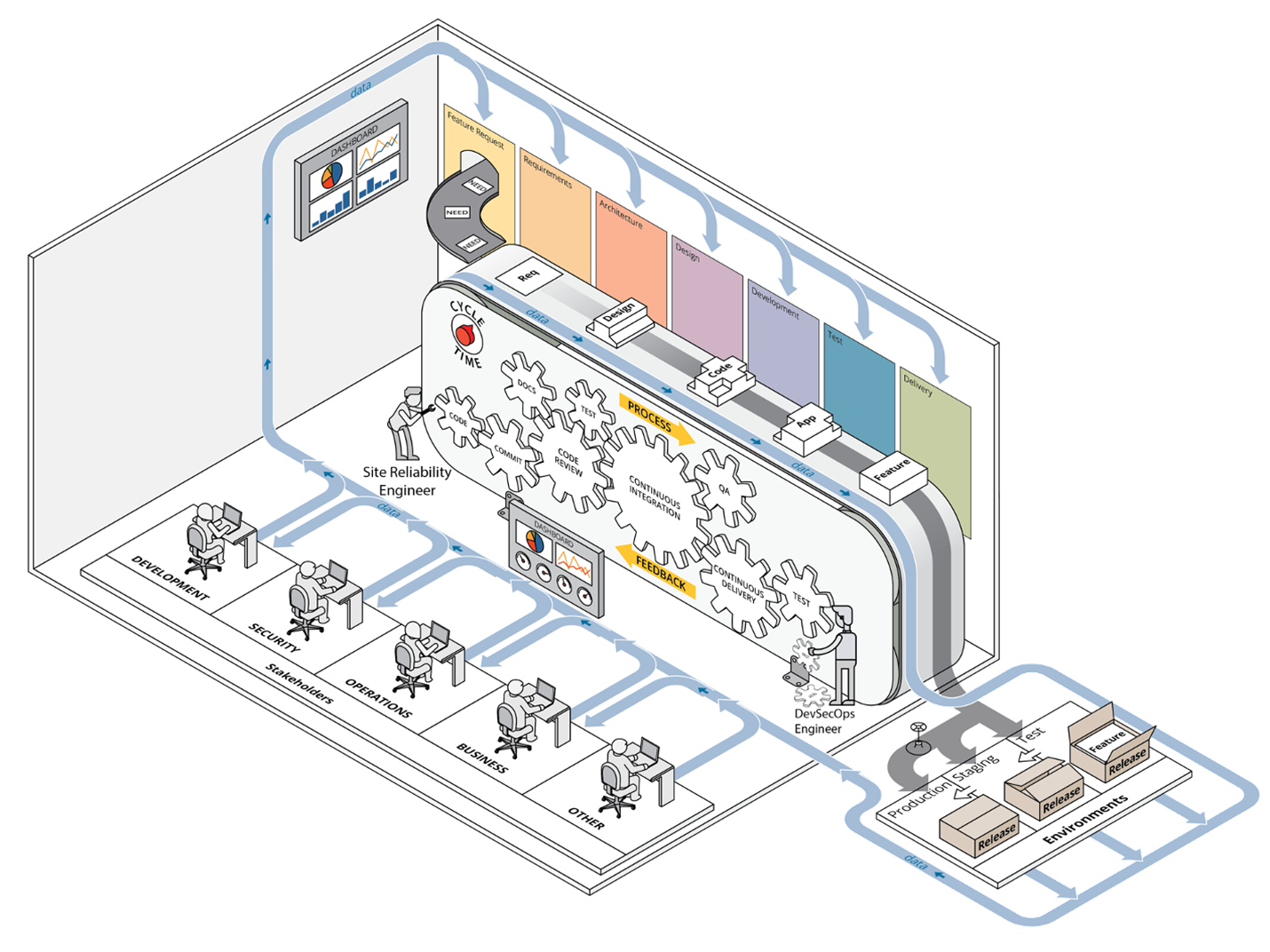
Determine 1: DevSecOps Ecosystem
Our framework builds on derived ideas of DevSecOps, akin to automation by the inclusion of configuration administration and infrastructure as code, collaboration, and monitoring. It offers steering for making use of these DevSecOps ideas to infrastructure operations in a computing atmosphere by offering an ordered method towards implementing essential practices within the levels of adoption, implementation, enchancment, and upkeep of that atmosphere. Our framework additionally leverages automation all through the method and is particularly focused on the improvement and operations groups, generally known as site-reliability engineers, who’re charged with managing the computing atmosphere in use by software-development groups.
The practices we define are primarily based on the precise experiences of SEI employees members supporting on-premises improvement environments tailor-made to the missions of the sponsoring organizations. Our framework applies whether or not your infrastructure is working on-premises in a bodily or digital atmosphere or leveraging commercially out there cloud companies.
The Framework in Element
The levels of our framework, proven in Determine 2, are
0. constructing the muse
1. normalization
2. standardization
3. steady integration and steady testing
4. infrastructure as code (IaC) and steady supply
5. automated safety and compliance as code
6. automated compliance reporting and vulnerability remediation
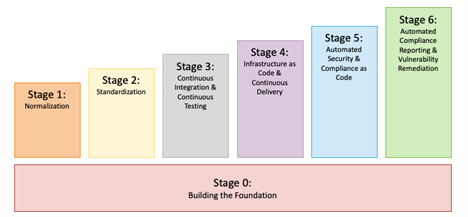
Determine 2: Our DevSecOps Adoption Framework
Breaking the work down on this manner ensures that effort is spent implementing primary DevSecOps practices first, adopted by extra superior processes later. This method is in keeping with the Agile follow of manufacturing small, frequent releases in assist of finish customers, which on this case are software-development groups. Not solely are there dependencies within the early levels, but in addition a particular development within the complexity and issue of the practices in every stage. As well as, our framework allows adaptation to altering necessities and offers ample alternatives for downside fixing as a result of many items of {hardware} and software program should be built-in collectively to attain the purpose of implementing a totally automated CI/CD pipeline.
Our framework addresses technical actions that can most certainly be carried out by technical employees. It doesn’t particularly deal with the group’s cultural adjustments that will even be required to efficiently transition to DevSecOps. Such cultural shifts inside organizations are difficult to implement and require a unique set of expertise and organizational mettle to implement than the practices in our technical framework. When you might observe some overlap within the technical and cultural practices—as a result of it’s exhausting to separate the 2 totally—our framework focuses on the technical practices that allow your DevSecOps ecosystem to evolve and mature. To learn extra about spearheading a profitable cultural shift, learn this weblog put up.
The next sections describe practices we think about as key to every stage, primarily based on our experiences deploying, working, and sustaining computing infrastructure in assist of improvement groups. A typical theme throughout all of the levels is the significance of monitoring. There are myriad monitoring options, each handbook and computerized. Paying shut consideration to a group’s present state of affairs is invaluable to creating sound selections. Your monitoring methods should due to this fact evolve alongside together with your DevSecOps and CI/CD capabilities at every stage.
Stage 0—Constructing the Basis
We’ve numbered this Stage 0 as a result of it’s a prerequisite for all CI/CD actions, although it doesn’t straight comprise practices particularly associated to CI/CD pipelines.
Earlier than you’ll be able to have any means to construct a pipeline, you have to have collaboration instruments in place, together with a wiki, an issue-tracking system, and a version-control system. You could have your identity-management system carried out accurately and be able to amassing logs of system and utility occasions and observing the well being of your collaboration instruments. These are the primary steps to enabling stable monitoring capabilities in later levels. For extra details about the method of deploying a computing atmosphere from scratch in an on-premises or co-located information middle, learn our technical observe.
Stage 1—Normalization
This stage focuses on getting organized by way of the adoption of DevSecOps practices and the minimization of redundancy (akin to when performing database normalization). Encourage (or require) groups liable for the deployment and operation of your computing atmosphere to make use of the collaboration instruments you arrange in stage 0. The normalization stage is the place builders begin monitoring code adjustments in a version-control system. Likewise, operations groups retailer all scripts in a version-control system.
Furthermore, everybody—the groups managing the infrastructure and the event groups they assist—begins monitoring system points, bugs, and consumer tales in an issue-tracking system. Any deployments or software program installations that aren’t scripted and saved in model management must be documented in a wiki or different collaborative documentation system. The infrastructure group also needs to doc repeatable processes within the wiki that can not be automated.
On this stage, you ought to be cognizant of the variables inside your atmosphere that might be redundant. For instance, you need to start to restrict assist of various working system (OS) platforms. Every supported OS provides a major burden in the case of configuration administration and compliance. Builders ought to develop on the identical OS on which they’ll deploy. Likewise, operations groups ought to use an OS that’s appropriate with—and offers good assist for—the programs they’ll be administering. Make sure to observe different cheap alternatives to get rid of overhead.
Stage 2—Standardization
This stage focuses on eradicating pointless variations in your atmosphere. Make sure that your infrastructure and pipeline parts are effectively monitored to take away the massive variable of questioning whether or not your programs are wholesome. Infrastructure monitoring can embrace automated alerts relating to system points (e.g., low disk-space availability) or periodically generated stories that element the general well being of the infrastructure. Outline and doc in your wiki normal working procedures for frequent points to empower everybody on the group to reply when these points come up. Use constant system configurations, ideally managed by a configuration-management system.
For instance, all of your Linux programs would possibly use the identical configuration settings for log assortment, authentication, and monitoring, it doesn’t matter what companies these programs present. Scale back the complexity and overhead of working your computing atmosphere by adopting normal applied sciences throughout groups. Particularly, have all of your improvement groups use a single database product on the again finish of their purposes or the identical visualization instrument for metrics gathering. Lastly, institute units of ordinary standards for the definition of completed to make sure that groups have accomplished all obligatory work to think about their duties absolutely full. Along with monitoring the infrastructure, proceed monitoring remaining alternatives to normalize and standardize instrument utilization throughout groups.
Stage 3—Steady Integration and Steady Testing
This stage focuses on implementing steady integration, which allows the potential of steady testing. Steady integration is a course of that frequently merges a system’s artifacts, together with source-code updates and configuration objects from all stakeholders on a group, right into a shared mainline to construct and take a look at the developed system. This definition can simply be expanded for operations groups to imply frequent updates to configuration-management settings within the version-control system. All stakeholders ought to continuously replace documentation within the groups’ wiki areas and in tickets when applicable, primarily based on the kind of work being documented. This method allows and encourages the codification and reuse of deployment patterns helpful for constructing purposes and companies.
Modifications made to a codebase within the version-control system ought to then set off construct and take a look at procedures. Steady testing is the follow of working builds and checks every time a change is dedicated to a repository and must be a regular follow for software program builders and DevSecOps engineers alike. Testing ought to embody all kinds of adjustments, together with code for software program tasks, shell scripts supporting system operation, or infrastructure as code (IaC) manifests. Steady testing allows you to get frequent suggestions on the standard of the code that’s dedicated.
Unit, purposeful, and integration checks ought to all be triggered when code is dedicated. You need to monitor the outcomes of your automated checks to acquire correct suggestions about whether or not the builds have been profitable. Likewise, these checks improve confidence that code is working accurately earlier than pushing it into manufacturing.
Our expertise exhibits that it’s simple to overlook sure failure modes and go non-functioning code, notably if you’re not diligent about including error checking and testing for frequent failures. In different phrases, your monitoring programs should be mature and strong sufficient to speak when issues are occurring with the adjustments made to infrastructure or code. Furthermore, groups’ definition-of-done standards ought to evolve to make sure that normal practices additionally evolve primarily based on particular person and group experiences to keep away from frequent failure modes from occurring continuously.
Stage 4—Infrastructure as Code and Steady Supply
This stage accelerates your automated deployment processes by integrating infrastructure as code (IaC) and steady supply. IaC is the potential of capturing infrastructure deployment directions in a textual format. This method allows you to shortly and reliably deploy elements of your atmosphere on both a bare-metal server, a digital machine, or a container platform.
Steady supply is the follow of robotically making use of adjustments (options, configurations, bug fixes, and so on.) into manufacturing. IaC promotes atmosphere parity by eliminating creeping configuration adjustments throughout programs and environments that might produce totally different outcomes. The chief good thing about utilizing IaC and steady supply collectively is reliability. The IaC functionality can improve confidence in your atmosphere deployments. Likewise, the continuous-delivery functionality will increase confidence in your automated change supply to these environments. Launching these two capabilities creates many prospects.
Because you began leveraging automated testing in Stage 3, Stage 4 allows you to implement the requirement that every one checks achieve success earlier than adjustments are deployed into manufacturing. In flip, this allows you to
- leverage these capabilities to handle community units with code in your version-control system
- take a look at newly constructed software program merchandise by deploying them into newly constructed digital environments or present environments
- deploy into manufacturing when these adjustments are confirmed out
- robotically provision hosts to increase your present compute capabilities.
At this level, your infrastructure and the product below improvement turn out to be a tightly built-in system that allows you to absolutely perceive the general state of your system. To repeat a key follow from the earlier stage, all these prospects are enabled by a sturdy monitoring system. Actually, advancing previous this stage into the subsequent stage is nearly not possible with no steady monitoring functionality that shortly and precisely offers details about the state of the system and the system’s parts.
Stage 5—Automated Safety and Compliance as Code
This stage advances your automation capabilities past infrastructure and code deployments by including safety automations and compliance as code. Compliance as code means you’re monitoring your compliance controls in scripts and configuration administration in order that instruments can robotically make sure that your programs are compliant with relevant rules and problem an alert when non-compliance is detected. These efforts mix the work of the safety groups and the DevSecOps groups as a result of your safety groups will seemingly outline necessities for the safety controls, which offers the chance for technical individuals to automate adherence to these controls. There are lots of software program items that come collectively to make this work, so you really want the earlier 4 levels in place earlier than enterprise this effort on this stage.
One instrument that’s important on this stage is a devoted vulnerability-scanning instrument. You’ll additionally need your monitoring system to alert the proper set of individuals when safety points are detected robotically. Different instruments could be leveraged to robotically set up system and utility updates and to robotically detect and take away pointless software program.
Stage 6—Automated Compliance Reporting and Vulnerability Remediation
This closing stage is the final word in supporting DevSecOps ecosystems as a result of now that you simply’ve automated your system configurations, testing, and builds, you’ll be able to give attention to automating safety patches and steady suggestions by way of automated report era or notifications throughout DevSecOps pipelines. Compliance with safety rules typically entails periodic opinions and assessments, and having stories available which have been robotically generated can significantly scale back the trouble required to arrange for an evaluation. Precisely what stories must be generated is determined by your particular atmosphere, however just a few examples of helpful stories embrace
- the output of automated vulnerability scans over time
- logs aggregated out of your identity-management system
- information of patches utilized to system firmware and software program
- a abstract out of your community anomaly-detection system.
Furthermore, new vulnerabilities typically turn out to be identified at random intervals primarily based on vendor releases and analysis bulletins. The power to robotically generate stories about system standing, safety points, and the impression of recent vulnerabilities in your programs and purposes signifies that your group can shortly and effectively prioritize the work that should be completed to make sure that your computing atmosphere is as safe accurately. Furthermore, automating the set up of safety patches to your programs and software program helps to cut back the quantity of handbook effort spent sustaining compliant system and utility configurations and might scale back the variety of findings in your automated vulnerability scans. Likewise, with the ability to robotically monitor the outcomes of all these automated processes ensures that the individuals in your group can step in to restore issues as they come up.
Divergence from Conventional DevSecOps Views
As talked about above, we created our DevSecOps adoption framework particularly to assist groups that deploy and preserve computing environments upon which different groups will design and use CI/CD pipelines. This angle is just like—however finally contrasts with—the standard use of DevSecOps practices. Determine 3 under focuses on the functionality supply department, whereas most builders and DevSecOps practitioners are centered on the merchandise department.
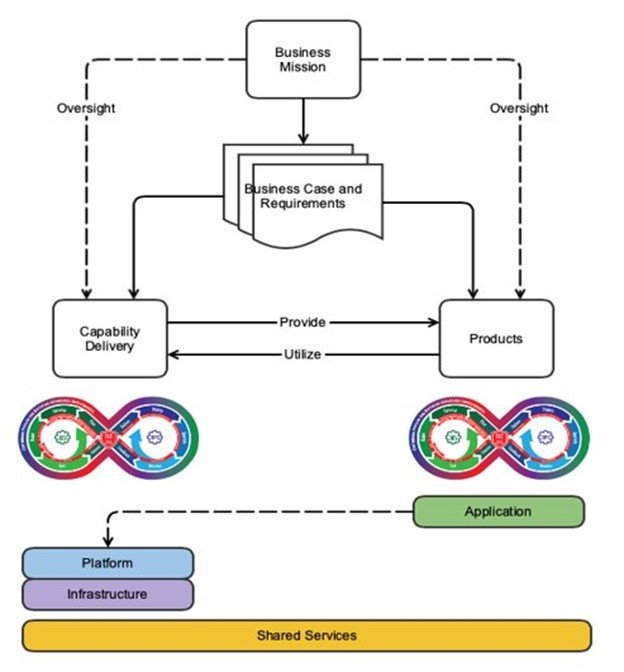
Determine 3: DevSecOps Platform-Impartial Mannequin
The DevSecOps Platform-Impartial Mannequin proven in Determine 3 explores this idea at an summary stage. Each the functionality supply department and the merchandise department are designed to satisfy the mission wants of the enterprise, however their designs produce two totally different plans: a system plan and a product plan. There are two distinct plans as a result of there are two distinct entities at play right here: the pipeline/system and the product that’s being developed. Although they’re associated, they’re distinct. Right here we provide one instance of the excellence between the 2, which is the huge distance between the product operators and the builders of these merchandise.
In an instance of a DevSecOps group centered on the merchandise department, operations personnel work to assist the manufacturing atmosphere on which the software program product is deployed. This expertise permits for fascinating insights, like “Launch X brought about instability at manufacturing scale as a result of it elevated CPU utilization by 50 %.” This perception can then be shortly and effectively fed again to the builders who can work to handle the underlying problem. In different phrases, the operations personnel and the event personnel are linked intently by way of the DevSecOps suggestions loop. Finally, builders, safety personnel, and operational personnel are intently knit by a typical enterprise mission and work towards a typical purpose of offering the absolute best software program product.
Conversely, the DevSecOps groups centered on the functionality supply department are liable for the operation and upkeep of a improvement computing atmosphere, and so they work to offer entry to a major variety of instruments to numerous stakeholders. The event personnel require entry to improvement instruments and software program libraries. The safety personnel require entry to vulnerability-scanning instruments and reporting instruments. The operations personnel themselves require entry to monitoring instruments, visualization instruments, and hardware-management instruments.
Few if any of those instruments are developed in-house—as an alternative they’re both open-source or commercial-off-the-shelf instruments. This dynamic offers an vital separation of the operations group from the product-development group. In distinction to the standard situation described above, when the operations group notices {that a} new launch breaks one thing of their atmosphere, they will enchantment to the builders of the product for a repair that might get carried out if it impacts sufficient prospects. In different phrases, the operations groups don’t collaborate with the event groups below the identical enterprise mission, however as an alternative are merely prospects of the distributors who present the merchandise in use.
What’s extra, when the unpredictability of infrastructure failures and consumer bother tickets are added, they will disrupt the Agile practices of backlog grooming, dash planning, and the metric of velocity. These dynamics are totally different from a pure DevSecOps technique and so they could also be uncomfortable for individuals used to working in a improvement atmosphere, the place all the group is targeted a hundred percent of the time on a single venture. However with just a few variations to that conventional DevSecOps mannequin, this framework could be utilized to offer the advantages of DevSecOps practices in an operationally centered atmosphere.
Realizing the Promise of DevSecOps and CI/CD Pipelines
The purpose of implementing a resilient computing atmosphere that may assist a DevSecOps ecosystem is bold, in the identical manner that “develop working software program” is an bold—but important—purpose. Nevertheless, the advantages of implementing DevSecOps practices—together with CI/CD pipelines—typically outweigh the prices of these difficulties.
Correct planning on the early levels could make the later levels simpler to implement. Our framework due to this fact advocates for breaking the method down into small, manageable duties, and prioritizing repeatability first, automation second. Our framework orders the duties in a logical development in order that the elemental constructing blocks for automation are put in place earlier than the automation itself.
The development by way of the levels shouldn’t be a one-time effort. These practices require ongoing effort to maintain your improvement atmosphere and software program merchandise updated with the newest in technological developments. It’s best to periodically consider your present practices in opposition to the out there information, instruments, and sources, and modify as essential to proceed to assist your group’s mission in the best manner potential.

{kind=link}