
Many languages spoken worldwide cowl quite a few regional varieties (typically known as dialects), reminiscent of Brazilian and European Portuguese or Mainland and Taiwan Mandarin Chinese language. Though such varieties are sometimes mutually intelligible to their audio system, there are nonetheless essential variations. For instance, the Brazilian Portuguese phrase for “bus” is ônibus, whereas the European Portuguese phrase is autocarro. But, as we speak’s machine translation (MT) programs sometimes don’t permit customers to specify which number of a language to translate into. This will result in confusion if the system outputs the “incorrect” selection or mixes varieties in an unnatural manner. Additionally, region-unaware MT programs are inclined to favor whichever selection has extra knowledge obtainable on-line, which disproportionately impacts audio system of under-resourced language varieties.
In “FRMT: A Benchmark for Few-Shot Area-Conscious Machine Translation”, accepted for publication in Transactions of the Affiliation for Computational Linguistics, we current an analysis dataset used to measure MT programs’ capacity to help regional varieties by a case research on Brazilian vs. European Portuguese and Mainland vs. Taiwan Mandarin Chinese language. With the discharge of the FRMT knowledge and accompanying analysis code, we hope to encourage and allow the analysis neighborhood to find new methods of making MT programs which can be relevant to the big variety of regional language varieties spoken worldwide.
Problem: Few-Shot Generalization
Most trendy MT programs are skilled on hundreds of thousands or billions of instance translations, reminiscent of an English enter sentence and its corresponding Portuguese translation. Nonetheless, the overwhelming majority of accessible coaching knowledge doesn’t specify what regional selection the interpretation is in. In gentle of this knowledge shortage, we place FRMT as a benchmark for few-shot translation, measuring an MT mannequin’s capacity to translate into regional varieties when given not more than 100 labeled examples of every language selection. MT fashions want to make use of the linguistic patterns showcased within the small variety of labeled examples (known as “exemplars”) to establish comparable patterns of their unlabeled coaching examples. On this manner, fashions can generalize, producing appropriate translations of phenomena not explicitly proven within the exemplars.
 |
An illustration of a few-shot MT system translating the English sentence, “The bus arrived,” into two regional forms of Portuguese: Brazilian ( ; left) and European ( ; left) and European ( ; proper). ; proper). |
Few-shot approaches to MT are enticing as a result of they make it a lot simpler so as to add help for extra regional varieties to an current system. Whereas our work is particular to regional forms of two languages, we anticipate that strategies that carry out effectively might be readily relevant to different languages and regional varieties. In precept, these strategies also needs to work for different language distinctions, reminiscent of formality and magnificence.
Information Assortment
The FRMT dataset consists of partial English Wikipedia articles, sourced from the Wiki40b dataset, which have been translated by paid, skilled translators into completely different regional forms of Portuguese and Mandarin. So as to spotlight key region-aware translation challenges, we designed the dataset utilizing three content material buckets: (1) Lexical, (2) Entity, and (3) Random.
- The Lexical bucket focuses on regional variations in phrase alternative, such because the “ônibus” vs. “autocarro” distinction when translating a sentence with the phrase “bus” into Brazilian vs. European Portuguese, respectively. We manually collected 20-30 phrases which have regionally distinctive translations in keeping with blogs and academic web sites, and filtered and vetted the translations with suggestions from volunteer native audio system from every area. Given the ensuing checklist of English phrases, we extracted texts of as much as 100 sentences every from the related English Wikipedia articles (e.g., bus). The identical course of was carried out independently for Mandarin.
- The Entity bucket is populated in an analogous manner and issues folks, places or different entities strongly related to one of many two areas in query for a given language. Take into account an illustrative sentence like, “In Lisbon, I typically took the bus.” So as to translate this appropriately into Brazilian Portuguese, a mannequin should overcome two potential pitfalls:
- The sturdy geographical affiliation between Lisbon and Portugal may affect a mannequin to generate a European Portuguese translation as a substitute, e.g., by choosing “autocarro” quite than “ônibus“.
- Changing “Lisbon” with “Brasília” may be a naive manner for a mannequin to localize its output towards Brazilian Portuguese, however can be semantically inaccurate, even in an in any other case fluent translation.
- The Random bucket is used to verify {that a} mannequin appropriately handles different various phenomena, and consists of textual content from 100 randomly sampled articles from Wikipedia’s “featured” and “good” collections.
Analysis Methodology
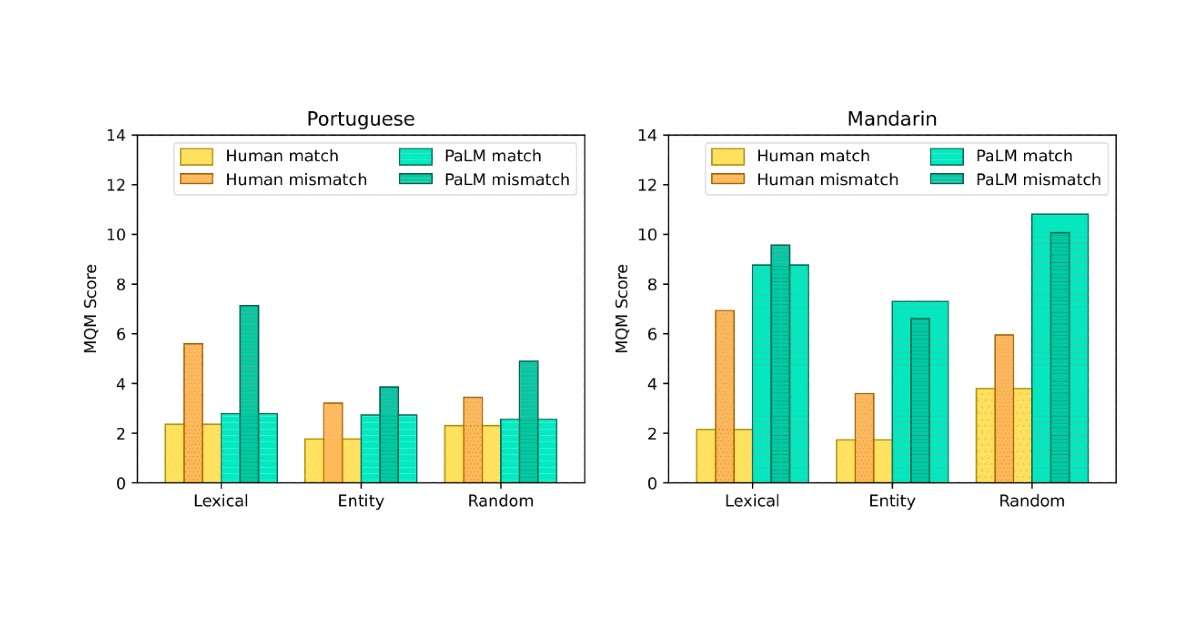
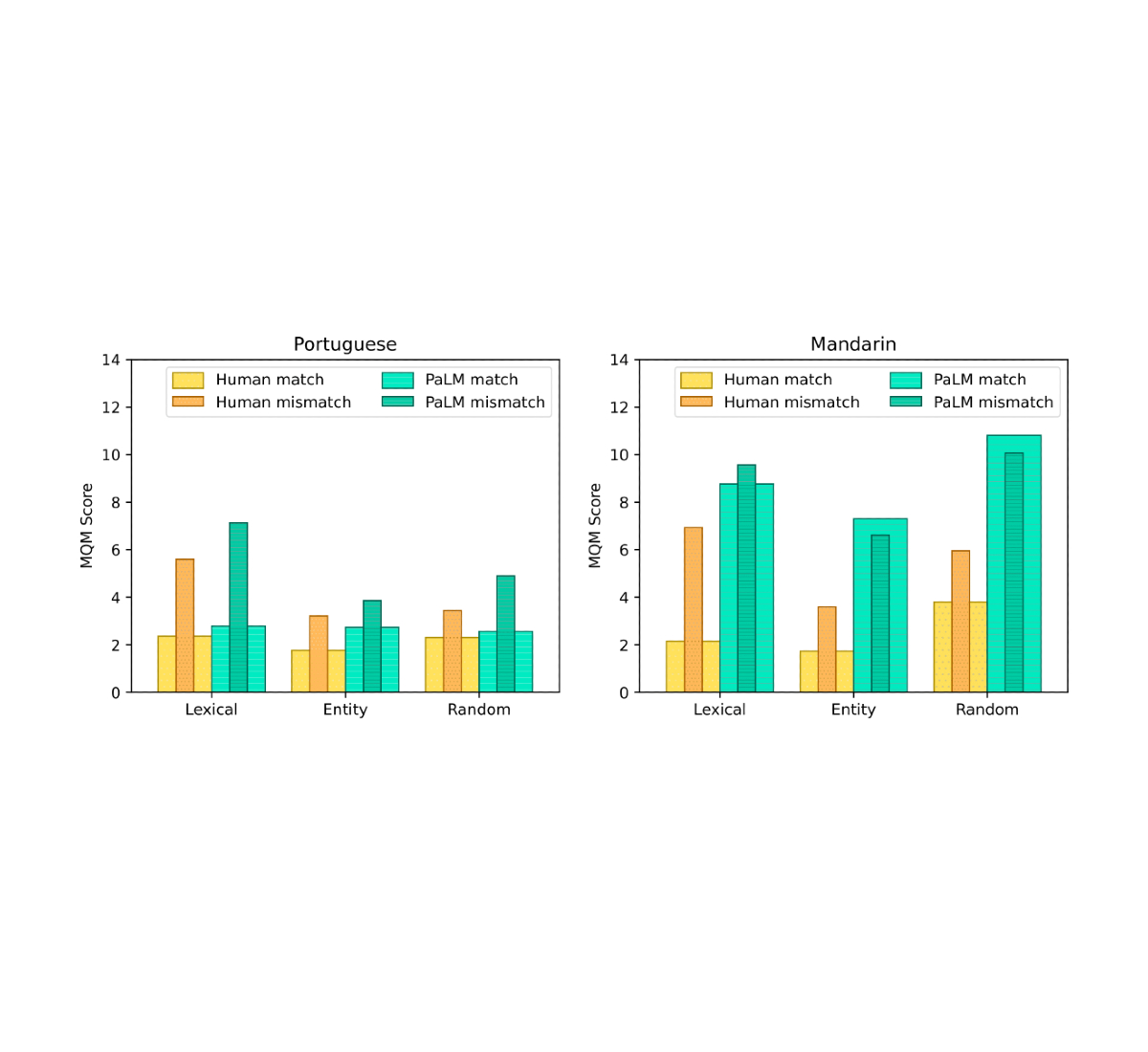
To confirm that the translations collected for the FRMT dataset seize region-specific phenomena, we performed a human analysis of their high quality. Professional annotators from every area used the Multi-dimensional High quality Metrics (MQM) framework to establish and categorize errors within the translations. The framework features a category-wise weighting scheme to transform the recognized errors right into a single rating that roughly represents the variety of main errors per sentence; so a decrease quantity signifies a greater translation. For every area, we requested MQM raters to attain each translations from their area and translations from their language’s different area. For instance, Brazilian Portuguese raters scored each the Brazilian and European Portuguese translations. The distinction between these two scores signifies the prevalence of linguistic phenomena which can be acceptable in a single selection however not the opposite. We discovered that in each Portuguese and Chinese language, raters recognized, on common, roughly two extra main errors per sentence within the mismatched translations than within the matched ones. This means that our dataset actually does seize region-specific phenomena.
Whereas human analysis is the easiest way to make certain of mannequin high quality, it’s typically gradual and costly. We due to this fact wished to search out an current computerized metric that researchers can use to guage their fashions on our benchmark, and regarded chrF, BLEU, and BLEURT. Utilizing the translations from a couple of baseline fashions that have been additionally evaluated by our MQM raters, we found that BLEURT has the perfect correlation with human judgments, and that the power of that correlation (0.65 Pearson correlation coefficient, ρ) is corresponding to the inter-annotator consistency (0.70 intraclass correlation).
| Metric | Pearson’s ρ | ||
| chrF | 0.48 | ||
| BLEU | 0.58 | ||
| BLEURT | 0.65 |
| Correlation between completely different computerized metrics and human judgements of translation high quality on a subset of FRMT. Values are between -1 and 1; greater is best. |
System Efficiency
Our analysis coated a handful of current fashions able to few-shot management. Primarily based on human analysis with MQM, the baseline strategies all confirmed some capacity to localize their output for Portuguese, however for Mandarin, they principally failed to make use of information of the focused area to provide superior Mainland or Taiwan translations.
Google’s current language mannequin, PaLM, was rated greatest general among the many baselines we evaluated. So as to produce region-targeted translations with PaLM, we feed an instructive immediate into the mannequin after which generate textual content from it to fill within the clean (see the instance proven beneath).
Translate the next texts from English to European Portuguese.
English: [English example 1].
European Portuguese: [correct translation 1].
...
English: [input].
European Portuguese: _____"
PaLM obtained sturdy outcomes utilizing a single instance, and had marginal high quality positive aspects on Portuguese when growing to 10 examples. This efficiency is spectacular when considering that PaLM was skilled in an unsupervised manner. Our outcomes additionally recommend language fashions like PaLM could also be significantly adept at memorizing region-specific phrase selections required for fluent translation. Nonetheless, there may be nonetheless a major efficiency hole between PaLM and human efficiency. See our paper for extra particulars.
 |
 |
| MQM efficiency throughout dataset buckets utilizing human and PaLM translations. Thick bars characterize the region-matched case, the place raters from every area consider translations focused at their very own area. Skinny, inset bars characterize the region-mismatched case, the place raters from every area consider translations focused on the different area. Human translations exhibit regional phenomena in all instances. PaLM translations accomplish that for all Portuguese buckets and the Mandarin lexical bucket solely. |
Conclusion
Within the close to future, we hope to see a world the place language era programs, particularly machine translation, can help all speaker communities. We need to meet customers the place they’re, producing language fluent and acceptable for his or her locale or area. To that finish, we have now launched the FRMT dataset and benchmark, enabling researchers to simply examine efficiency for region-aware MT fashions. Validated through our thorough human-evaluation research, the language varieties in FRMT have vital variations that outputs from region-aware MT fashions ought to replicate. We’re excited to see how researchers make the most of this benchmark in growth of recent MT fashions that higher help under-represented language varieties and all speaker communities, resulting in improved equitability in natural-language applied sciences.
Acknowledgements
We gratefully acknowledge our paper co-authors for all their contributions to this undertaking: Timothy Dozat, Xavier Garcia, Dan Garrette, Jason Riesa, Orhan Firat, and Noah Fixed. For useful dialogue and feedback on the paper, we thank Jacob Eisenstein, Noah Fiedel, Macduff Hughes and Mingfei Lau. For important suggestions round particular regional language variations, we thank Andre Araujo, Chung-Ching Chang, Andreia Cunha, Filipe Gonçalves, Nuno Guerreiro, Mandy Guo, Luis Miranda, Vitor Rodrigues and Linting Xue. For logistical help in gathering human translations and rankings, we thank the Google Translate workforce. We thank the skilled translators and MQM raters for his or her position in producing the dataset. We additionally thank Tom Small for offering the animation on this put up.

{kind=link}