

Sustaining Strategic Interoperability and Flexibility
Within the fast-evolving panorama of generative AI, choosing the proper elements in your AI answer is essential. With the big variety of accessible giant language fashions (LLMs), embedding fashions, and vector databases, it’s important to navigate by way of the alternatives properly, as your resolution can have necessary implications downstream.
A selected embedding mannequin may be too sluggish in your particular utility. Your system immediate strategy would possibly generate too many tokens, resulting in increased prices. There are various comparable dangers concerned, however the one that’s typically missed is obsolescence.
As extra capabilities and instruments log on, organizations are required to prioritize interoperability as they appear to leverage the most recent developments within the subject and discontinue outdated instruments. On this surroundings, designing options that permit for seamless integration and analysis of recent elements is important for staying aggressive.
Confidence within the reliability and security of LLMs in manufacturing is one other essential concern. Implementing measures to mitigate dangers resembling toxicity, safety vulnerabilities, and inappropriate responses is important for making certain person belief and compliance with regulatory necessities.
Along with efficiency concerns, components resembling licensing, management, and safety additionally affect one other selection, between open supply and industrial fashions:
- Business fashions supply comfort and ease of use, significantly for fast deployment and integration
- Open supply fashions present better management and customization choices, making them preferable for delicate knowledge and specialised use circumstances
With all this in thoughts, it’s apparent why platforms like HuggingFace are extraordinarily widespread amongst AI builders. They supply entry to state-of-the-art fashions, elements, datasets, and instruments for AI experimentation.
A very good instance is the strong ecosystem of open supply embedding fashions, which have gained recognition for his or her flexibility and efficiency throughout a variety of languages and duties. Leaderboards such because the Large Textual content Embedding Leaderboard supply precious insights into the efficiency of varied embedding fashions, serving to customers establish probably the most appropriate choices for his or her wants.
The identical might be stated concerning the proliferation of various open supply LLMs, like Smaug and DeepSeek, and open supply vector databases, like Weaviate and Qdrant.
With such mind-boggling choice, probably the most efficient approaches to choosing the proper instruments and LLMs in your group is to immerse your self within the dwell surroundings of those fashions, experiencing their capabilities firsthand to find out in the event that they align along with your targets earlier than you decide to deploying them. The mix of DataRobot and the immense library of generative AI elements at HuggingFace permits you to do exactly that.
Let’s dive in and see how one can simply arrange endpoints for fashions, discover and evaluate LLMs, and securely deploy them, all whereas enabling strong mannequin monitoring and upkeep capabilities in manufacturing.
Simplify LLM Experimentation with DataRobot and HuggingFace
Be aware that it is a fast overview of the necessary steps within the course of. You’ll be able to comply with the entire course of step-by-step in this on-demand webinar by DataRobot and HuggingFace.
To begin, we have to create the required mannequin endpoints in HuggingFace and arrange a brand new Use Case within the DataRobot Workbench. Consider Use Instances as an surroundings that incorporates all types of various artifacts associated to that particular challenge. From datasets and vector databases to LLM Playgrounds for mannequin comparability and associated notebooks.
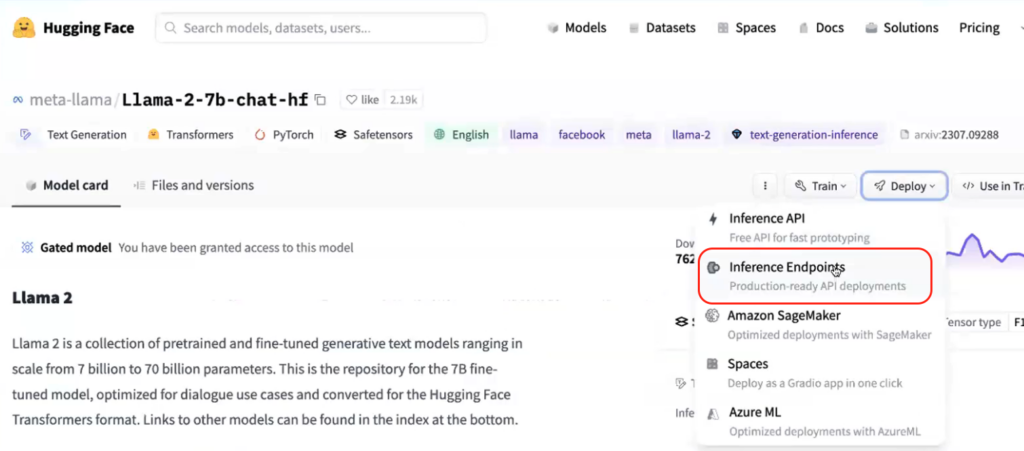
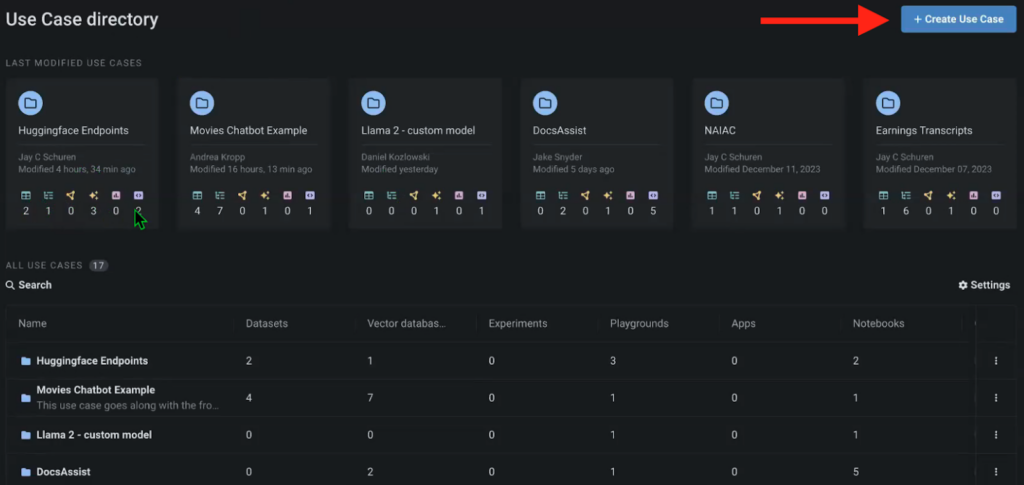
On this occasion, we’ve created a use case to experiment with numerous mannequin endpoints from HuggingFace.
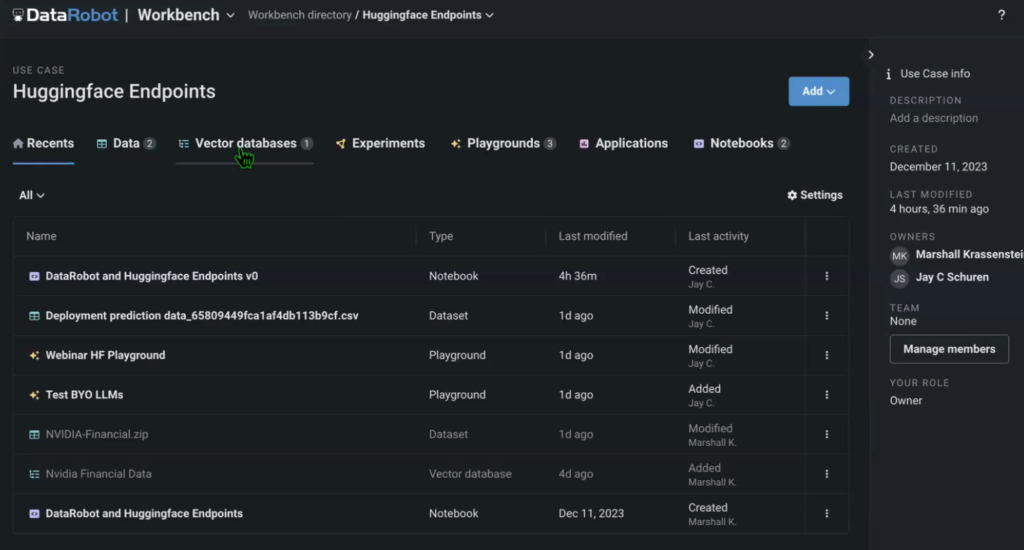
The use case additionally incorporates knowledge (on this instance, we used an NVIDIA earnings name transcript because the supply), the vector database that we created with an embedding mannequin referred to as from HuggingFace, the LLM Playground the place we’ll evaluate the fashions, in addition to the supply pocket book that runs the entire answer.
You’ll be able to construct the use case in a DataRobot Pocket book utilizing default code snippets obtainable in DataRobot and HuggingFace, as properly by importing and modifying present Jupyter notebooks.
Now that you’ve the entire supply paperwork, the vector database, the entire mannequin endpoints, it’s time to construct out the pipelines to match them within the LLM Playground.
Historically, you could possibly carry out the comparability proper within the pocket book, with outputs displaying up within the pocket book. However this expertise is suboptimal if you wish to evaluate totally different fashions and their parameters.
The LLM Playground is a UI that permits you to run a number of fashions in parallel, question them, and obtain outputs on the similar time, whereas additionally being able to tweak the mannequin settings and additional evaluate the outcomes. One other good instance for experimentation is testing out the totally different embedding fashions, as they may alter the efficiency of the answer, based mostly on the language that’s used for prompting and outputs.
This course of obfuscates loads of the steps that you simply’d need to carry out manually within the pocket book to run such complicated mannequin comparisons. The Playground additionally comes with a number of fashions by default (Open AI GPT-4, Titan, Bison, and so on.), so you could possibly evaluate your customized fashions and their efficiency towards these benchmark fashions.
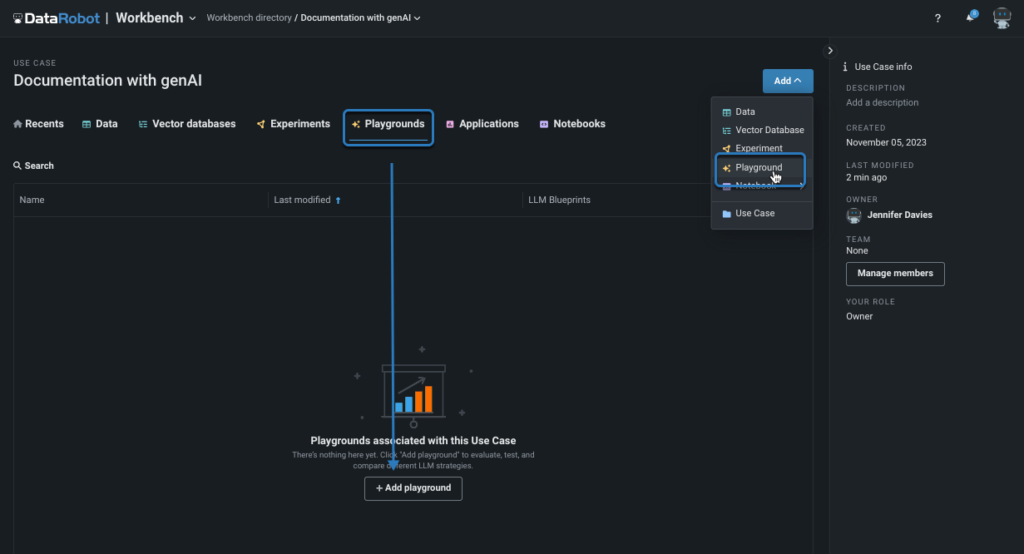
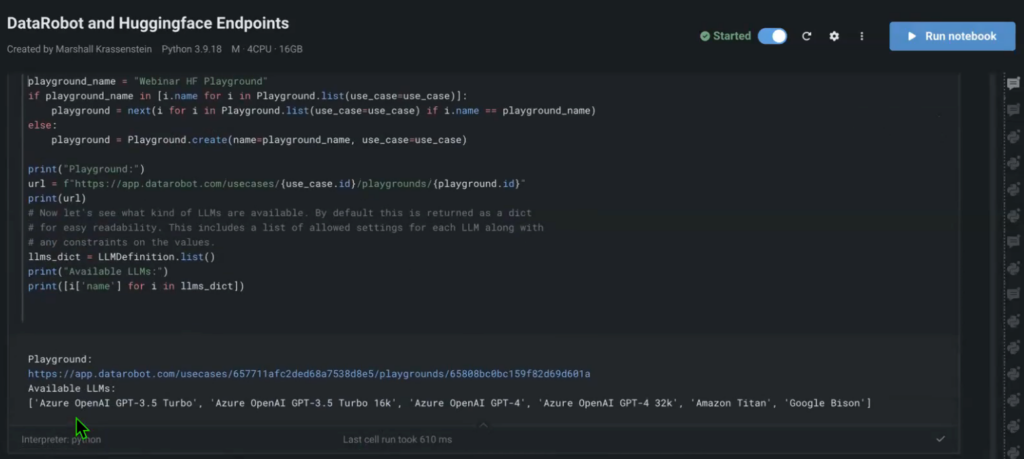
You’ll be able to add every HuggingFace endpoint to your pocket book with a couple of traces of code.
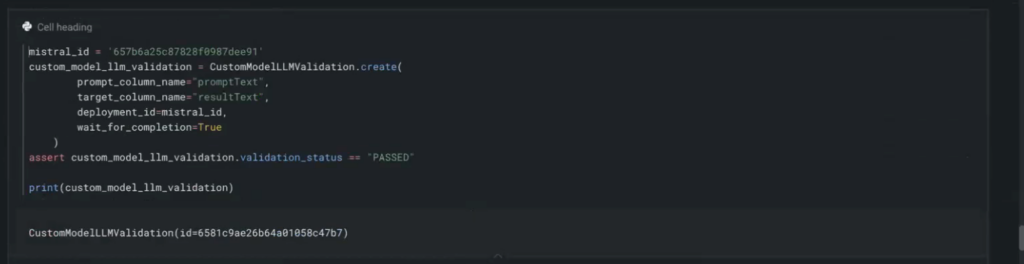
As soon as the Playground is in place and also you’ve added your HuggingFace endpoints, you’ll be able to return to the Playground, create a brand new blueprint, and add every one in all your customized HuggingFace fashions. It’s also possible to configure the System Immediate and choose the popular vector database (NVIDIA Monetary Information, on this case).
Figures 6, 7. Including and Configuring HuggingFace Endpoints in an LLM Playground
After you’ve completed this for the entire customized fashions deployed in HuggingFace, you’ll be able to correctly begin evaluating them.
Go to the Comparability menu within the Playground and choose the fashions that you simply wish to evaluate. On this case, we’re evaluating two customized fashions served by way of HuggingFace endpoints with a default Open AI GPT-3.5 Turbo mannequin.
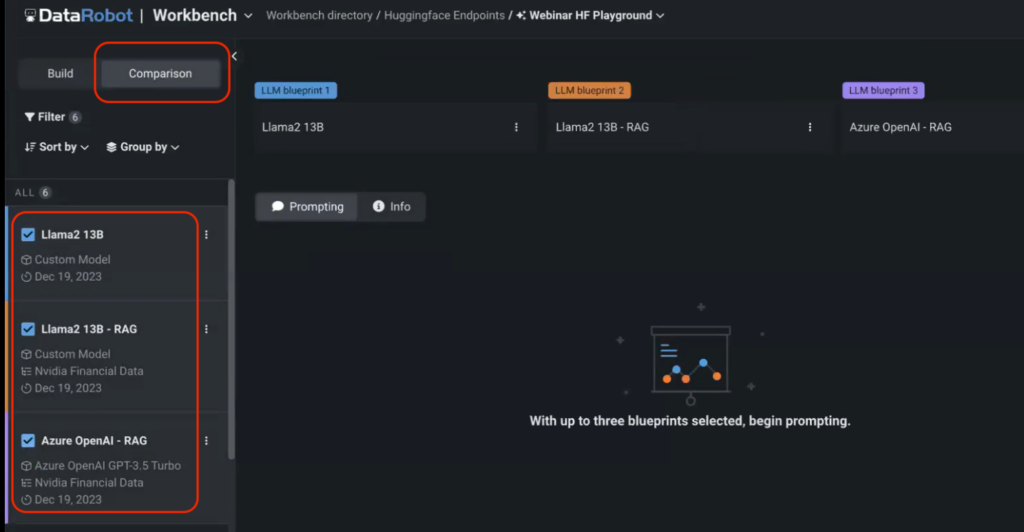
Be aware that we didn’t specify the vector database for one of many fashions to match the mannequin’s efficiency towards its RAG counterpart. You’ll be able to then begin prompting the fashions and evaluate their outputs in actual time.
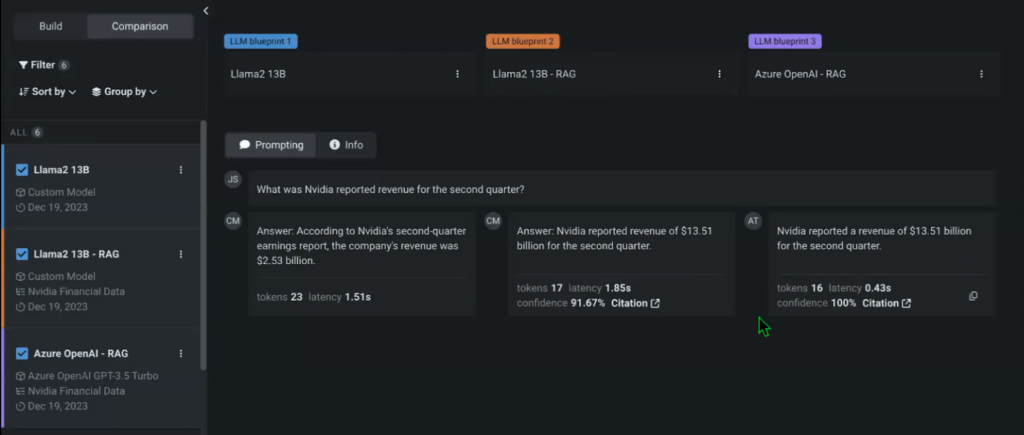
There are tons of settings and iterations which you can add to any of your experiments utilizing the Playground, together with Temperature, most restrict of completion tokens, and extra. You’ll be able to instantly see that the non-RAG mannequin that doesn’t have entry to the NVIDIA Monetary knowledge vector database supplies a distinct response that can be incorrect.
When you’re completed experimenting, you’ll be able to register the chosen mannequin within the AI Console, which is the hub for all your mannequin deployments.
The lineage of the mannequin begins as quickly because it’s registered, monitoring when it was constructed, for which function, and who constructed it. Instantly, inside the Console, you can too begin monitoring out-of-the-box metrics to watch the efficiency and add customized metrics, related to your particular use case.
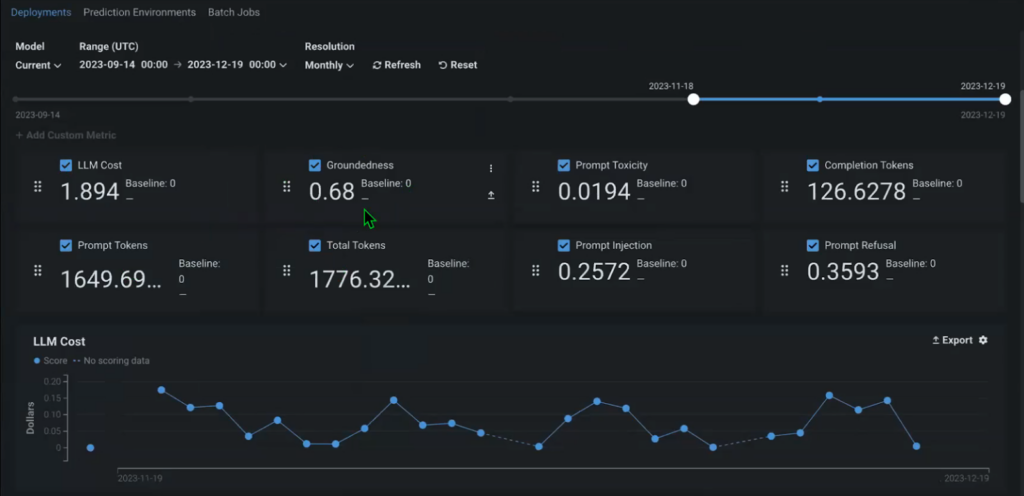
For instance, Groundedness may be an necessary long-term metric that permits you to perceive how properly the context that you simply present (your supply paperwork) suits the mannequin (what share of your supply paperwork is used to generate the reply). This lets you perceive whether or not you’re utilizing precise / related data in your answer and replace it if mandatory.
With that, you’re additionally monitoring the entire pipeline, for every query and reply, together with the context retrieved and handed on because the output of the mannequin. This additionally consists of the supply doc that every particular reply got here from.
Find out how to Select the Proper LLM for Your Use Case
General, the method of testing LLMs and determining which of them are the best match in your use case is a multifaceted endeavor that requires cautious consideration of varied components. A wide range of settings might be utilized to every LLM to drastically change its efficiency.
This underscores the significance of experimentation and steady iteration that enables to make sure the robustness and excessive effectiveness of deployed options. Solely by comprehensively testing fashions towards real-world eventualities, customers can establish potential limitations and areas for enchancment earlier than the answer is dwell in manufacturing.
A sturdy framework that mixes dwell interactions, backend configurations, and thorough monitoring is required to maximise the effectiveness and reliability of generative AI options, making certain they ship correct and related responses to person queries.
By combining the versatile library of generative AI elements in HuggingFace with an built-in strategy to mannequin experimentation and deployment in DataRobot organizations can shortly iterate and ship production-grade generative AI options prepared for the true world.
In regards to the writer

Nathaniel Daly is a Senior Product Supervisor at DataRobot specializing in AutoML and time sequence merchandise. He’s targeted on bringing advances in knowledge science to customers such that they’ll leverage this worth to unravel actual world enterprise issues. He holds a level in Arithmetic from College of California, Berkeley.

{kind=link}