

In fashionable information architectures, it’s frequent to retailer information in a number of information sources. Nevertheless, organizations embracing this strategy nonetheless want insights from their information and require applied sciences that assist them break down information silos. Amazon Athena is an interactive question service that makes it simple to research structured, unstructured, and semi-structured information saved in Amazon Easy Storage Service (Amazon S3) along with relational, non-relation, object, and customized information sources by way of its question federation capabilities. Athena is serverless, so there’s no infrastructure to handle, and also you solely pay for the queries that you simply run.
Organizations constructing a contemporary information structure need to question information in-place from purpose-built information shops with out constructing complicated extract, rework, and cargo (ETL) pipelines. Athena’s federated question characteristic permits organizations to attain this and makes it simple to:
- Create experiences and dashboards from information saved in relational, non-relational, object, and customized information sources
- Run on-demand evaluation on information unfold throughout a number of methods of document utilizing a single device and single SQL dialect
- Be a part of a number of information sources collectively to supply new enter options for machine studying mannequin coaching workflows
Nevertheless, when querying and becoming a member of enormous quantities of information from completely different information shops, it’s necessary for queries to run rapidly, at low value, and with out impacting supply methods. Predicate pushdown is supported by many question engines and is a way that may drastically scale back question processing time by filtering information on the supply early within the processing workflow. On this put up, you’ll learn the way predicate pushdown improves question efficiency and how one can validate when Athena applies predicate pushdown to federated queries.
Advantages of predicate pushdown
The important thing advantages of predicate pushdown are as follows:
- Improved question runtime
- Diminished community visitors between Athena and the info supply
- Diminished load on the distant information supply
- Diminished value ensuing from decreased information scans
Let’s discover a real-world situation to know when predicate pushdown is utilized to federated queries in Athena.
Resolution overview
Think about a hypothetical ecommerce firm with information saved in
Report counts for these tables are as follows.
| Knowledge Retailer | Desk Identify | Variety of Data | Description |
| Amazon Redshift | Catalog_Sales |
4.3 billion | Present and historic Gross sales information truth Desk |
| Amazon Redshift | Date_dim |
73,000 | Date Dimension desk |
| DynamoDB | Half |
20,000 | Realtime Elements and Stock information |
| DynamoDB | Partsupp |
80,000 | Realtime Elements and provider information |
| Aurora MySQL | Provider |
1,000 | Newest Provider transactions |
| Aurora MySQL | Buyer |
15,000 | Newest Buyer transactions |
Our requirement is to question these sources individually and be part of the info to trace pricing and provider info and evaluate latest information with historic information utilizing SQL queries with varied filters utilized. We’ll use Athena federated queries to question and be part of information from these sources to fulfill this requirement.
The next diagram depicts how Athena federated queries use information supply connectors run as Lambda capabilities to question information saved in sources aside from Amazon S3.

When a federated question is submitted in opposition to a knowledge supply, Athena invokes the info supply connector to find out how you can learn the requested desk and determine filter predicates within the WHERE clause of the question that may be pushed all the way down to the supply. Relevant filters are robotically pushed down by Athena and have the impact of omitting pointless rows early within the question processing workflow and enhancing general question execution time.
Let’s discover three use circumstances to display predicate pushdown for our ecommerce firm utilizing every of those companies.
Stipulations
As a prerequisite, evaluate Utilizing Amazon Athena Federated Question to know extra about Athena federated queries and how you can deploy these information supply connectors.
Use case 1: Amazon Redshift
In our first situation, we run an Athena federated question on Amazon Redshift by becoming a member of its Catalog_sales and Date_dim tables. We do that to indicate the variety of gross sales orders grouped by order date. The next question will get the knowledge required and takes roughly 14 seconds scanning roughly 43 MB of information:
Athena pushes the next filters to the supply for processing:
cs_sold_date_skbetween 2450815 and 2450822 for theCatalog_Salesdesk in Amazon Redshift.d_date_sk between 2450815 and 2450822;due to the be part ofl.cs_sold_date_sk=d_date_skwithin the question, theDate_dimdesk can also be filtered on the supply, and solely filtered information is moved from Amazon Redshift to Athena.
Let’s analyze the question plan by utilizing not too long ago launched visible clarify device to verify the filter predicates are pushed to the info supply:

As proven above (solely displaying the related a part of the visible clarify plan), due to the predicate pushdown, the Catalog_sales and Date_dim tables have filters utilized on the supply. Athena processes solely the ensuing filtered information.
Utilizing the Athena console, we are able to see question processing particulars utilizing the not too long ago launched question stats to interactively discover processing particulars with predicate pushdown on the question stage:

Displaying solely the related question processing phases, Catalog_sales desk has roughly 4.3 billion information, and Date_dim has roughly 73,000 information in Amazon Redshift. Solely 11 million information from the Catalog_sales (Stage 4) and eight information from the Date_dim (Stage 5) are handed from supply to Athena, as a result of the predicate pushdown pushes question filter circumstances to the info sources. This filters out unneeded information on the supply, and solely brings the required rows to Athena.
Utilizing predicate pushdown resulted in scanning 99.75% much less information from Catalog_sales and 99.99% much less information from Date_dim. This leads to a quicker question runtime and decrease value.
Use case 2: Amazon Redshift and Aurora MySQL
In our second use case, we run an Athena federated question on Aurora MySQL and Amazon Redshift information shops. This question joins the Catalog_sales and Date_dim tables in Amazon Redshift with the Buyer desk within the Aurora MySQL database to get the overall variety of orders with the overall quantity spent by every buyer for the primary week in January 1998 for the market section of AUTOMOBILE. The next question will get the knowledge required and takes roughly 35 seconds scanning roughly 337 MB of information:
Athena pushes the next filters to the info sources for processing:
cs_sold_date_sk between 2450815 and 2450822for theCatalog_Salesdesk in Amazon Redshift.d_date_sk between 2450815 and 2450822;due to the be part ofl.cs_sold_date_sk=d_date_skwithin the question, theDate_dimdesk can also be filtered on the supply (Amazon Redshift) and solely filtered information is moved from Amazon Redshift to Athena.c_mktsegment="AUTOMOBILE"for theBuyerdesk within the Aurora MySQL database.
Now let’s seek the advice of the visible clarify plan for this question to indicate the predicate pushdown to the supply for processing:
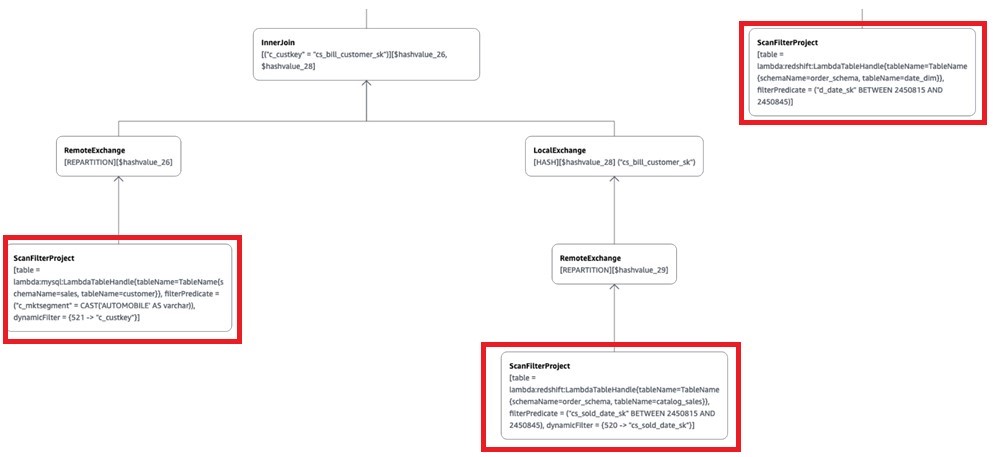
As proven above (solely displaying the related a part of the visible clarify plan), due to the predicate pushdown, Catalog_sales and Date_dim have the question filter utilized on the supply (Amazon Redshift), and the buyer desk has the market section AUTOMOBILE filter utilized on the supply (Aurora MySQL). This brings solely the filtered information to Athena.
As earlier than, we are able to see question processing particulars utilizing the not too long ago launched question stats to interactively discover processing particulars with predicate pushdown on the question stage:
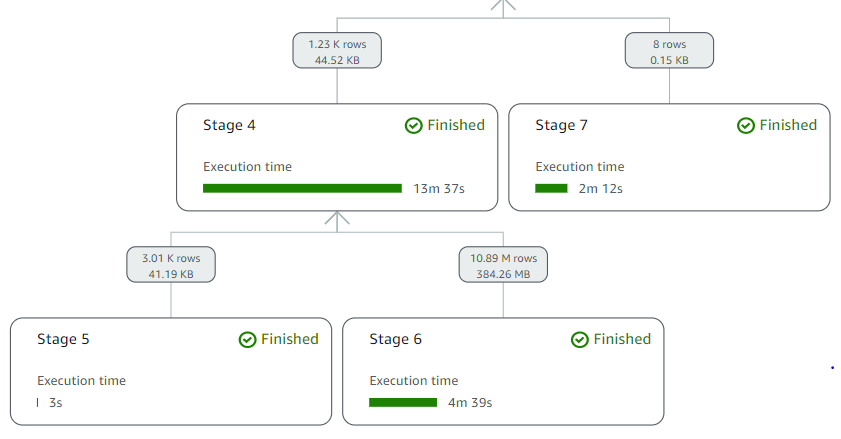
Displaying solely the related question processing phases, Catalog_sales has 4.3 billion information, Date_Dim has 73,000 information in Amazon Redshift, and Buyer has 15,000 information in Aurora MySQL. Solely 11 million information from Catalog_sales (Stage 6), 8 information from Date_dim (Stage 7), and three,000 information from Buyer (Stage 5) are handed from the respective sources to Athena as a result of the predicate pushdown pushes question filter circumstances to the info sources. This filters out unneeded information on the supply and solely brings the required rows to Athena.
Right here, predicate pushdown resulted in scanning 99.75% much less information from Catalog_sales, 99.99% much less information from Date_dim, and 79.91% from Buyer. Moreover, this leads to a quicker question runtime and decreased value.
Use case 3: Amazon Redshift, Aurora MySQL, and DynamoDB
For our third use case, we run an Athena federated question on Aurora MySQL, Amazon Redshift, and DynamoDB information shops. This question joins the Half and Partsupp tables in DynamoDB, the Catalog_sales and Date_dim tables in Amazon Redshift, and the Provider and Buyer tables in Aurora MySQL to get the portions accessible at every provider for orders with the very best income through the first week of January 1998 for the market section of AUTOMOBILE and elements manufactured by Producer#1.
The next question will get the knowledge required and takes roughly 33 seconds scanning roughly 428 MB of information in Athena:
Athena pushes the next filters to the info sources for processing:
cs_sold_date_sk between 2450815 and 2450822for theCatalog_Salesdesk in Amazon Redshift.d_date_sk between 2450815 and 2450822;due to the be part ofl.cs_sold_date_sk=d_date_skwithin the question, theDate_dimdesk can also be filtered on the supply and solely filtered information is moved from Amazon Redshift to Athena.c_mktsegment="AUTOMOBILE"for theBuyerdesk within the Aurora MySQL database.p.p_mfgr="Producer#1"for theHalfdesk in DynamoDB.
Now let’s run the clarify plan for this question to verify predicates are pushed all the way down to the supply for processing:
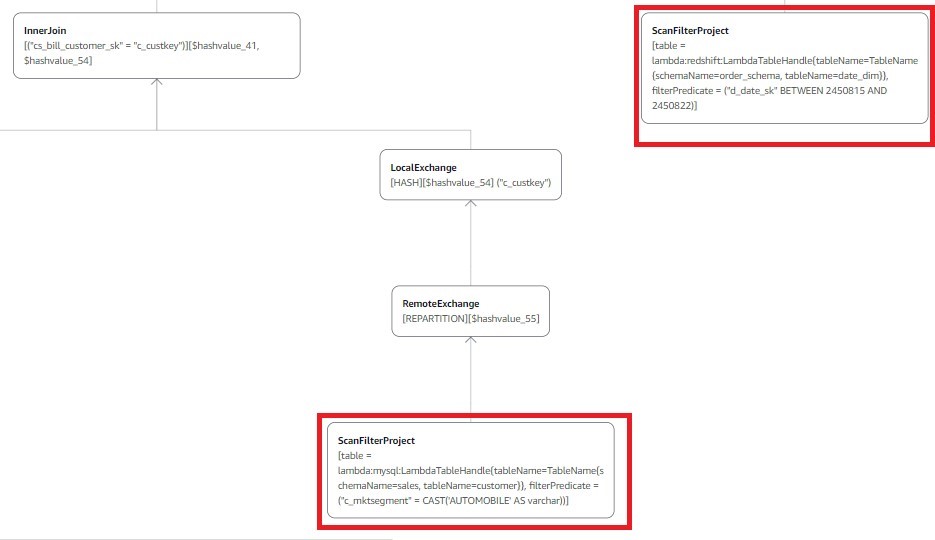

As proven above (displaying solely the related a part of the plan), due to the predicate pushdown, Catalog_sales and Date_dim have the question filter utilized on the supply (Amazon Redshift), the Buyer desk has the market section AUTOMOBILE filter utilized on the supply (Aurora MySQL), and the Half desk has the half manufactured by Producer#1 filter utilized on the supply (DynamoDB).
We are able to analyze question processing particulars utilizing the not too long ago launched question stats to interactively discover processing particulars with predicate pushdown on the question stage:

Displaying solely the related processing phases, Catalog_sales has 4.3 billion information, Date_Dim has 73,000 information in Amazon Redshift, Buyer has 15,000 information in Aurora MySQL, and Half has 20,000 information in DynamoDB. Solely 11 million information from Catalog_sales (Stage 5), 8 information from Date_dim (Stage 9), 3,000 information from Buyer (Stage 8), and 4,000 information from Half (Stage 4) are handed from their respective sources to Athena, as a result of the predicate pushdown pushes question filter circumstances to the info sources. This filters out unneeded information on the supply, and solely brings the required rows from the sources to Athena.
Issues for predicate pushdown
When utilizing Athena to question your information sources, think about the next:
- Relying on the info supply, information supply connector, and question complexity, Athena can push filter predicates to the supply for processing. The next are among the sources Athena helps predicate pushdown with:
- Athena additionally performs predicate pushdown on information saved in an S3 information lake. And, with predicate pushdown for supported sources, you possibly can be part of all of your information sources in a single question and obtain quick question efficiency.
- You need to use the not too long ago launched question stats in addition to EXPLAIN and EXPLAIN ANALYZE in your queries to verify predicates are pushed all the way down to the supply.
- Queries might not have predicates pushed to the supply if the question’s WHERE clause makes use of Athena-specific capabilities (for instance,
WHERE log2(col)<10).
Conclusion
On this put up, we demonstrated three federated question situations on Aurora MySQL, Amazon Redshift, and DynamoDB to indicate how predicate pushdown improves federated question efficiency and reduces value and how one can validate when predicate pushdown happens. If the federated information supply helps parallel scans, then predicate pushdown makes it doable to attain efficiency that’s near the efficiency of Athena queries on information saved in Amazon S3. You may make the most of the patterns and proposals outlined on this put up when querying supported information sources to enhance general question efficiency and decrease information scanned.
In regards to the authors
 Rohit Bansal is an Analytics Specialist Options Architect at AWS. He has practically twenty years of expertise serving to clients modernize their information platforms. He’s enthusiastic about serving to clients construct scalable, cost-effective information and analytics options within the cloud. In his spare time, he enjoys spending time along with his household, journey, and street biking.
Rohit Bansal is an Analytics Specialist Options Architect at AWS. He has practically twenty years of expertise serving to clients modernize their information platforms. He’s enthusiastic about serving to clients construct scalable, cost-effective information and analytics options within the cloud. In his spare time, he enjoys spending time along with his household, journey, and street biking.
 Ruchir Tripathi is a Senior Analytics Options Architect aligned to International Monetary Companies at AWS. He’s enthusiastic about serving to enterprises construct scalable, performant, and cost-effective options within the cloud. Previous to becoming a member of AWS, Ruchir labored with main monetary establishments and relies out of New York Workplace.
Ruchir Tripathi is a Senior Analytics Options Architect aligned to International Monetary Companies at AWS. He’s enthusiastic about serving to enterprises construct scalable, performant, and cost-effective options within the cloud. Previous to becoming a member of AWS, Ruchir labored with main monetary establishments and relies out of New York Workplace.

{kind=link}