
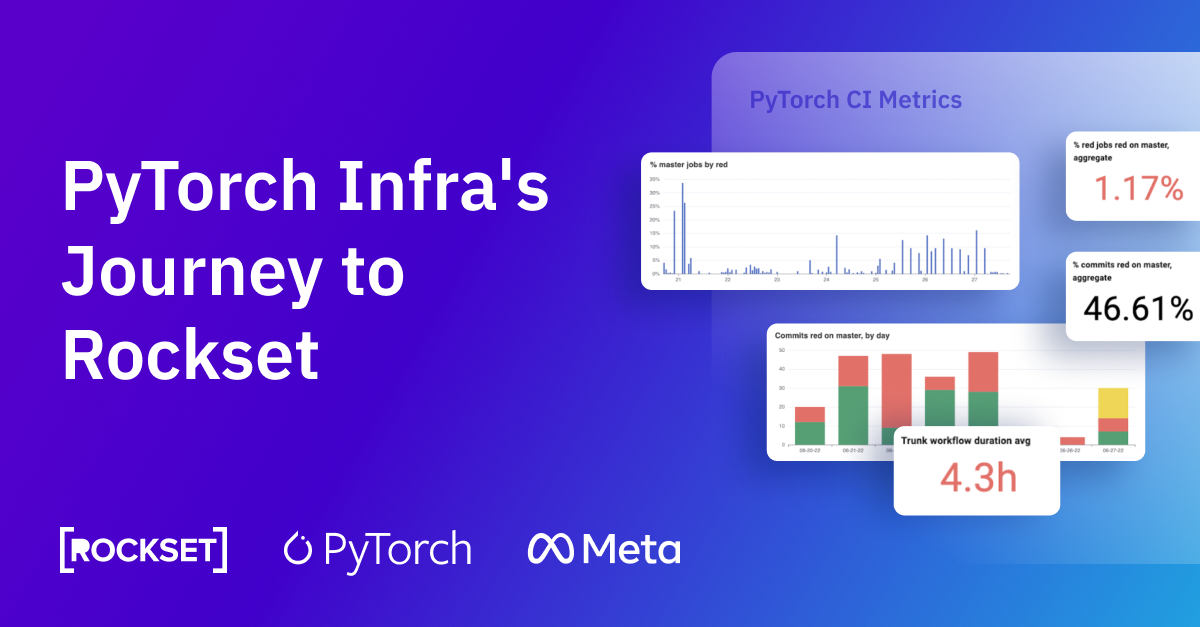
Open supply PyTorch runs tens of 1000’s of checks on a number of platforms and compilers to validate each change as our CI (Steady Integration). We observe stats on our CI system to energy
- customized infrastructure, corresponding to dynamically sharding check jobs throughout completely different machines
- developer-facing dashboards, see hud.pytorch.org, to trace the greenness of each change
- metrics, see hud.pytorch.org/metrics, to trace the well being of our CI by way of reliability and time-to-signal

Our necessities for a knowledge backend
These CI stats and dashboards serve 1000’s of contributors, from corporations corresponding to Google, Microsoft and NVIDIA, offering them precious info on PyTorch’s very advanced check suite. Consequently, we wanted a knowledge backend with the next traits:
What did we use earlier than Rockset?

Inside storage from Meta (Scuba)
TL;DR
- Professionals: scalable + quick to question
- Con: not publicly accessible! We couldn’t expose our instruments and dashboards to customers despite the fact that the info we have been internet hosting was not delicate.
As many people work at Meta, utilizing an already-built, feature-full information backend was the answer, particularly when there weren’t many PyTorch maintainers and positively no devoted Dev Infra staff. With assist from the Open Supply staff at Meta, we arrange information pipelines for our many check circumstances and all of the GitHub webhooks we might care about. Scuba allowed us to retailer no matter we happy (since our scale is principally nothing in comparison with Fb scale), interactively slice and cube the info in actual time (no must study SQL!), and required minimal upkeep from us (since another inside staff was combating its fires).
It seems like a dream till you do not forget that PyTorch is an open supply library! All the info we have been accumulating was not delicate, but we couldn’t share it with the world as a result of it was hosted internally. Our fine-grained dashboards have been seen internally solely and the instruments we wrote on prime of this information couldn’t be externalized.
For instance, again within the outdated days, after we have been trying to trace Home windows “smoke checks”, or check circumstances that appear extra prone to fail on Home windows solely (and never on some other platform), we wrote an inside question to symbolize the set. The concept was to run this smaller subset of checks on Home windows jobs throughout growth on pull requests, since Home windows GPUs are costly and we needed to keep away from working checks that wouldn’t give us as a lot sign. Because the question was inside however the outcomes have been used externally, we got here up with the hacky answer of: Jane will simply run the interior question infrequently and manually replace the outcomes externally. As you’ll be able to think about, it was liable to human error and inconsistencies because it was straightforward to make exterior modifications (like renaming some jobs) and neglect to replace the interior question that just one engineer was .
Compressed JSONs in an S3 bucket
TL;DR
- Professionals: form of scalable + publicly accessible
- Con: terrible to question + not really scalable!
Sooner or later in 2020, we determined that we have been going to publicly report our check instances for the aim of monitoring check historical past, reporting check time regressions, and computerized sharding. We went with S3, because it was pretty light-weight to jot down and browse from it, however extra importantly, it was publicly accessible!
We handled the scalability drawback early on. Since writing 10000 paperwork to S3 wasn’t (and nonetheless isn’t) an excellent choice (it might be tremendous gradual), we had aggregated check stats right into a JSON, then compressed the JSON, then submitted it to S3. Once we wanted to learn the stats, we’d go within the reverse order and doubtlessly do completely different aggregations for our numerous instruments.
The truth is, since sharding was a use case that solely got here up later within the structure of this information, we realized just a few months after stats had already been piling up that we must always have been monitoring check filename info. We rewrote our whole JSON logic to accommodate sharding by check file–if you wish to see how messy that was, take a look at the category definitions on this file.


I flippantly chuckle at this time that this code has supported us the previous 2 years and is nonetheless supporting our present sharding infrastructure. The chuckle is simply gentle as a result of despite the fact that this answer appears jank, it labored nice for the use circumstances we had in thoughts again then: sharding by file, categorizing gradual checks, and a script to see check case historical past. It grew to become an even bigger drawback after we began wanting extra (shock shock). We needed to check out Home windows smoke checks (the identical ones from the final part) and flaky check monitoring, which each required extra advanced queries on check circumstances throughout completely different jobs on completely different commits from extra than simply the previous day. The scalability drawback now actually hit us. Keep in mind all of the decompressing and de-aggregating and re-aggregating that was taking place for each JSON? We’d have had to try this massaging for doubtlessly tons of of 1000’s of JSONs. Therefore, as a substitute of going additional down this path, we opted for a special answer that might permit simpler querying–Amazon RDS.
Amazon RDS
TL;DR
- Professionals: scale, publicly accessible, quick to question
- Con: greater upkeep prices
Amazon RDS was the pure publicly out there database answer as we weren’t conscious of Rockset on the time. To cowl our rising necessities, we put in a number of weeks of effort to arrange our RDS occasion and created a number of AWS Lambdas to assist the database, silently accepting the rising upkeep price. With RDS, we have been in a position to begin internet hosting public dashboards of our metrics (like check redness and flakiness) on Grafana, which was a serious win!
Life With Rockset
We most likely would have continued with RDS for a few years and eaten up the price of operations as a necessity, however certainly one of our engineers (Michael) determined to “go rogue” and check out Rockset close to the tip of 2021. The concept of “if it ain’t broke, don’t repair it,” was within the air, and most of us didn’t see rapid worth on this endeavor. Michael insisted that minimizing upkeep price was essential particularly for a small staff of engineers, and he was proper! It’s often simpler to think about an additive answer, corresponding to “let’s simply construct yet another factor to alleviate this ache”, however it’s often higher to go together with a subtractive answer if out there, corresponding to “let’s simply take away the ache!”
The outcomes of this endeavor have been shortly evident: Michael was in a position to arrange Rockset and replicate the primary elements of our earlier dashboard in below 2 weeks! Rockset met all of our necessities AND was much less of a ache to take care of!

Whereas the primary 3 necessities have been constantly met by different information backend options, the “no-ops setup and upkeep” requirement was the place Rockset gained by a landslide. Apart from being a very managed answer and assembly the necessities we have been in search of in a knowledge backend, utilizing Rockset introduced a number of different advantages.
-
Schemaless ingest
- We do not have to schematize the info beforehand. Virtually all our information is JSON and it’s totally useful to have the ability to write the whole lot immediately into Rockset and question the info as is.
- This has elevated the speed of growth. We are able to add new options and information simply, with out having to do additional work to make the whole lot constant.
-
Actual-time information
- We ended up shifting away from S3 as our information supply and now use Rockset’s native connector to sync our CI stats from DynamoDB.
Rockset has proved to satisfy our necessities with its capacity to scale, exist as an open and accessible cloud service, and question huge datasets shortly. Importing 10 million paperwork each hour is now the norm, and it comes with out sacrificing querying capabilities. Our metrics and dashboards have been consolidated into one HUD with one backend, and we will now take away the pointless complexities of RDS with AWS Lambdas and self-hosted servers. We talked about Scuba (inside to Meta) earlier and we discovered that Rockset may be very very similar to Scuba however hosted on the general public cloud!
What Subsequent?
We’re excited to retire our outdated infrastructure and consolidate much more of our instruments to make use of a standard information backend. We’re much more excited to search out out what new instruments we might construct with Rockset.
This visitor publish was authored by Jane Xu and Michael Suo, who’re each software program engineers at Fb.

{kind=link}